 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring the Feasibility of Multilingual Grammatical Error Correction with a Single LLM up to 9B parameters: A Comparative Study of 17 Models
May 09, 2025Recent language models can successfully solve various language-related tasks, and many understand inputs stated in different languages. In this paper, we explore the performance of 17 popular models used to correct grammatical issues in texts stated in English, German, Italian, and Swedish when using a single model to correct texts in all those languages. We analyze the outputs generated by these models, focusing on decreasing the number of grammatical errors while keeping the changes small. The conclusions drawn help us understand what problems occur among those models and which models can be recommended for multilingual grammatical error correction tasks. We list six models that improve grammatical correctness in all four languages and show that Gemma 9B is currently the best performing one for the languages considered.
MultiSlav: Using Cross-Lingual Knowledge Transfer to Combat the Curse of Multilinguality
Feb 20, 2025



Does multilingual Neural Machine Translation (NMT) lead to The Curse of the Multlinguality or provides the Cross-lingual Knowledge Transfer within a language family? In this study, we explore multiple approaches for extending the available data-regime in NMT and we prove cross-lingual benefits even in 0-shot translation regime for low-resource languages. With this paper, we provide state-of-the-art open-source NMT models for translating between selected Slavic languages. We released our models on the HuggingFace Hub (https://hf.co/collections/allegro/multislav-6793d6b6419e5963e759a683) under the CC BY 4.0 license. Slavic language family comprises morphologically rich Central and Eastern European languages. Although counting hundreds of millions of native speakers, Slavic Neural Machine Translation is under-studied in our opinion. Recently, most NMT research focuses either on: high-resource languages like English, Spanish, and German - in WMT23 General Translation Task 7 out of 8 task directions are from or to English; massively multilingual models covering multiple language groups; or evaluation techniques.
Chasing COMET: Leveraging Minimum Bayes Risk Decoding for Self-Improving Machine Translation
May 20, 2024



This paper explores Minimum Bayes Risk (MBR) decoding for self-improvement in machine translation (MT), particularly for domain adaptation and low-resource languages. We implement the self-improvement process by fine-tuning the model on its MBR-decoded forward translations. By employing COMET as the MBR utility metric, we aim to achieve the reranking of translations that better aligns with human preferences. The paper explores the iterative application of this approach and the potential need for language-specific MBR utility metrics. The results demonstrate significant enhancements in translation quality for all examined language pairs, including successful application to domain-adapted models and generalisation to low-resource settings. This highlights the potential of COMET-guided MBR for efficient MT self-improvement in various scenarios.
FAME-MT Dataset: Formality Awareness Made Easy for Machine Translation Purposes
May 20, 2024



People use language for various purposes. Apart from sharing information, individuals may use it to express emotions or to show respect for another person. In this paper, we focus on the formality level of machine-generated translations and present FAME-MT -- a dataset consisting of 11.2 million translations between 15 European source languages and 8 European target languages classified to formal and informal classes according to target sentence formality. This dataset can be used to fine-tune machine translation models to ensure a given formality level for each European target language considered. We describe the dataset creation procedure, the analysis of the dataset's quality showing that FAME-MT is a reliable source of language register information, and we present a publicly available proof-of-concept machine translation model that uses the dataset to steer the formality level of the translation. Currently, it is the largest dataset of formality annotations, with examples expressed in 112 European language pairs. The dataset is published online: https://github.com/laniqo-public/fame-mt/ .
Exploring the Use of Foundation Models for Named Entity Recognition and Lemmatization Tasks in Slavic Languages
Apr 11, 2023


This paper describes Adam Mickiewicz University's (AMU) solution for the 4th Shared Task on SlavNER. The task involves the identification, categorization, and lemmatization of named entities in Slavic languages. Our approach involved exploring the use of foundation models for these tasks. In particular, we used models based on the popular BERT and T5 model architectures. Additionally, we used external datasets to further improve the quality of our models. Our solution obtained promising results, achieving high metrics scores in both tasks. We describe our approach and the results of our experiments in detail, showing that the method is effective for NER and lemmatization in Slavic languages. Additionally, our models for lemmatization will be available at: https://huggingface.co/amu-cai.
Approaching English-Polish Machine Translation Quality Assessment with Neural-based Methods
Sep 22, 2022



This paper presents our contribution to the PolEval 2021 Task 2: Evaluation of translation quality assessment metrics. We describe experiments with pre-trained language models and state-of-the-art frameworks for translation quality assessment in both nonblind and blind versions of the task. Our solutions ranked second in the nonblind version and third in the blind version.
* PolEval 2021
Adam Mickiewicz University at WMT 2022: NER-Assisted and Quality-Aware Neural Machine Translation
Sep 07, 2022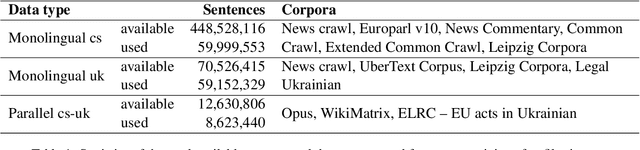
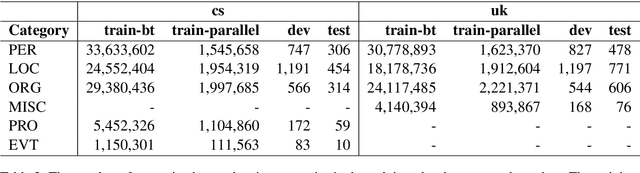
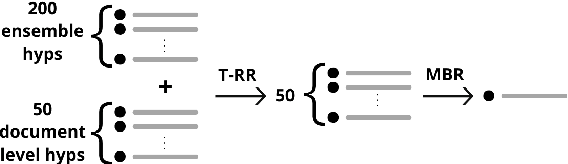
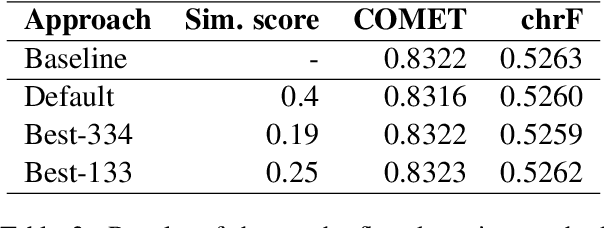
This paper presents Adam Mickiewicz University's (AMU) submissions to the constrained track of the WMT 2022 General MT Task. We participated in the Ukrainian $\leftrightarrow$ Czech translation directions. The systems are a weighted ensemble of four models based on the Transformer (big) architecture. The models use source factors to utilize the information about named entities present in the input. Each of the models in the ensemble was trained using only the data provided by the shared task organizers. A noisy back-translation technique was used to augment the training corpora. One of the models in the ensemble is a document-level model, trained on parallel and synthetic longer sequences. During the sentence-level decoding process, the ensemble generated the n-best list. The n-best list was merged with the n-best list generated by a single document-level model which translated multiple sentences at a time. Finally, existing quality estimation models and minimum Bayes risk decoding were used to rerank the n-best list so that the best hypothesis was chosen according to the COMET evaluation metric. According to the automatic evaluation results, our systems rank first in both translation directions.
Self-supervised learning -- A way to minimize time and effort for precision agriculture?
Apr 05, 2022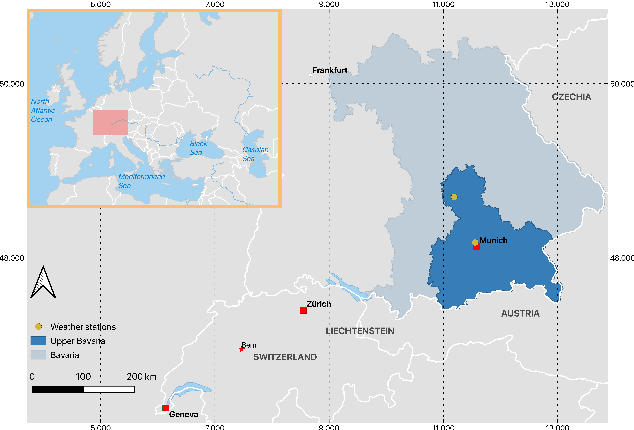
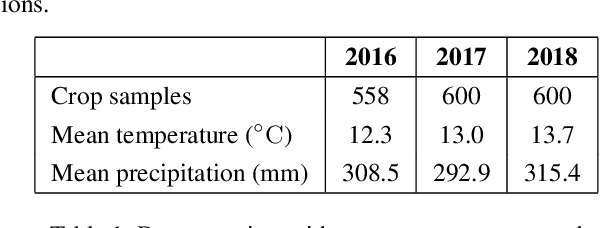
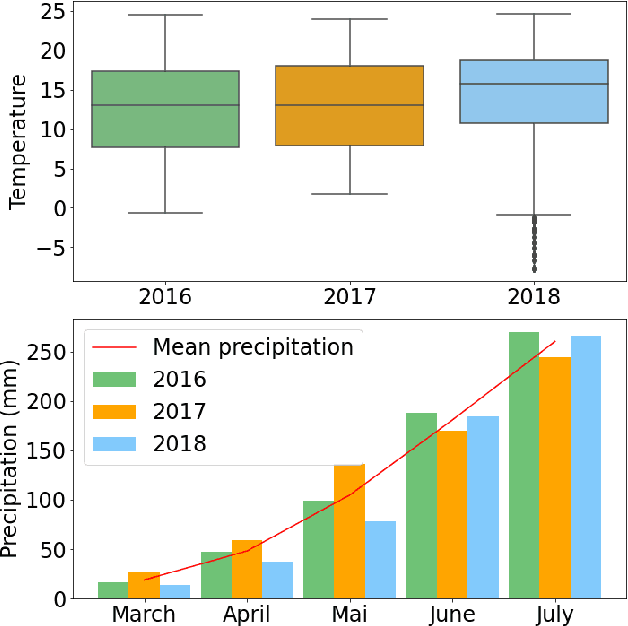
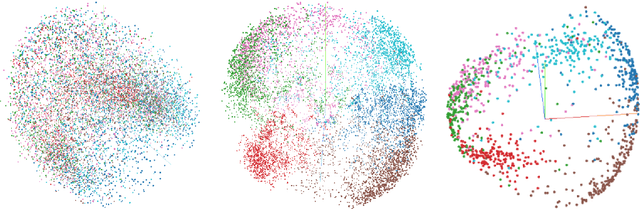
Machine learning, satellites or local sensors are key factors for a sustainable and resource-saving optimisation of agriculture and proved its values for the management of agricultural land. Up to now, the main focus was on the enlargement of data which were evaluated by means of supervised learning methods. Nevertheless, the need for labels is also a limiting and time-consuming factor, while in contrast, ongoing technological development is already providing an ever-increasing amount of unlabeled data. Self-supervised learning (SSL) could overcome this limitation and incorporate existing unlabeled data. Therefore, a crop type data set was utilized to conduct experiments with SSL and compare it to supervised methods. A unique feature of our data set from 2016 to 2018 was a divergent climatological condition in 2018 that reduced yields and affected the spectral fingerprint of the plants. Our experiments focused on predicting 2018 using SLL without or a few labels to clarify whether new labels should be collected for an unknown year. Despite these challenging conditions, the results showed that SSL contributed to higher accuracies. We believe that the results will encourage further improvements in the field of precision farming, why the SSL framework and data will be published (Marszalek, 2021).
Detection of Criminal Texts for the Polish State Border Guard
Aug 24, 2021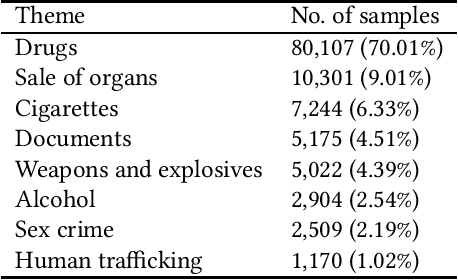
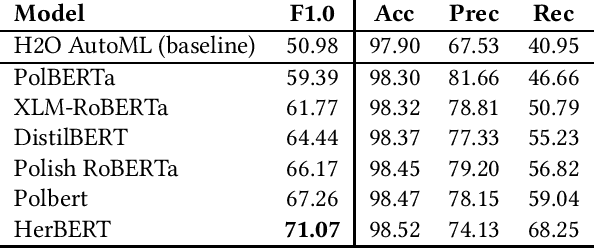
This paper describes research on the detection of Polish criminal texts appearing on the Internet. We carried out experiments to find the best available setup for the efficient classification of unbalanced and noisy data. The best performance was achieved when our model was fine-tuned on a pre-trained Polish-based transformer language model. For the detection task, a large corpus of annotated Internet snippets was collected as training data. We share this dataset and create a new task for the detection of criminal texts using the Gonito platform as the benchmark.
Sentinel-1 and Sentinel-2 Spatio-Temporal Data Fusion for Clouds Removal
Jun 23, 2021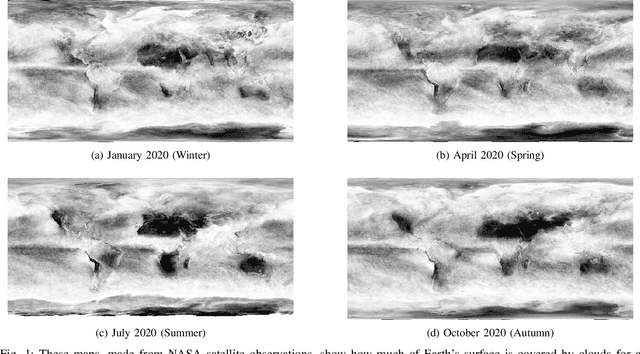
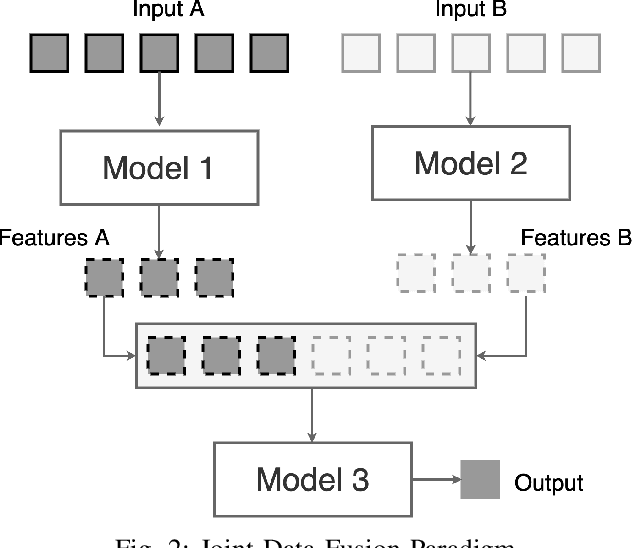
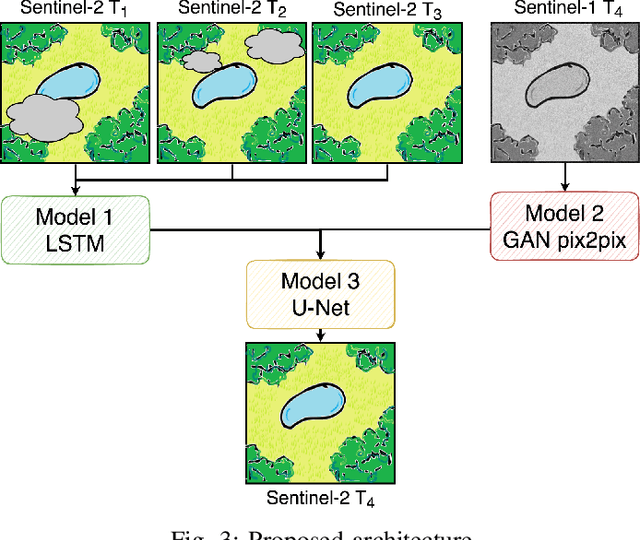
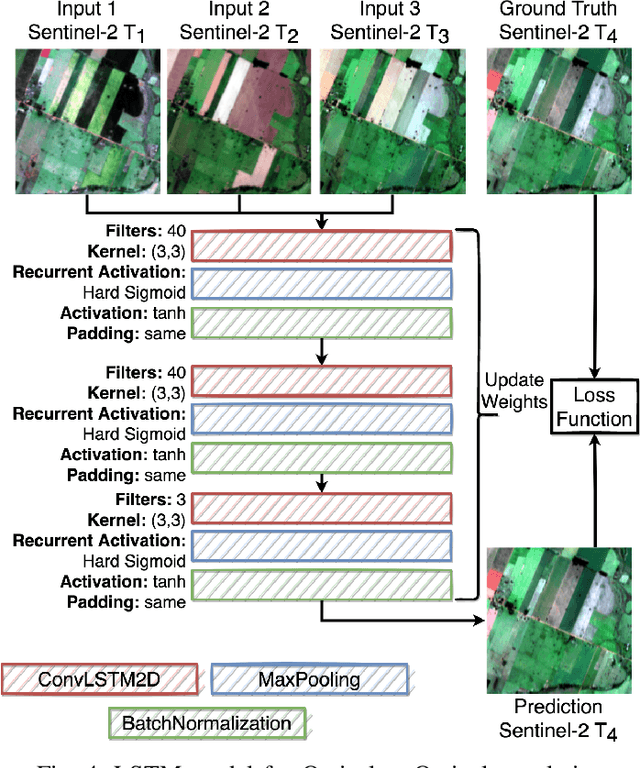
The abundance of clouds, located both spatially and temporally, often makes remote sensing applications with optical images difficult or even impossible. In this manuscript, a novel method for clouds-corrupted optical image restoration has been presented and developed, based on a joint data fusion paradigm, where three deep neural networks have been combined in order to fuse spatio-temporal features extracted from Sentinel-1 and Sentinel-2 time-series of data. It is worth highlighting that both the code and the dataset have been implemented from scratch and made available to interested research for further analysis and investigation.