 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRemoving supervision in semantic segmentation with local-global matching and area balancing
Mar 30, 2023
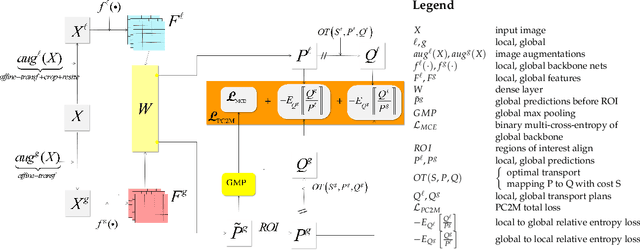


Removing supervision in semantic segmentation is still tricky. Current approaches can deal with common categorical patterns yet resort to multi-stage architectures. We design a novel end-to-end model leveraging local-global patch matching to predict categories, good localization, area and shape of objects for semantic segmentation. The local-global matching is, in turn, compelled by optimal transport plans fulfilling area constraints nearing a solution for exact shape prediction. Our model attains state-of-the-art in Weakly Supervised Semantic Segmentation, only image-level labels, with 75% mIoU on PascalVOC2012 val set and 46% on MS-COCO2014 val set. Dropping the image-level labels and clustering self-supervised learned features to yield pseudo-multi-level labels, we obtain an unsupervised model for semantic segmentation. We also attain state-of-the-art on Unsupervised Semantic Segmentation with 43.6% mIoU on PascalVOC2012 val set and 19.4% on MS-COCO2014 val set. The code is available at https://github.com/deepplants/PC2M.
Max Pooling with Vision Transformers reconciles class and shape in weakly supervised semantic segmentation
Oct 31, 2022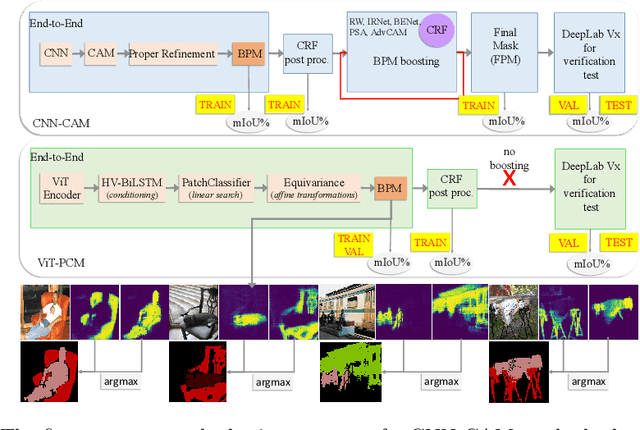
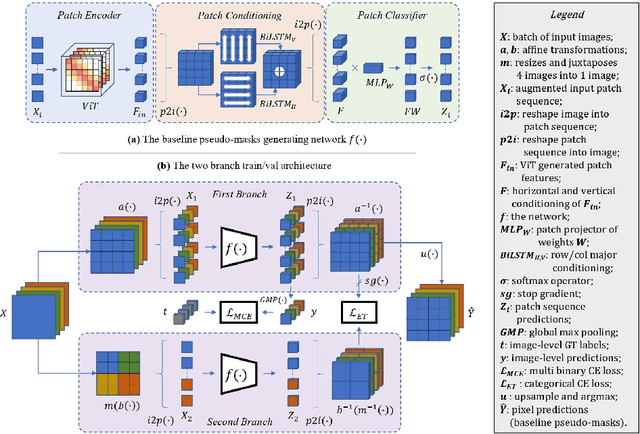
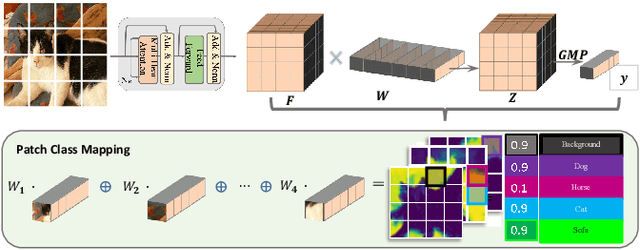
Weakly Supervised Semantic Segmentation (WSSS) research has explored many directions to improve the typical pipeline CNN plus class activation maps (CAM) plus refinements, given the image-class label as the only supervision. Though the gap with the fully supervised methods is reduced, further abating the spread seems unlikely within this framework. On the other hand, WSSS methods based on Vision Transformers (ViT) have not yet explored valid alternatives to CAM. ViT features have been shown to retain a scene layout, and object boundaries in self-supervised learning. To confirm these findings, we prove that the advantages of transformers in self-supervised methods are further strengthened by Global Max Pooling (GMP), which can leverage patch features to negotiate pixel-label probability with class probability. This work proposes a new WSSS method dubbed ViT-PCM (ViT Patch-Class Mapping), not based on CAM. The end-to-end presented network learns with a single optimization process, refined shape and proper localization for segmentation masks. Our model outperforms the state-of-the-art on baseline pseudo-masks (BPM), where we achieve $69.3\%$ mIoU on PascalVOC 2012 $val$ set. We show that our approach has the least set of parameters, though obtaining higher accuracy than all other approaches. In a sentence, quantitative and qualitative results of our method reveal that ViT-PCM is an excellent alternative to CNN-CAM based architectures.
Sentinel-1 and Sentinel-2 Spatio-Temporal Data Fusion for Clouds Removal
Jun 23, 2021
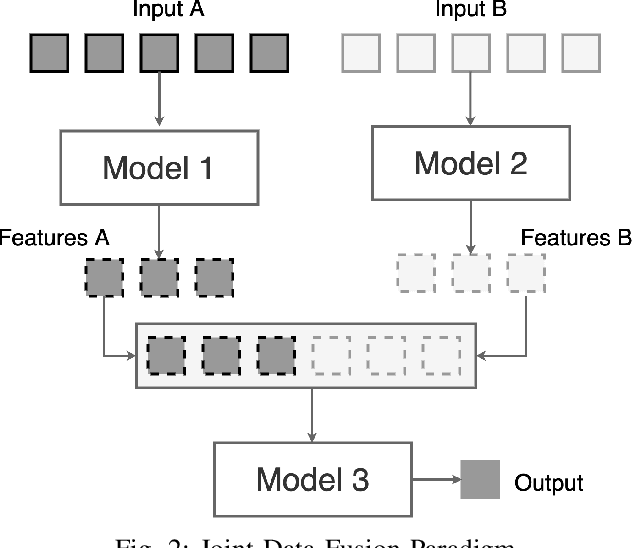
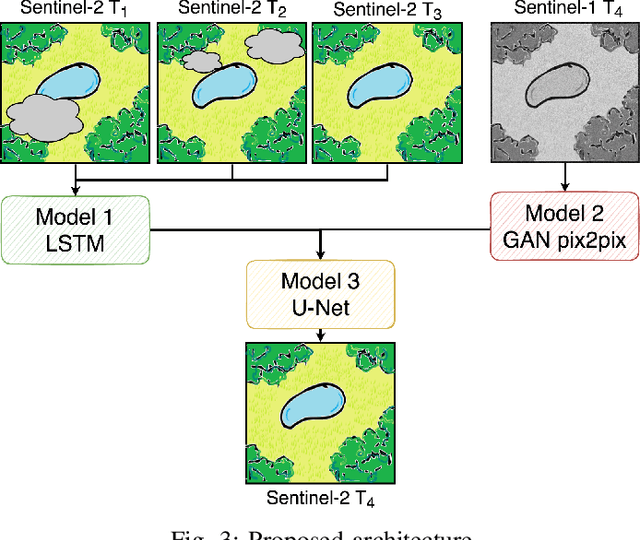
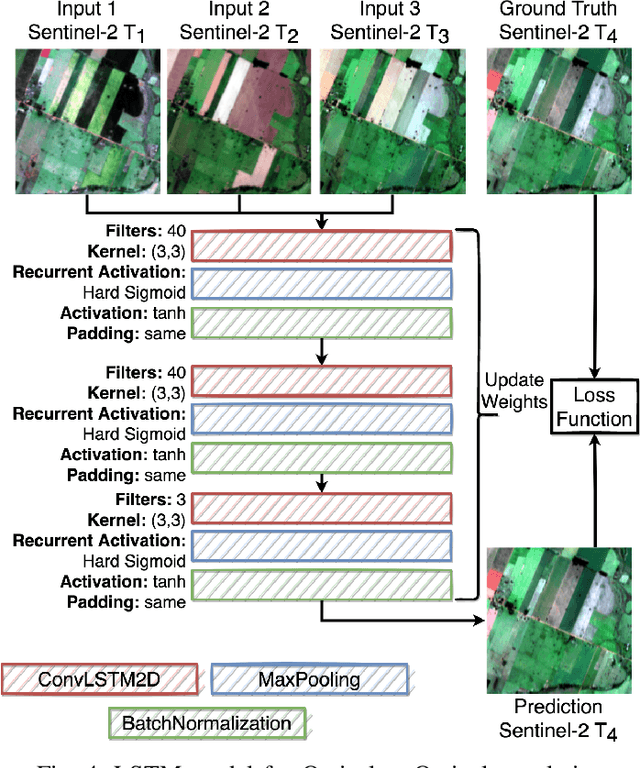
The abundance of clouds, located both spatially and temporally, often makes remote sensing applications with optical images difficult or even impossible. In this manuscript, a novel method for clouds-corrupted optical image restoration has been presented and developed, based on a joint data fusion paradigm, where three deep neural networks have been combined in order to fuse spatio-temporal features extracted from Sentinel-1 and Sentinel-2 time-series of data. It is worth highlighting that both the code and the dataset have been implemented from scratch and made available to interested research for further analysis and investigation.
3D Multi-Robot Patrolling with a Two-Level Coordination Strategy
Jun 23, 2019

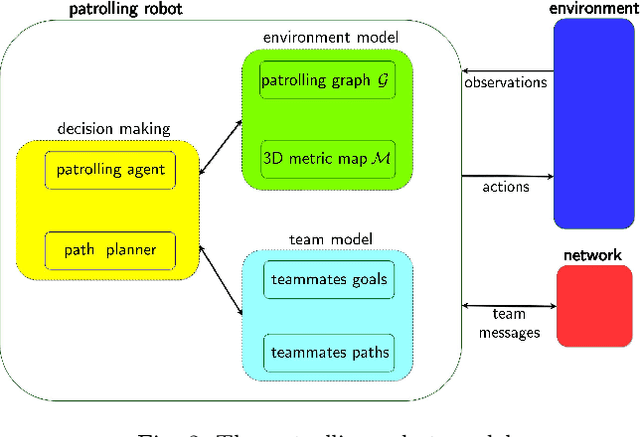
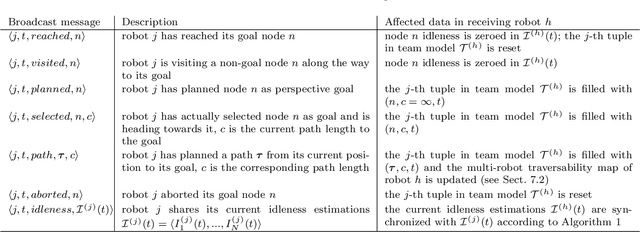
Teams of UGVs patrolling harsh and complex 3D environments can experience interference and spatial conflicts with one another. Neglecting the occurrence of these events crucially hinders both soundness and reliability of a patrolling process. This work presents a distributed multi-robot patrolling technique, which uses a two-level coordination strategy to minimize and explicitly manage the occurrence of conflicts and interference. The first level guides the agents to single out exclusive target nodes on a topological map. This target selection relies on a shared idleness representation and a coordination mechanism preventing topological conflicts. The second level hosts coordination strategies based on a metric representation of space and is supported by a 3D SLAM system. Here, each robot path planner negotiates spatial conflicts by applying a multi-robot traversability function. Continuous interactions between these two levels ensure coordination and conflicts resolution. Both simulations and real-world experiments are presented to validate the performances of the proposed patrolling strategy in 3D environments. Results show this is a promising solution for managing spatial conflicts and preventing deadlocks.
Deep execution monitor for robot assistive tasks
Feb 07, 2019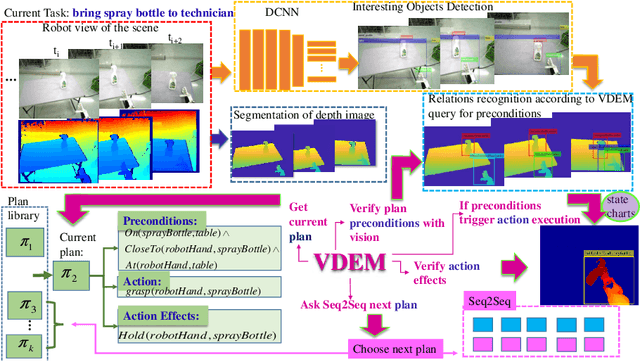

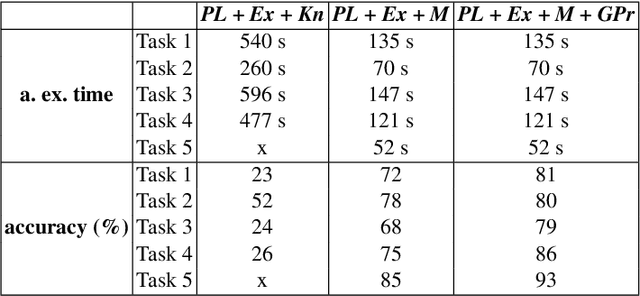
We consider a novel approach to high-level robot task execution for a robot assistive task. In this work we explore the problem of learning to predict the next subtask by introducing a deep model for both sequencing goals and for visually evaluating the state of a task. We show that deep learning for monitoring robot tasks execution very well supports the interconnection between task-level planning and robot operations. These solutions can also cope with the natural non-determinism of the execution monitor. We show that a deep execution monitor leverages robot performance. We measure the improvement taking into account some robot helping tasks performed at a warehouse.
Visual search and recognition for robot task execution and monitoring
Feb 07, 2019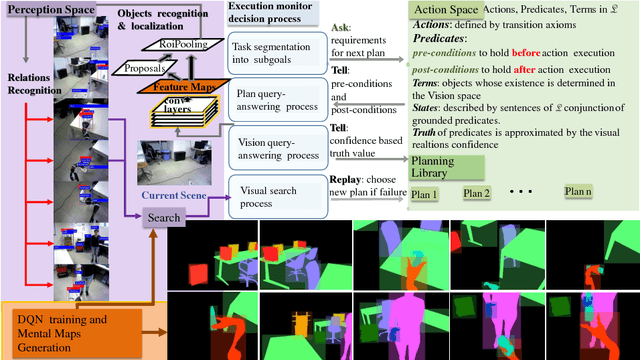
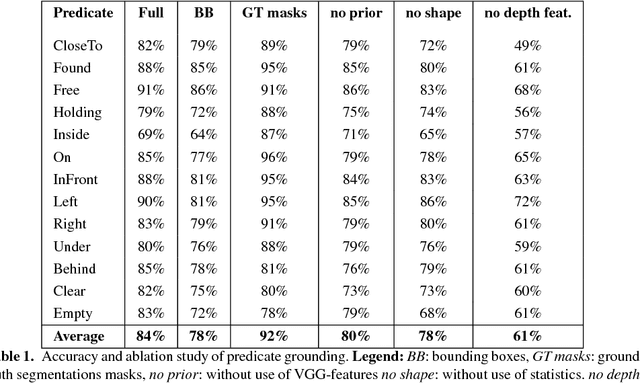


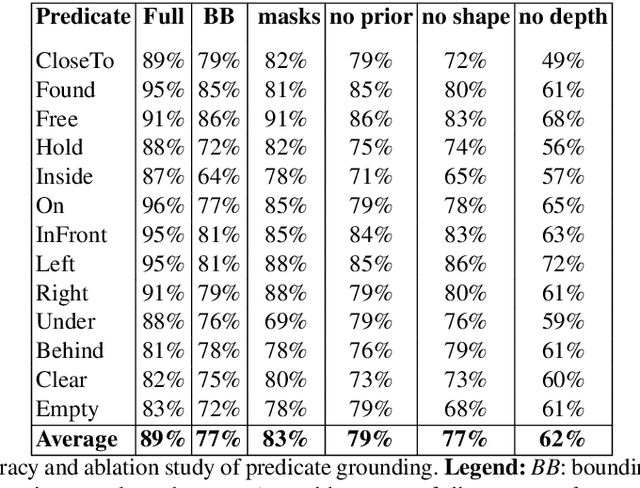
Visual search of relevant targets in the environment is a crucial robot skill. We propose a preliminary framework for the execution monitor of a robot task, taking care of the robot attitude to visually searching the environment for targets involved in the task. Visual search is also relevant to recover from a failure. The framework exploits deep reinforcement learning to acquire a "common sense" scene structure and it takes advantage of a deep convolutional network to detect objects and relevant relations holding between them. The framework builds on these methods to introduce a vision-based execution monitoring, which uses classical planning as a backbone for task execution. Experiments show that with the proposed vision-based execution monitor the robot can complete simple tasks and can recover from failures in autonomy.
Discovery and recognition of motion primitives in human activities
Feb 04, 2019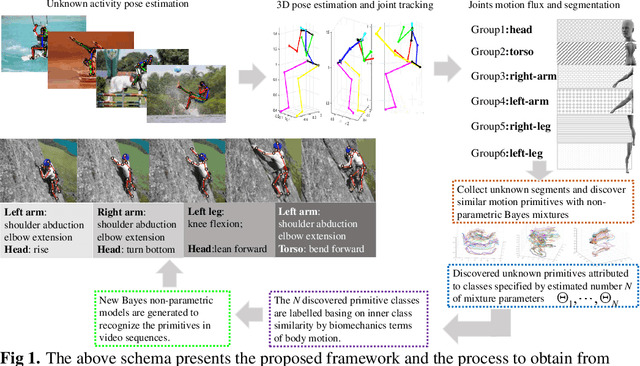
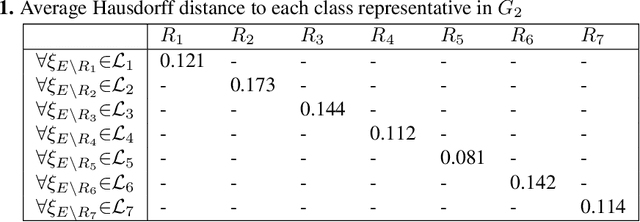
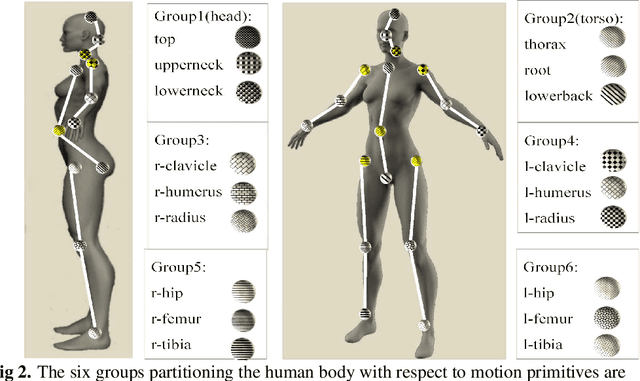
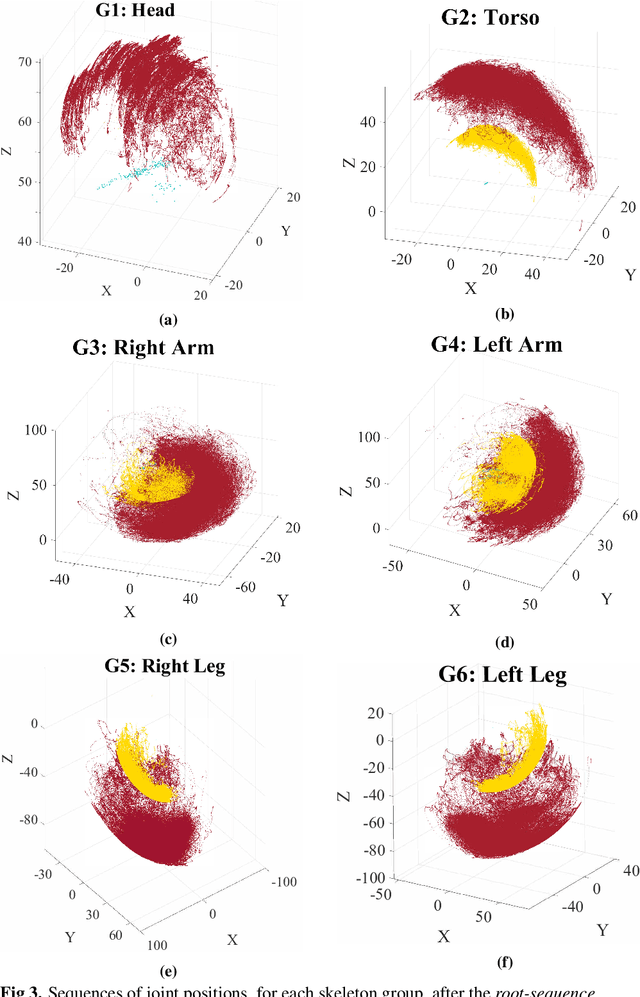
We present a novel framework for the automatic discovery and recognition of motion primitives in videos of human activities. Given the 3D pose of a human in a video, human motion primitives are discovered by optimizing the `motion flux', a quantity which captures the motion variation of a group of skeletal joints. A normalization of the primitives is proposed in order to make them invariant with respect to a subject anatomical variations and data sampling rate. The discovered primitives are unknown and unlabeled and are unsupervisedly collected into classes via a hierarchical non-parametric Bayes mixture model. Once classes are determined and labeled they are further analyzed for establishing models for recognizing discovered primitives. Each primitive model is defined by a set of learned parameters. Given new video data and given the estimated pose of the subject appearing on the video, the motion is segmented into primitives, which are recognized with a probability given according to the parameters of the learned models. Using our framework we build a publicly available dataset of human motion primitives, using sequences taken from well-known motion capture datasets. We expect that our framework, by providing an objective way for discovering and categorizing human motion, will be a useful tool in numerous research fields including video analysis, human inspired motion generation, learning by demonstration, intuitive human-robot interaction, and human behavior analysis.
Anticipation and next action forecasting in video: an end-to-end model with memory
Jan 11, 2019Action anticipation and forecasting in videos do not require a hat-trick, as far as there are signs in the context to foresee how actions are going to be deployed. Capturing these signs is hard because the context includes the past. We propose an end-to-end network for action anticipation and forecasting with memory, to both anticipate the current action and foresee the next one. Experiments on action sequence datasets show excellent results indicating that training on histories with a dynamic memory can significantly improve forecasting performance.
A Hybrid Approach for Trajectory Control Design
Jan 05, 2019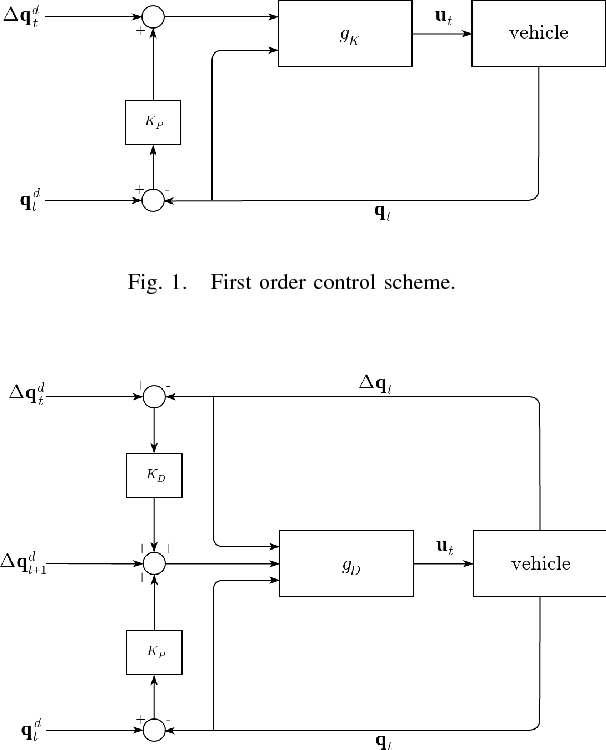
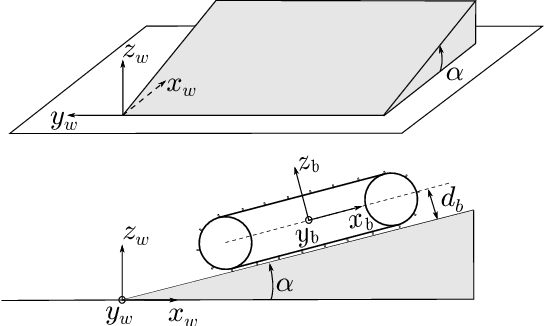

This work presents a methodology to design trajectory tracking feedback control laws, which embed non-parametric statistical models, such as Gaussian Processes (GPs). The aim is to minimize unmodeled dynamics such as undesired slippages. The proposed approach has the benefit of avoiding complex terramechanics analysis to directly estimate from data the robot dynamics on a wide class of trajectories. Experiments in both real and simulated environments prove that the proposed methodology is promising.
Vision-based deep execution monitoring
Sep 29, 2017
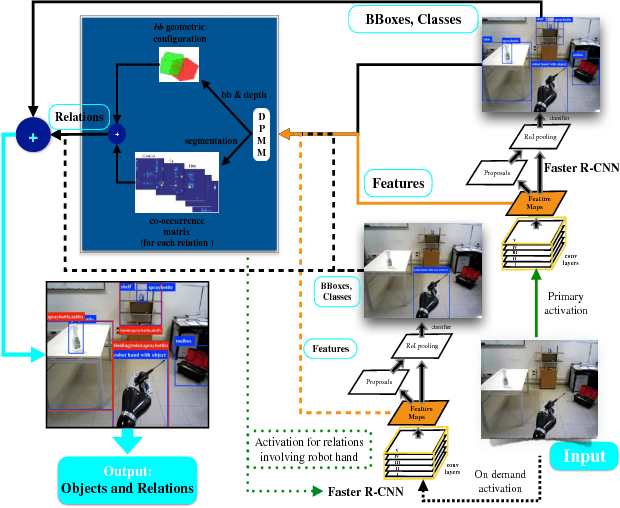

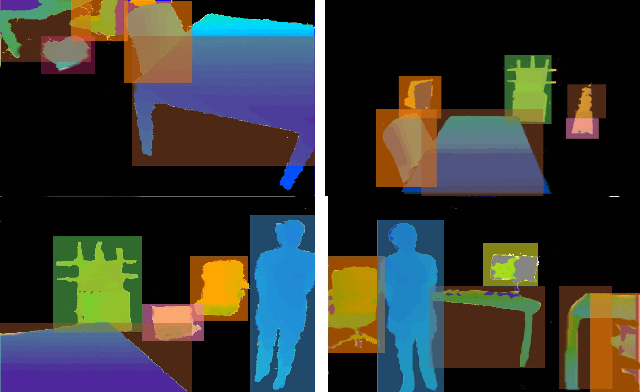
Execution monitor of high-level robot actions can be effectively improved by visual monitoring the state of the world in terms of preconditions and postconditions that hold before and after the execution of an action. Furthermore a policy for searching where to look at, either for verifying the relations that specify the pre and postconditions or to refocus in case of a failure, can tremendously improve the robot execution in an uncharted environment. It is now possible to strongly rely on visual perception in order to make the assumption that the environment is observable, by the amazing results of deep learning. In this work we present visual execution monitoring for a robot executing tasks in an uncharted Lab environment. The execution monitor interacts with the environment via a visual stream that uses two DCNN for recognizing the objects the robot has to deal with and manipulate, and a non-parametric Bayes estimation to discover the relations out of the DCNN features. To recover from lack of focus and failures due to missed objects we resort to visual search policies via deep reinforcement learning.