 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge1st Workshop on Maritime Computer Vision 2023: Challenge Results
Nov 28, 2022

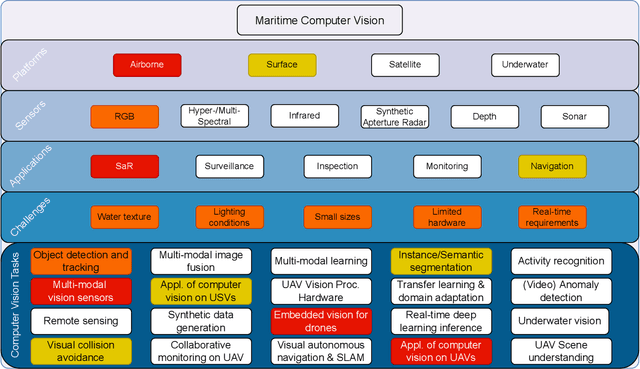
The 1$^{\text{st}}$ Workshop on Maritime Computer Vision (MaCVi) 2023 focused on maritime computer vision for Unmanned Aerial Vehicles (UAV) and Unmanned Surface Vehicle (USV), and organized several subchallenges in this domain: (i) UAV-based Maritime Object Detection, (ii) UAV-based Maritime Object Tracking, (iii) USV-based Maritime Obstacle Segmentation and (iv) USV-based Maritime Obstacle Detection. The subchallenges were based on the SeaDronesSee and MODS benchmarks. This report summarizes the main findings of the individual subchallenges and introduces a new benchmark, called SeaDronesSee Object Detection v2, which extends the previous benchmark by including more classes and footage. We provide statistical and qualitative analyses, and assess trends in the best-performing methodologies of over 130 submissions. The methods are summarized in the appendix. The datasets, evaluation code and the leaderboard are publicly available at https://seadronessee.cs.uni-tuebingen.de/macvi.
Modeling Electrical Motor Dynamics using Encoder-Decoder with Recurrent Skip Connection
Oct 08, 2020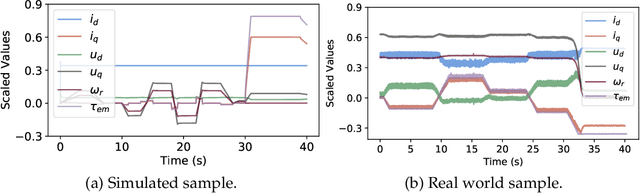

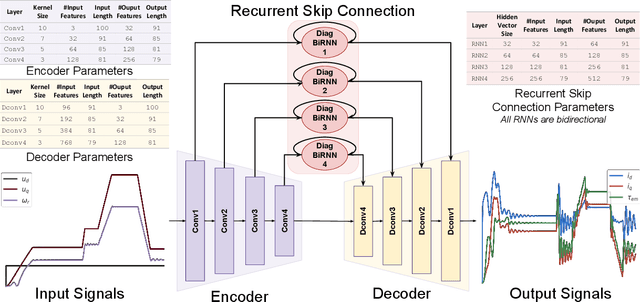
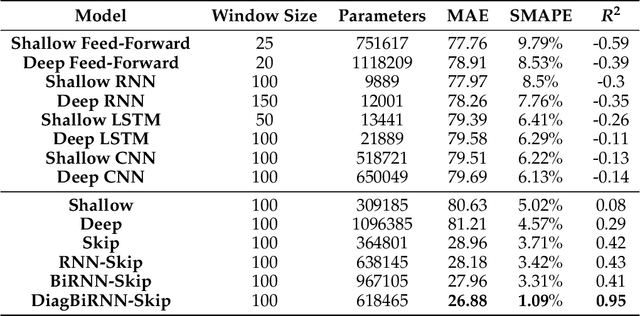
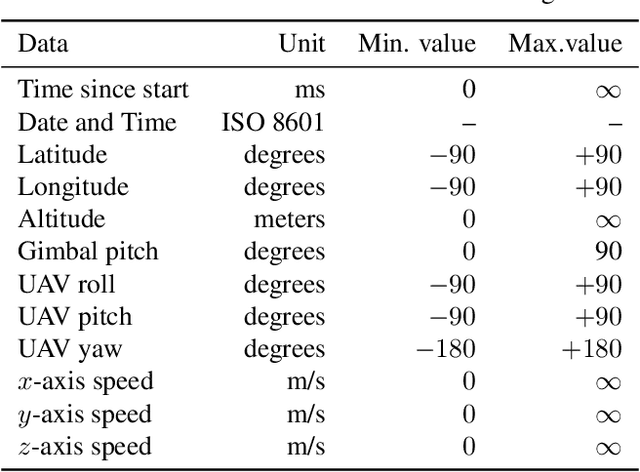
Electrical motors are the most important source of mechanical energy in the industrial world. Their modeling traditionally relies on a physics-based approach, which aims at taking their complex internal dynamics into account. In this paper, we explore the feasibility of modeling the dynamics of an electrical motor by following a data-driven approach, which uses only its inputs and outputs and does not make any assumption on its internal behaviour. We propose a novel encoder-decoder architecture which benefits from recurrent skip connections. We also propose a novel loss function that takes into account the complexity of electrical motor quantities and helps in avoiding model bias. We show that the proposed architecture can achieve a good learning performance on our high-frequency high-variance datasets. Two datasets are considered: the first one is generated using a simulator based on the physics of an induction motor and the second one is recorded from an industrial electrical motor. We benchmark our solution using variants of traditional neural networks like feedforward, convolutional, and recurrent networks. We evaluate various design choices of our architecture and compare it to the baselines. We show the domain adaptation capability of our model to learn dynamics just from simulated data by testing it on the raw sensor data. We finally show the effect of signal complexity on the proposed method ability to model temporal dynamics.
A Survey on Machine Learning Applied to Dynamic Physical Systems
Sep 28, 2020This survey is on recent advancements in the intersection of physical modeling and machine learning. We focus on the modeling of nonlinear systems which are closer to electric motors. Survey on motor control and fault detection in operation of electric motors has been done.
Diversity in Fashion Recommendation using Semantic Parsing
Oct 18, 2019
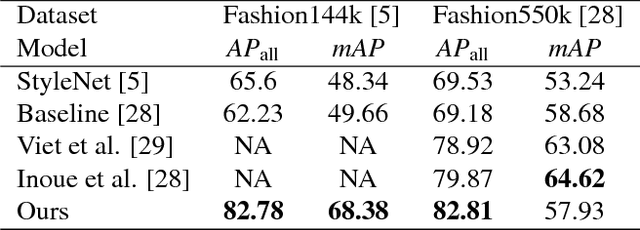
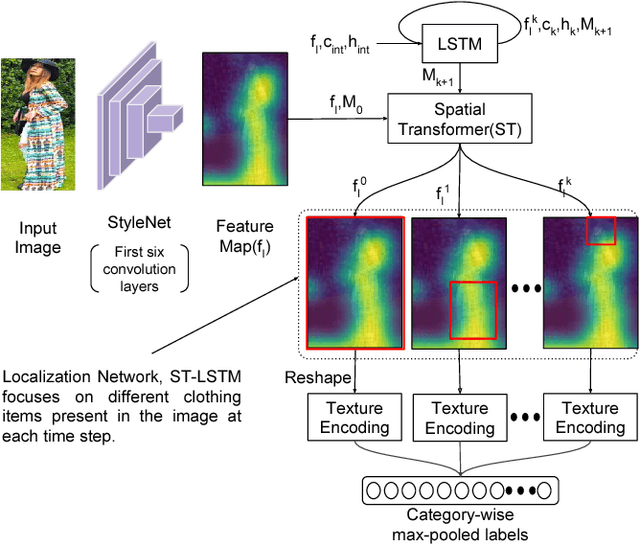

Developing recommendation system for fashion images is challenging due to the inherent ambiguity associated with what criterion a user is looking at. Suggesting multiple images where each output image is similar to the query image on the basis of a different feature or part is one way to mitigate the problem. Existing works for fashion recommendation have used Siamese or Triplet network to learn features between a similar pair and a similar-dissimilar triplet respectively. However, these methods do not provide basic information such as, how two clothing images are similar, or which parts present in the two images make them similar. In this paper, we propose to recommend images by explicitly learning and exploiting part based similarity. We propose a novel approach of learning discriminative features from weakly-supervised data by using visual attention over the parts and a texture encoding network. We show that the learned features surpass the state-of-the-art in retrieval task on DeepFashion dataset. We then use the proposed model to recommend fashion images having an explicit variation with respect to similarity of any of the parts.
Multi Label Restricted Boltzmann Machine for Non-Intrusive Load Monitoring
Oct 17, 2019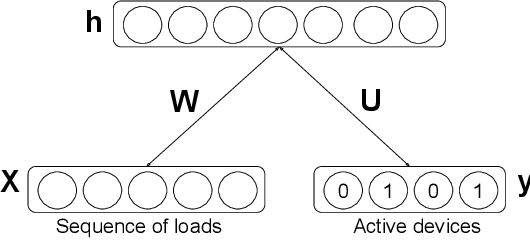
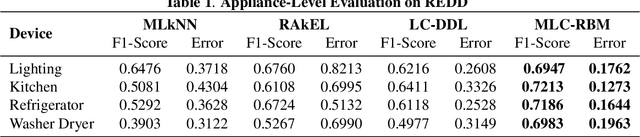
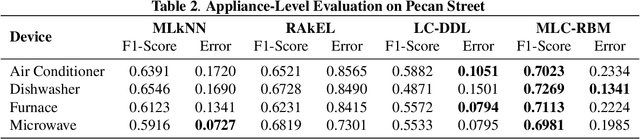
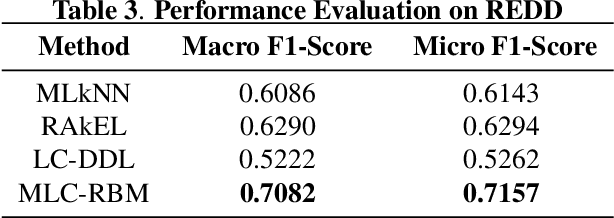
Increasing population indicates that energy demands need to be managed in the residential sector. Prior studies have reflected that the customers tend to reduce a significant amount of energy consumption if they are provided with appliance-level feedback. This observation has increased the relevance of load monitoring in today's tech-savvy world. Most of the previously proposed solutions claim to perform load monitoring without intrusion, but they are not completely non-intrusive. These methods require historical appliance-level data for training the model for each of the devices. This data is gathered by putting a sensor on each of the appliances present in the home which causes intrusion in the building. Some recent studies have proposed that if we frame Non-Intrusive Load Monitoring (NILM) as a multi-label classification problem, the need for appliance-level data can be avoided. In this paper, we propose Multi-label Restricted Boltzmann Machine(ML-RBM) for NILM and report an experimental evaluation of proposed and state-of-the-art techniques.
MAPEL: Multi-Agent Pursuer-Evader Learning using Situation Report
Oct 17, 2019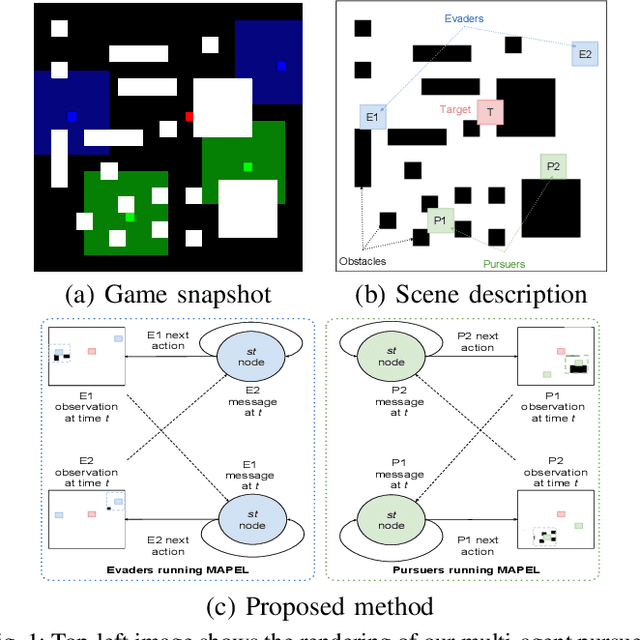
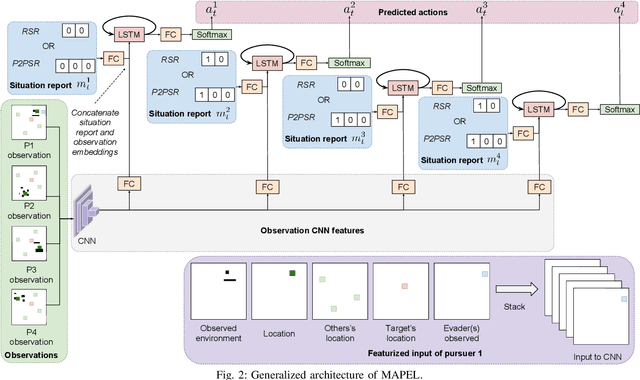
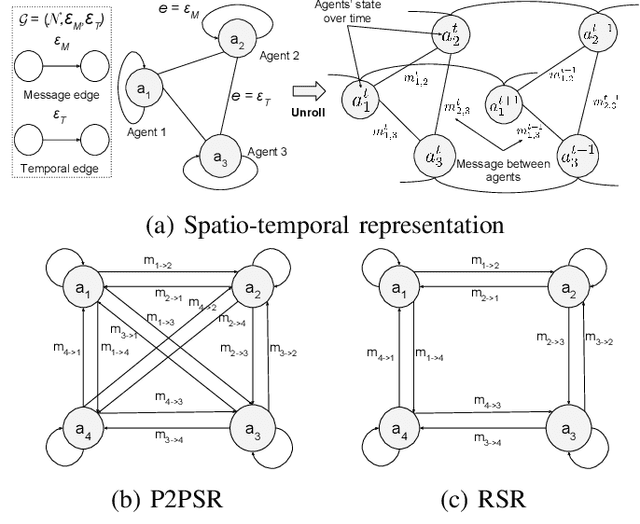
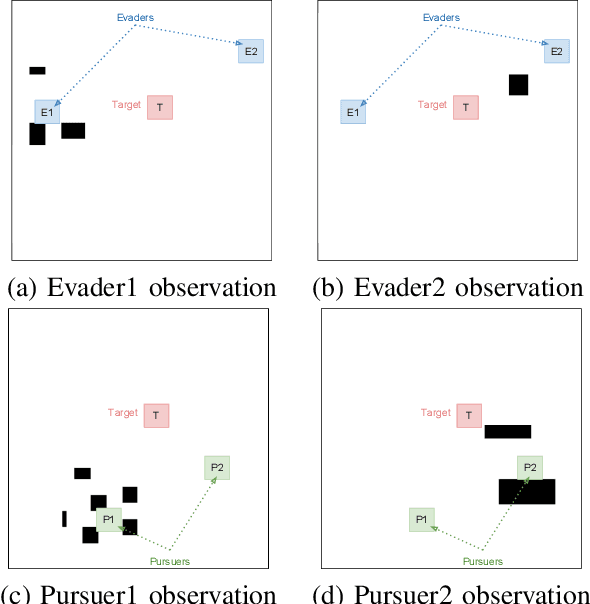
In this paper, we consider a territory guarding game involving pursuers, evaders and a target in an environment that contains obstacles. The goal of the evaders is to capture the target, while that of the pursuers is to capture the evaders before they reach the target. All the agents have limited sensing range and can only detect each other when they are in their observation space. We focus on the challenge of effective cooperation between agents of a team. Finding exact solutions for such multi-agent systems is difficult because of the inherent complexity. We present Multi-Agent Pursuer-Evader Learning (MAPEL), a class of algorithms that use spatio-temporal graph representation to learn structured cooperation. The key concept is that the learning takes place in a decentralized manner and agents use situation report updates to learn about the whole environment from each others' partial observations. We use Recurrent Neural Networks (RNNs) to parameterize the spatio-temporal graph. An agent in MAPEL only updates all the other agents if an opponent or the target is inside its observation space by using situation report. We present two methods for cooperation via situation report update: a) Peer-to-Peer Situation Report (P2PSR) and b) Ring Situation Report (RSR). We present a detailed analysis of how these two cooperation methods perform when the number of agents in the game are increased. We provide empirical results to show how agents cooperate under these two methods.
Detecting Urban Changes with Recurrent Neural Networks from Multitemporal Sentinel-2 Data
Oct 17, 2019

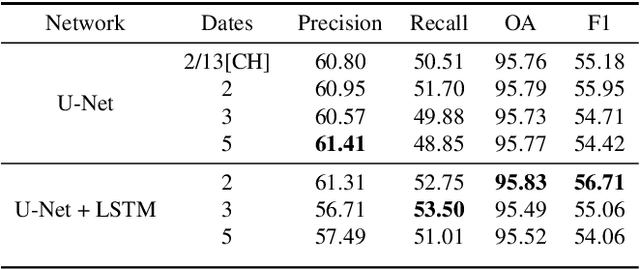

\begin{abstract} The advent of multitemporal high resolution data, like the Copernicus Sentinel-2, has enhanced significantly the potential of monitoring the earth's surface and environmental dynamics. In this paper, we present a novel deep learning framework for urban change detection which combines state-of-the-art fully convolutional networks (similar to U-Net) for feature representation and powerful recurrent networks (such as LSTMs) for temporal modeling. We report our results on the recently publicly available bi-temporal Onera Satellite Change Detection (OSCD) Sentinel-2 dataset, enhancing the temporal information with additional images of the same region on different dates. Moreover, we evaluate the performance of the recurrent networks as well as the use of the additional dates on the unseen test-set using an ensemble cross-validation strategy. All the developed models during the validation phase have scored an overall accuracy of more than 95%, while the use of LSTMs and further temporal information, boost the F1 rate of the change class by an additional 1.5%.
Making Third Person Techniques Recognize First-Person Actions in Egocentric Videos
Oct 17, 2019
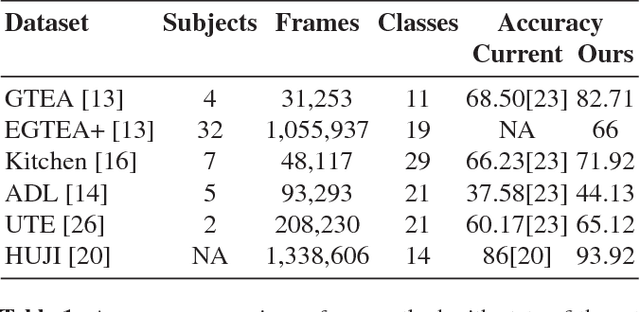
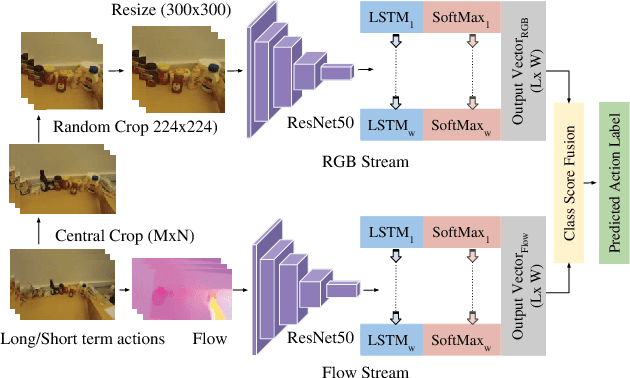
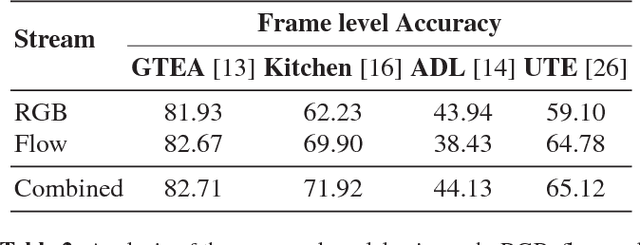
We focus on first-person action recognition from egocentric videos. Unlike third person domain, researchers have divided first-person actions into two categories: involving hand-object interactions and the ones without, and developed separate techniques for the two action categories. Further, it has been argued that traditional cues used for third person action recognition do not suffice, and egocentric specific features, such as head motion and handled objects have been used for such actions. Unlike the state-of-the-art approaches, we show that a regular two stream Convolutional Neural Network (CNN) with Long Short-Term Memory (LSTM) architecture, having separate streams for objects and motion, can generalize to all categories of first-person actions. The proposed approach unifies the feature learned by all action categories, making the proposed architecture much more practical. In an important observation, we note that the size of the objects visible in the egocentric videos is much smaller. We show that the performance of the proposed model improves after cropping and resizing frames to make the size of objects comparable to the size of ImageNet's objects. Our experiments on the standard datasets: GTEA, EGTEA Gaze+, HUJI, ADL, UTE, and Kitchen, proves that our model significantly outperforms various state-of-the-art techniques.
Collaborative Filtering with Label Consistent Restricted Boltzmann Machine
Oct 17, 2019



The possibility of employing restricted Boltzmann machine (RBM) for collaborative filtering has been known for about a decade. However, there has been hardly any work on this topic since 2007. This work revisits the application of RBM in recommender systems. RBM based collaborative filtering only used the rating information; this is an unsupervised architecture. This work adds supervision by exploiting user demographic information and item metadata. A network is learned from the representation layer to the labels (metadata). The proposed label consistent RBM formulation improves significantly on the existing RBM based approach and yield results at par with the state-of-the-art latent factor based models.