 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat really matters for person re-identification? A Mixture-of-Experts Framework for Semantic Attribute Importance
Dec 09, 2025State-of-the-art person re-identification methods achieve impressive accuracy but remain largely opaque, leaving open the question: which high-level semantic attributes do these models actually rely on? We propose MoSAIC-ReID, a Mixture-of-Experts framework that systematically quantifies the importance of pedestrian attributes for re-identification. Our approach uses LoRA-based experts, each linked to a single attribute, and an oracle router that enables controlled attribution analysis. While MoSAIC-ReID achieves competitive performance on Market-1501 and DukeMTMC under the assumption that attribute annotations are available at test time, its primary value lies in providing a large-scale, quantitative study of attribute importance across intrinsic and extrinsic cues. Using generalized linear models, statistical tests, and feature-importance analyses, we reveal which attributes, such as clothing colors and intrinsic characteristics, contribute most strongly, while infrequent cues (e.g. accessories) have limited effect. This work offers a principled framework for interpretable ReID and highlights the requirements for integrating explicit semantic knowledge in practice. Code is available at https://github.com/psaltaath/MoSAIC-ReID
Attention, Please! Revisiting Attentive Probing for Masked Image Modeling
Jun 11, 2025As fine-tuning (FT) becomes increasingly impractical at scale, probing is emerging as the preferred evaluation protocol for self-supervised learning (SSL). Yet, the standard linear probing (LP) fails to adequately reflect the potential of models trained with Masked Image Modeling (MIM), due to the distributed nature of patch tokens. This motivates the need for attentive probing, an alternative that uses attention to selectively aggregate patch-level features. Despite its growing adoption, attentive probing remains under-explored, with existing methods suffering from excessive parameterization and poor computational efficiency. In this work, we revisit attentive probing through the lens of the accuracy-efficiency trade-off. We conduct a systematic study of existing methods, analyzing their mechanisms and benchmarking their performance. We introduce efficient probing (EP), a multi-query cross-attention mechanism that eliminates redundant projections, reduces the number of trainable parameters, and achieves up to a 10$\times$ speed-up over conventional multi-head attention. Despite its simplicity, EP outperforms LP and prior attentive probing approaches across seven benchmarks, generalizes well beyond MIM to diverse pre-training paradigms, produces interpretable attention maps, and achieves strong gains in low-shot and layer-wise settings. Code available at https://github.com/billpsomas/efficient-probing.
Skin Lesion Phenotyping via Nested Multi-modal Contrastive Learning
May 29, 2025We introduce SLIMP (Skin Lesion Image-Metadata Pre-training) for learning rich representations of skin lesions through a novel nested contrastive learning approach that captures complex relationships between images and metadata. Melanoma detection and skin lesion classification based solely on images, pose significant challenges due to large variations in imaging conditions (lighting, color, resolution, distance, etc.) and lack of clinical and phenotypical context. Clinicians typically follow a holistic approach for assessing the risk level of the patient and for deciding which lesions may be malignant and need to be excised, by considering the patient's medical history as well as the appearance of other lesions of the patient. Inspired by this, SLIMP combines the appearance and the metadata of individual skin lesions with patient-level metadata relating to their medical record and other clinically relevant information. By fully exploiting all available data modalities throughout the learning process, the proposed pre-training strategy improves performance compared to other pre-training strategies on downstream skin lesions classification tasks highlighting the learned representations quality.
Composed Image Retrieval for Training-Free Domain Conversion
Dec 04, 2024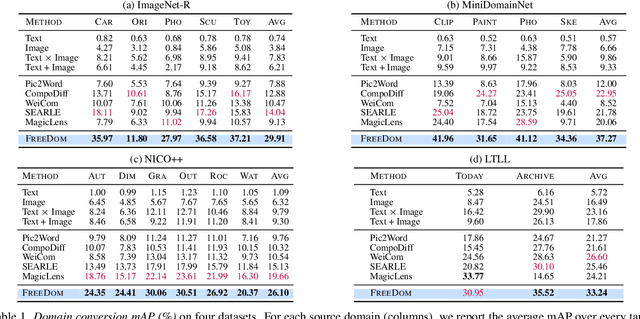
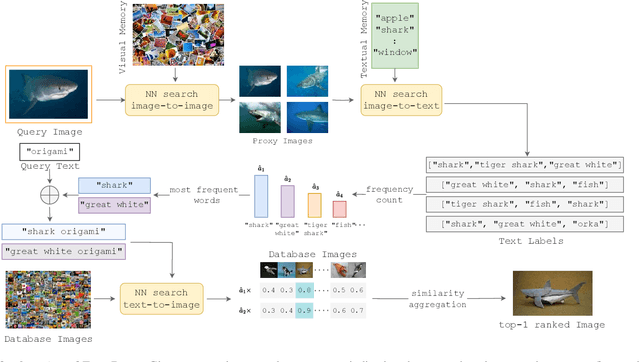


This work addresses composed image retrieval in the context of domain conversion, where the content of a query image is retrieved in the domain specified by the query text. We show that a strong vision-language model provides sufficient descriptive power without additional training. The query image is mapped to the text input space using textual inversion. Unlike common practice that invert in the continuous space of text tokens, we use the discrete word space via a nearest-neighbor search in a text vocabulary. With this inversion, the image is softly mapped across the vocabulary and is made more robust using retrieval-based augmentation. Database images are retrieved by a weighted ensemble of text queries combining mapped words with the domain text. Our method outperforms prior art by a large margin on standard and newly introduced benchmarks. Code: https://github.com/NikosEfth/freedom
TRACE: Transformer-based Risk Assessment for Clinical Evaluation
Nov 13, 2024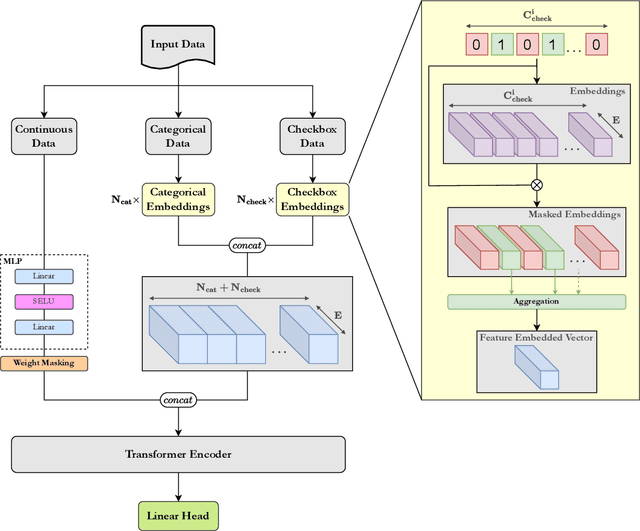
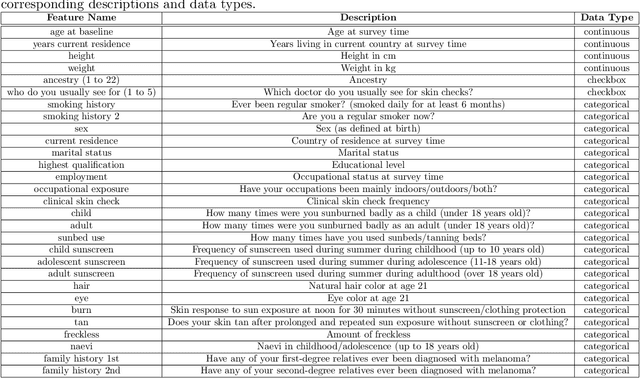

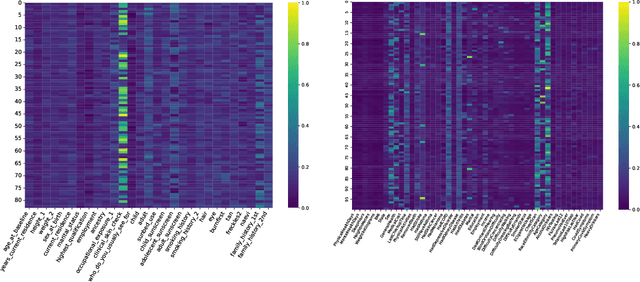
We present TRACE (Transformer-based Risk Assessment for Clinical Evaluation), a novel method for clinical risk assessment based on clinical data, leveraging the self-attention mechanism for enhanced feature interaction and result interpretation. Our approach is able to handle different data modalities, including continuous, categorical and multiple-choice (checkbox) attributes. The proposed architecture features a shared representation of the clinical data obtained by integrating specialized embeddings of each data modality, enabling the detection of high-risk individuals using Transformer encoder layers. To assess the effectiveness of the proposed method, a strong baseline based on non-negative multi-layer perceptrons (MLPs) is introduced. The proposed method outperforms various baselines widely used in the domain of clinical risk assessment, while effectively handling missing values. In terms of explainability, our Transformer-based method offers easily interpretable results via attention weights, further enhancing the clinicians' decision-making process.
Mapping savannah woody vegetation at the species level with multispecral drone and hyperspectral EnMAP data
Jul 16, 2024



Savannahs are vital ecosystems whose sustainability is endangered by the spread of woody plants. This research targets the accurate mapping of fractional woody cover (FWC) at the species level in a South African savannah, using EnMAP hyperspectral data. Field annotations were combined with very high-resolution multispectral drone data to produce land cover maps that included three woody species. The high-resolution labelled maps were then used to generate FWC samples for each woody species class at the 30-m spatial resolution of EnMAP. Four machine learning regression algorithms were tested for FWC mapping on dry season EnMAP imagery. The contribution of multitemporal information was also assessed by incorporating as additional regression features, spectro-temporal metrics from Sentinel-2 data of both the dry and wet seasons. The results demonstrated the suitability of our approach for accurately mapping FWC at the species level. The highest accuracy rates achieved from the combined EnMAP and Sentinel-2 experiments highlighted their synergistic potential for species-level vegetation mapping.
Addressing single object tracking in satellite imagery through prompt-engineered solutions
Jul 07, 2024Object tracking in satellite videos remains a complex endeavor in remote sensing due to the intricate and dynamic nature of satellite imagery. Existing state-of-the-art trackers in computer vision integrate sophisticated architectures, attention mechanisms, and multi-modal fusion to enhance tracking accuracy across diverse environments. However, the challenges posed by satellite imagery, such as background variations, atmospheric disturbances, and low-resolution object delineation, significantly impede the precision and reliability of traditional Single Object Tracking (SOT) techniques. Our study delves into these challenges and proposes prompt engineering methodologies, leveraging the Segment Anything Model (SAM) and TAPIR (Tracking Any Point with per-frame Initialization and temporal Refinement), to create a training-free point-based tracking method for small-scale objects on satellite videos. Experiments on the VISO dataset validate our strategy, marking a significant advancement in robust tracking solutions tailored for satellite imagery in remote sensing applications.
Composed Image Retrieval for Remote Sensing
May 29, 2024
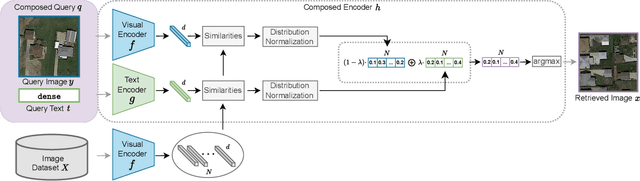


This work introduces composed image retrieval to remote sensing. It allows to query a large image archive by image examples alternated by a textual description, enriching the descriptive power over unimodal queries, either visual or textual. Various attributes can be modified by the textual part, such as shape, color, or context. A novel method fusing image-to-image and text-to-image similarity is introduced. We demonstrate that a vision-language model possesses sufficient descriptive power and no further learning step or training data are necessary. We present a new evaluation benchmark focused on color, context, density, existence, quantity, and shape modifications. Our work not only sets the state-of-the-art for this task, but also serves as a foundational step in addressing a gap in the field of remote sensing image retrieval. Code at: https://github.com/billpsomas/rscir
Evaluation of Resource-Efficient Crater Detectors on Embedded Systems
May 27, 2024
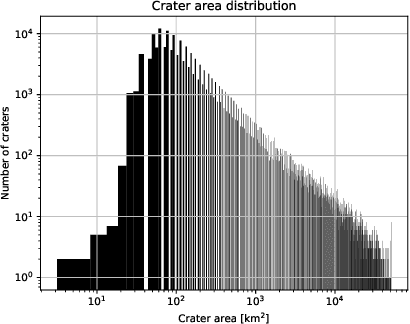
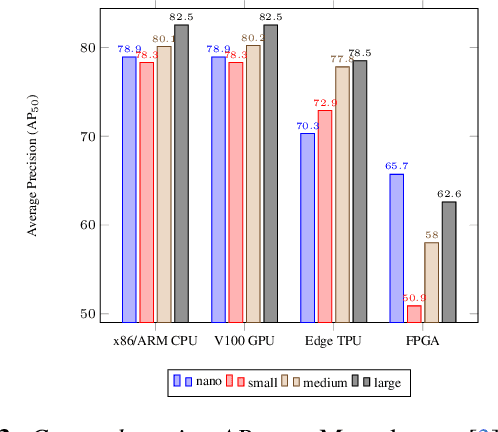
Real-time analysis of Martian craters is crucial for mission-critical operations, including safe landings and geological exploration. This work leverages the latest breakthroughs for on-the-edge crater detection aboard spacecraft. We rigorously benchmark several YOLO networks using a Mars craters dataset, analyzing their performance on embedded systems with a focus on optimization for low-power devices. We optimize this process for a new wave of cost-effective, commercial-off-the-shelf-based smaller satellites. Implementations on diverse platforms, including Google Coral Edge TPU, AMD Versal SoC VCK190, Nvidia Jetson Nano and Jetson AGX Orin, undergo a detailed trade-off analysis. Our findings identify optimal network-device pairings, enhancing the feasibility of crater detection on resource-constrained hardware and setting a new precedent for efficient and resilient extraterrestrial imaging. Code at: https://github.com/billpsomas/mars_crater_detection.
Has Anything Changed? 3D Change Detection by 2D Segmentation Masks
Dec 02, 2023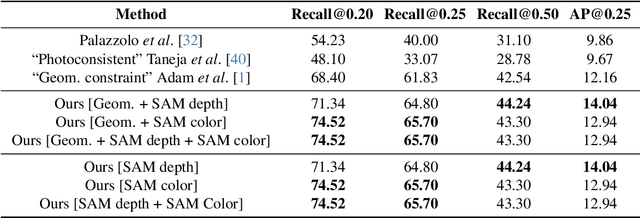
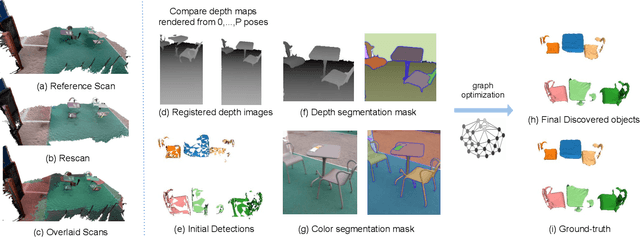
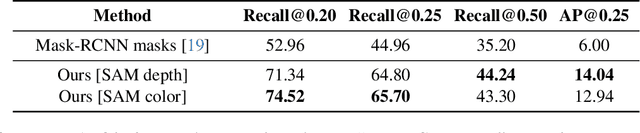
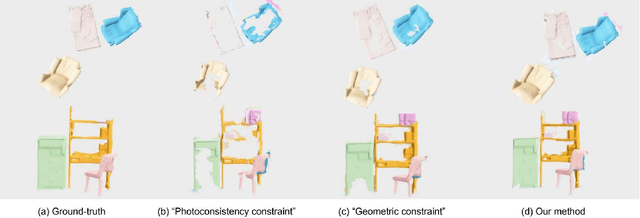
As capturing devices become common, 3D scans of interior spaces are acquired on a daily basis. Through scene comparison over time, information about objects in the scene and their changes is inferred. This information is important for robots and AR and VR devices, in order to operate in an immersive virtual experience. We thus propose an unsupervised object discovery method that identifies added, moved, or removed objects without any prior knowledge of what objects exist in the scene. We model this problem as a combination of a 3D change detection and a 2D segmentation task. Our algorithm leverages generic 2D segmentation masks to refine an initial but incomplete set of 3D change detections. The initial changes, acquired through render-and-compare likely correspond to movable objects. The incomplete detections are refined through graph optimization, distilling the information of the 2D segmentation masks in the 3D space. Experiments on the 3Rscan dataset prove that our method outperforms competitive baselines, with SoTA results.