 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSkin Lesion Phenotyping via Nested Multi-modal Contrastive Learning
May 29, 2025We introduce SLIMP (Skin Lesion Image-Metadata Pre-training) for learning rich representations of skin lesions through a novel nested contrastive learning approach that captures complex relationships between images and metadata. Melanoma detection and skin lesion classification based solely on images, pose significant challenges due to large variations in imaging conditions (lighting, color, resolution, distance, etc.) and lack of clinical and phenotypical context. Clinicians typically follow a holistic approach for assessing the risk level of the patient and for deciding which lesions may be malignant and need to be excised, by considering the patient's medical history as well as the appearance of other lesions of the patient. Inspired by this, SLIMP combines the appearance and the metadata of individual skin lesions with patient-level metadata relating to their medical record and other clinically relevant information. By fully exploiting all available data modalities throughout the learning process, the proposed pre-training strategy improves performance compared to other pre-training strategies on downstream skin lesions classification tasks highlighting the learned representations quality.
TRACE: Transformer-based Risk Assessment for Clinical Evaluation
Nov 13, 2024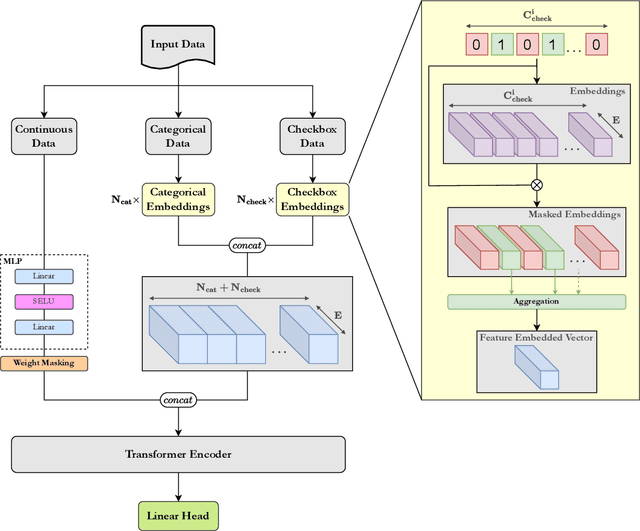
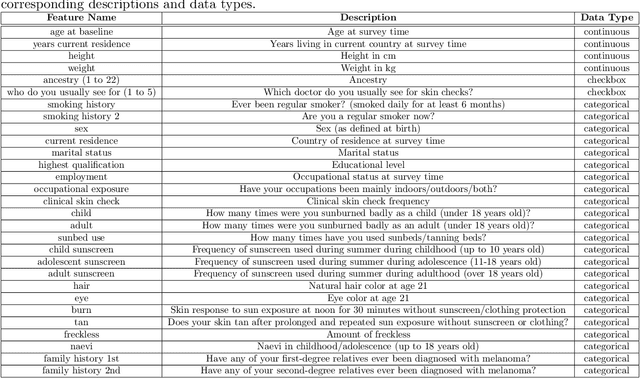

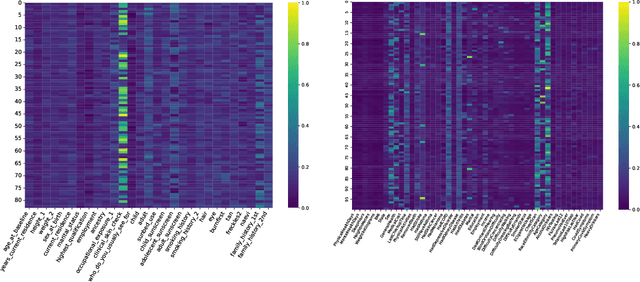
We present TRACE (Transformer-based Risk Assessment for Clinical Evaluation), a novel method for clinical risk assessment based on clinical data, leveraging the self-attention mechanism for enhanced feature interaction and result interpretation. Our approach is able to handle different data modalities, including continuous, categorical and multiple-choice (checkbox) attributes. The proposed architecture features a shared representation of the clinical data obtained by integrating specialized embeddings of each data modality, enabling the detection of high-risk individuals using Transformer encoder layers. To assess the effectiveness of the proposed method, a strong baseline based on non-negative multi-layer perceptrons (MLPs) is introduced. The proposed method outperforms various baselines widely used in the domain of clinical risk assessment, while effectively handling missing values. In terms of explainability, our Transformer-based method offers easily interpretable results via attention weights, further enhancing the clinicians' decision-making process.
Deep execution monitor for robot assistive tasks
Feb 07, 2019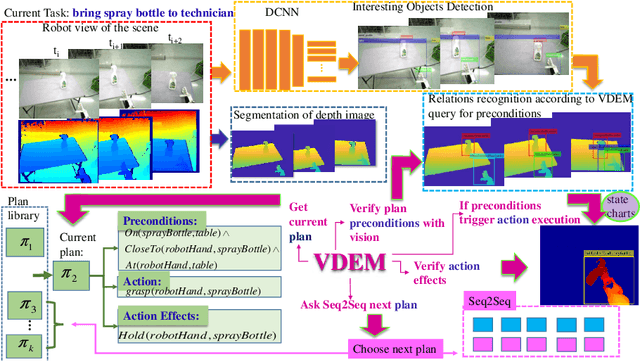
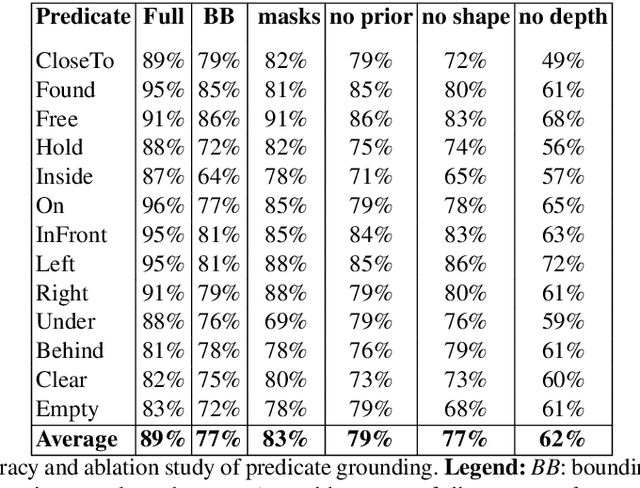

We consider a novel approach to high-level robot task execution for a robot assistive task. In this work we explore the problem of learning to predict the next subtask by introducing a deep model for both sequencing goals and for visually evaluating the state of a task. We show that deep learning for monitoring robot tasks execution very well supports the interconnection between task-level planning and robot operations. These solutions can also cope with the natural non-determinism of the execution monitor. We show that a deep execution monitor leverages robot performance. We measure the improvement taking into account some robot helping tasks performed at a warehouse.
Visual search and recognition for robot task execution and monitoring
Feb 07, 2019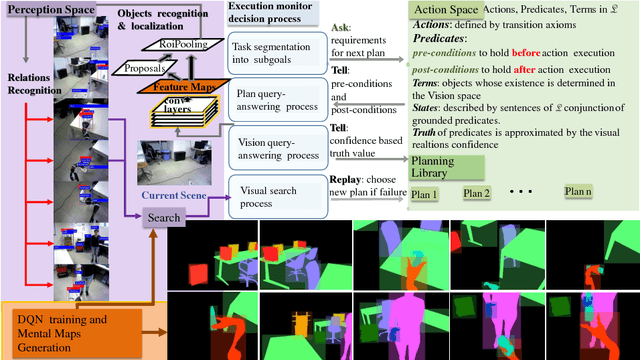
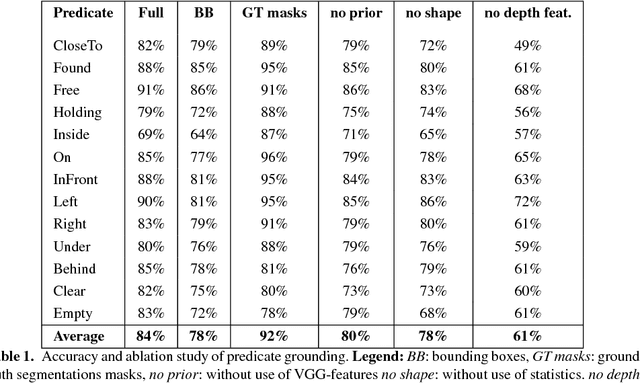


Visual search of relevant targets in the environment is a crucial robot skill. We propose a preliminary framework for the execution monitor of a robot task, taking care of the robot attitude to visually searching the environment for targets involved in the task. Visual search is also relevant to recover from a failure. The framework exploits deep reinforcement learning to acquire a "common sense" scene structure and it takes advantage of a deep convolutional network to detect objects and relevant relations holding between them. The framework builds on these methods to introduce a vision-based execution monitoring, which uses classical planning as a backbone for task execution. Experiments show that with the proposed vision-based execution monitor the robot can complete simple tasks and can recover from failures in autonomy.
Discovery and recognition of motion primitives in human activities
Feb 04, 2019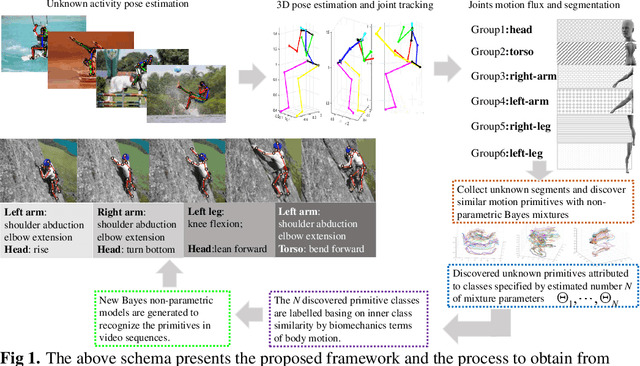
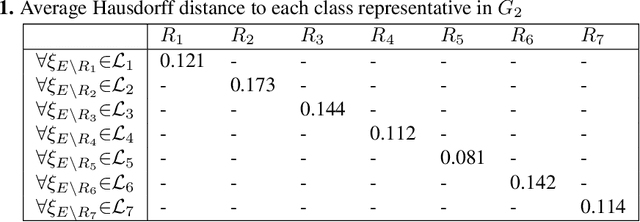
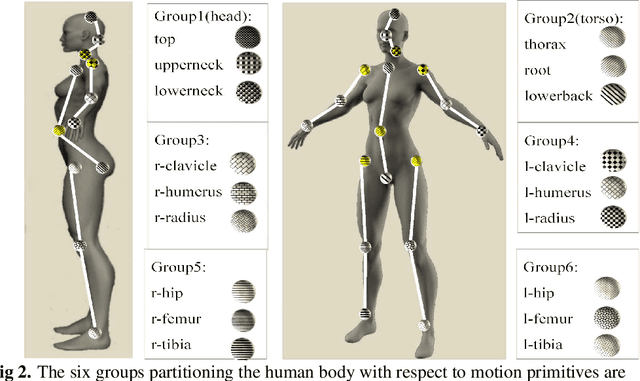
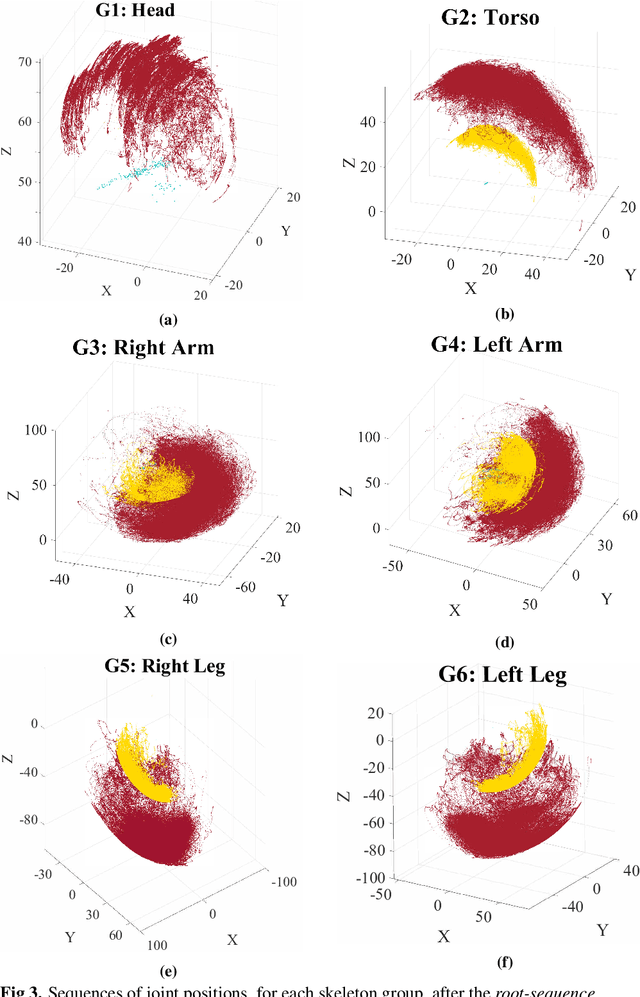
We present a novel framework for the automatic discovery and recognition of motion primitives in videos of human activities. Given the 3D pose of a human in a video, human motion primitives are discovered by optimizing the `motion flux', a quantity which captures the motion variation of a group of skeletal joints. A normalization of the primitives is proposed in order to make them invariant with respect to a subject anatomical variations and data sampling rate. The discovered primitives are unknown and unlabeled and are unsupervisedly collected into classes via a hierarchical non-parametric Bayes mixture model. Once classes are determined and labeled they are further analyzed for establishing models for recognizing discovered primitives. Each primitive model is defined by a set of learned parameters. Given new video data and given the estimated pose of the subject appearing on the video, the motion is segmented into primitives, which are recognized with a probability given according to the parameters of the learned models. Using our framework we build a publicly available dataset of human motion primitives, using sequences taken from well-known motion capture datasets. We expect that our framework, by providing an objective way for discovering and categorizing human motion, will be a useful tool in numerous research fields including video analysis, human inspired motion generation, learning by demonstration, intuitive human-robot interaction, and human behavior analysis.
Anticipation and next action forecasting in video: an end-to-end model with memory
Jan 11, 2019Action anticipation and forecasting in videos do not require a hat-trick, as far as there are signs in the context to foresee how actions are going to be deployed. Capturing these signs is hard because the context includes the past. We propose an end-to-end network for action anticipation and forecasting with memory, to both anticipate the current action and foresee the next one. Experiments on action sequence datasets show excellent results indicating that training on histories with a dynamic memory can significantly improve forecasting performance.
Confidence driven TGV fusion
Apr 29, 2016



We introduce a novel model for spatially varying variational data fusion, driven by point-wise confidence values. The proposed model allows for the joint estimation of the data and the confidence values based on the spatial coherence of the data. We discuss the main properties of the introduced model as well as suitable algorithms for estimating the solution of the corresponding biconvex minimization problem and their convergence. The performance of the proposed model is evaluated considering the problem of depth image fusion by using both synthetic and real data from publicly available datasets.