 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConECT Dataset: Overcoming Data Scarcity in Context-Aware E-Commerce MT
Jun 05, 2025Neural Machine Translation (NMT) has improved translation by using Transformer-based models, but it still struggles with word ambiguity and context. This problem is especially important in domain-specific applications, which often have problems with unclear sentences or poor data quality. Our research explores how adding information to models can improve translations in the context of e-commerce data. To this end we create ConECT -- a new Czech-to-Polish e-commerce product translation dataset coupled with images and product metadata consisting of 11,400 sentence pairs. We then investigate and compare different methods that are applicable to context-aware translation. We test a vision-language model (VLM), finding that visual context aids translation quality. Additionally, we explore the incorporation of contextual information into text-to-text models, such as the product's category path or image descriptions. The results of our study demonstrate that the incorporation of contextual information leads to an improvement in the quality of machine translation. We make the new dataset publicly available.
MultiSlav: Using Cross-Lingual Knowledge Transfer to Combat the Curse of Multilinguality
Feb 20, 2025Does multilingual Neural Machine Translation (NMT) lead to The Curse of the Multlinguality or provides the Cross-lingual Knowledge Transfer within a language family? In this study, we explore multiple approaches for extending the available data-regime in NMT and we prove cross-lingual benefits even in 0-shot translation regime for low-resource languages. With this paper, we provide state-of-the-art open-source NMT models for translating between selected Slavic languages. We released our models on the HuggingFace Hub (https://hf.co/collections/allegro/multislav-6793d6b6419e5963e759a683) under the CC BY 4.0 license. Slavic language family comprises morphologically rich Central and Eastern European languages. Although counting hundreds of millions of native speakers, Slavic Neural Machine Translation is under-studied in our opinion. Recently, most NMT research focuses either on: high-resource languages like English, Spanish, and German - in WMT23 General Translation Task 7 out of 8 task directions are from or to English; massively multilingual models covering multiple language groups; or evaluation techniques.
Evaluation of Transfer Learning for Polish with a Text-to-Text Model
May 18, 2022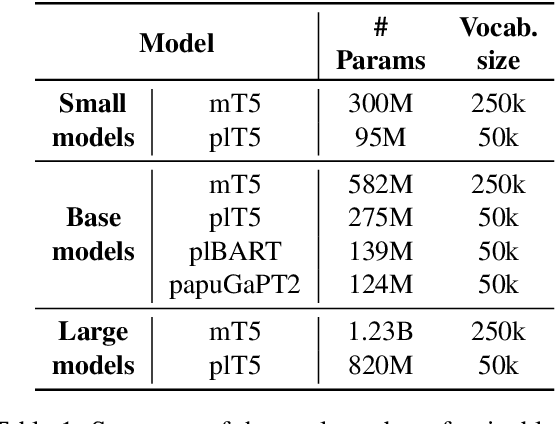

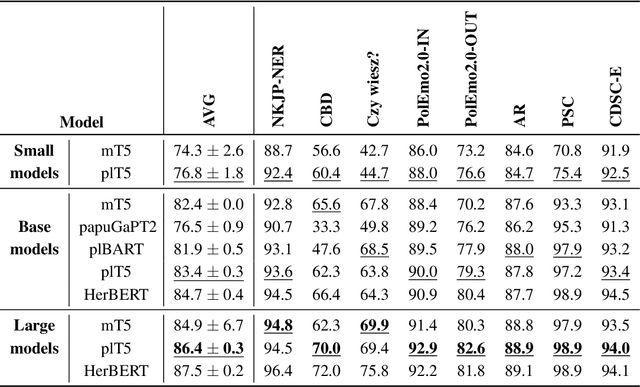
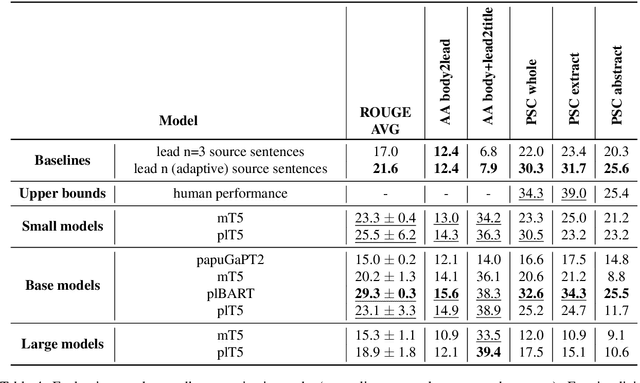
We introduce a new benchmark for assessing the quality of text-to-text models for Polish. The benchmark consists of diverse tasks and datasets: KLEJ benchmark adapted for text-to-text, en-pl translation, summarization, and question answering. In particular, since summarization and question answering lack benchmark datasets for the Polish language, we describe their construction and make them publicly available. Additionally, we present plT5 - a general-purpose text-to-text model for Polish that can be fine-tuned on various Natural Language Processing (NLP) tasks with a single training objective. Unsupervised denoising pre-training is performed efficiently by initializing the model weights with a multi-lingual T5 (mT5) counterpart. We evaluate the performance of plT5, mT5, Polish BART (plBART), and Polish GPT-2 (papuGaPT2). The plT5 scores top on all of these tasks except summarization, where plBART is best. In general (except for summarization), the larger the model, the better the results. The encoder-decoder architectures prove to be better than the decoder-only equivalent.