 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLLuM: A Family of Polish Large Language Models
Nov 05, 2025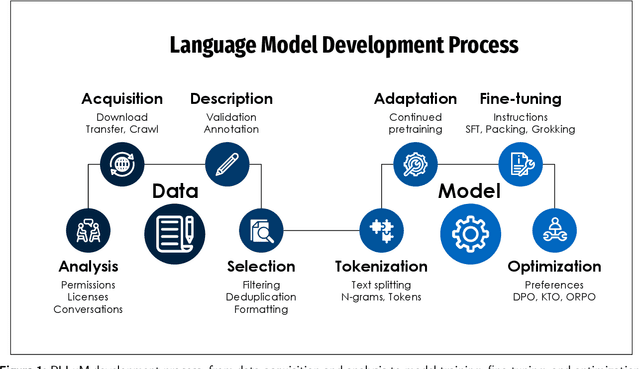
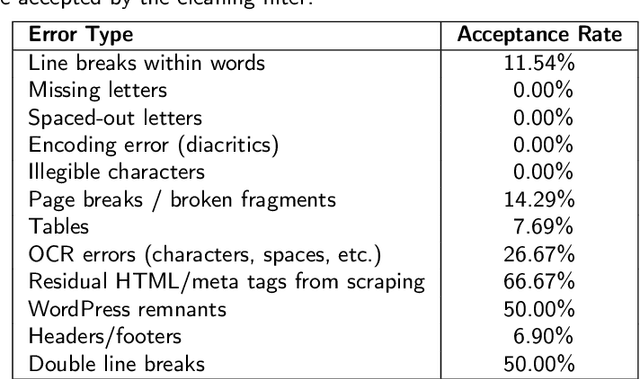
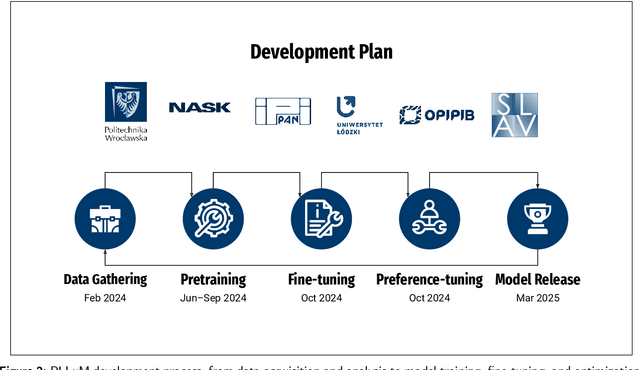

Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
NLPre: a revised approach towards language-centric benchmarking of Natural Language Preprocessing systems
Mar 07, 2024



With the advancements of transformer-based architectures, we observe the rise of natural language preprocessing (NLPre) tools capable of solving preliminary NLP tasks (e.g. tokenisation, part-of-speech tagging, dependency parsing, or morphological analysis) without any external linguistic guidance. It is arduous to compare novel solutions to well-entrenched preprocessing toolkits, relying on rule-based morphological analysers or dictionaries. Aware of the shortcomings of existing NLPre evaluation approaches, we investigate a novel method of reliable and fair evaluation and performance reporting. Inspired by the GLUE benchmark, the proposed language-centric benchmarking system enables comprehensive ongoing evaluation of multiple NLPre tools, while credibly tracking their performance. The prototype application is configured for Polish and integrated with the thoroughly assembled NLPre-PL benchmark. Based on this benchmark, we conduct an extensive evaluation of a variety of Polish NLPre systems. To facilitate the construction of benchmarking environments for other languages, e.g. NLPre-GA for Irish or NLPre-ZH for Chinese, we ensure full customization of the publicly released source code of the benchmarking system. The links to all the resources (deployed platforms, source code, trained models, datasets etc.) can be found on the project website: https://sites.google.com/view/nlpre-benchmark.
Transferring BERT Capabilities from High-Resource to Low-Resource Languages Using Vocabulary Matching
Feb 22, 2024


Pre-trained language models have revolutionized the natural language understanding landscape, most notably BERT (Bidirectional Encoder Representations from Transformers). However, a significant challenge remains for low-resource languages, where limited data hinders the effective training of such models. This work presents a novel approach to bridge this gap by transferring BERT capabilities from high-resource to low-resource languages using vocabulary matching. We conduct experiments on the Silesian and Kashubian languages and demonstrate the effectiveness of our approach to improve the performance of BERT models even when the target language has minimal training data. Our results highlight the potential of the proposed technique to effectively train BERT models for low-resource languages, thus democratizing access to advanced language understanding models.
SilverRetriever: Advancing Neural Passage Retrieval for Polish Question Answering
Sep 15, 2023Modern open-domain question answering systems often rely on accurate and efficient retrieval components to find passages containing the facts necessary to answer the question. Recently, neural retrievers have gained popularity over lexical alternatives due to their superior performance. However, most of the work concerns popular languages such as English or Chinese. For others, such as Polish, few models are available. In this work, we present SilverRetriever, a neural retriever for Polish trained on a diverse collection of manually or weakly labeled datasets. SilverRetriever achieves much better results than other Polish models and is competitive with larger multilingual models. Together with the model, we open-source five new passage retrieval datasets.
MAUPQA: Massive Automatically-created Polish Question Answering Dataset
May 09, 2023Recently, open-domain question answering systems have begun to rely heavily on annotated datasets to train neural passage retrievers. However, manually annotating such datasets is both difficult and time-consuming, which limits their availability for less popular languages. In this work, we experiment with several methods for automatically collecting weakly labeled datasets and show how they affect the performance of the neural passage retrieval models. As a result of our work, we publish the MAUPQA dataset, consisting of nearly 400,000 question-passage pairs for Polish, as well as the HerBERT-QA neural retriever.
Going beyond research datasets: Novel intent discovery in the industry setting
May 09, 2023Novel intent discovery automates the process of grouping similar messages (questions) to identify previously unknown intents. However, current research focuses on publicly available datasets which have only the question field and significantly differ from real-life datasets. This paper proposes methods to improve the intent discovery pipeline deployed in a large e-commerce platform. We show the benefit of pre-training language models on in-domain data: both self-supervised and with weak supervision. We also devise the best method to utilize the conversational structure (i.e., question and answer) of real-life datasets during fine-tuning for clustering tasks, which we call Conv. All our methods combined to fully utilize real-life datasets give up to 33pp performance boost over state-of-the-art Constrained Deep Adaptive Clustering (CDAC) model for question only. By comparison CDAC model for the question data only gives only up to 13pp performance boost over the naive baseline.
Improving Question Answering Performance through Manual Annotation: Costs, Benefits and Strategies
Dec 17, 2022



Recently proposed systems for open-domain question answering (OpenQA) require large amounts of training data to achieve state-of-the-art performance. However, data annotation is known to be time-consuming and therefore expensive to acquire. As a result, the appropriate datasets are available only for a handful of languages (mainly English and Chinese). In this work, we introduce and publicly release PolQA, the first Polish dataset for OpenQA. It consists of 7,000 questions, 87,525 manually labeled evidence passages, and a corpus of over 7,097,322 candidate passages. Each question is classified according to its formulation, type, as well as entity type of the answer. This resource allows us to evaluate the impact of different annotation choices on the performance of the QA system and propose an efficient annotation strategy that increases the passage retrieval performance by 10.55 p.p. while reducing the annotation cost by 82%.
Evaluation of Transfer Learning for Polish with a Text-to-Text Model
May 18, 2022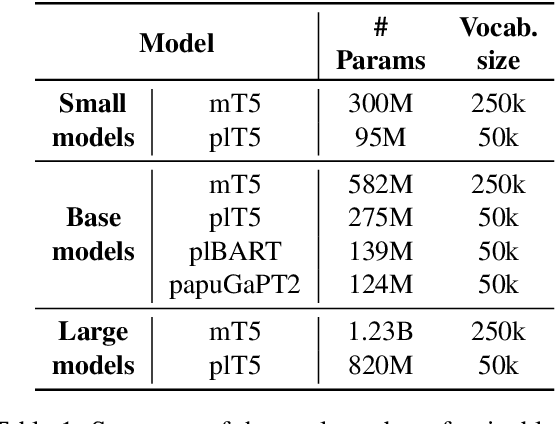

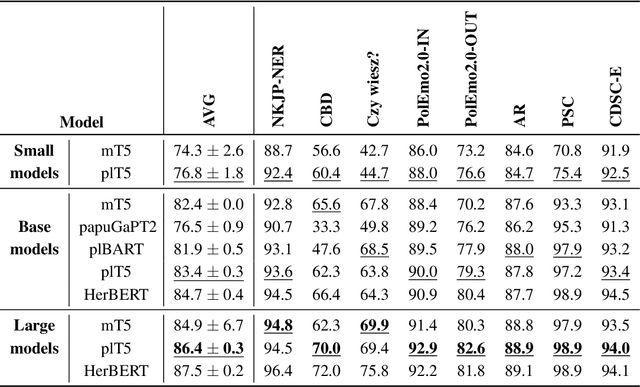
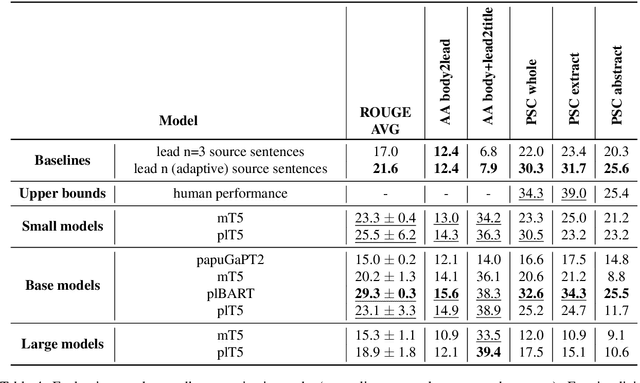
We introduce a new benchmark for assessing the quality of text-to-text models for Polish. The benchmark consists of diverse tasks and datasets: KLEJ benchmark adapted for text-to-text, en-pl translation, summarization, and question answering. In particular, since summarization and question answering lack benchmark datasets for the Polish language, we describe their construction and make them publicly available. Additionally, we present plT5 - a general-purpose text-to-text model for Polish that can be fine-tuned on various Natural Language Processing (NLP) tasks with a single training objective. Unsupervised denoising pre-training is performed efficiently by initializing the model weights with a multi-lingual T5 (mT5) counterpart. We evaluate the performance of plT5, mT5, Polish BART (plBART), and Polish GPT-2 (papuGaPT2). The plT5 scores top on all of these tasks except summarization, where plBART is best. In general (except for summarization), the larger the model, the better the results. The encoder-decoder architectures prove to be better than the decoder-only equivalent.
HerBERT: Efficiently Pretrained Transformer-based Language Model for Polish
May 04, 2021
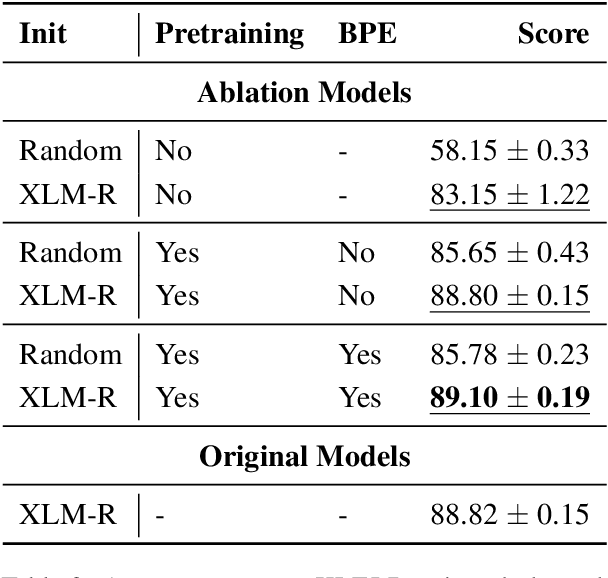


BERT-based models are currently used for solving nearly all Natural Language Processing (NLP) tasks and most often achieve state-of-the-art results. Therefore, the NLP community conducts extensive research on understanding these models, but above all on designing effective and efficient training procedures. Several ablation studies investigating how to train BERT-like models have been carried out, but the vast majority of them concerned only the English language. A training procedure designed for English does not have to be universal and applicable to other especially typologically different languages. Therefore, this paper presents the first ablation study focused on Polish, which, unlike the isolating English language, is a fusional language. We design and thoroughly evaluate a pretraining procedure of transferring knowledge from multilingual to monolingual BERT-based models. In addition to multilingual model initialization, other factors that possibly influence pretraining are also explored, i.e. training objective, corpus size, BPE-Dropout, and pretraining length. Based on the proposed procedure, a Polish BERT-based language model -- HerBERT -- is trained. This model achieves state-of-the-art results on multiple downstream tasks.
KLEJ: Comprehensive Benchmark for Polish Language Understanding
May 01, 2020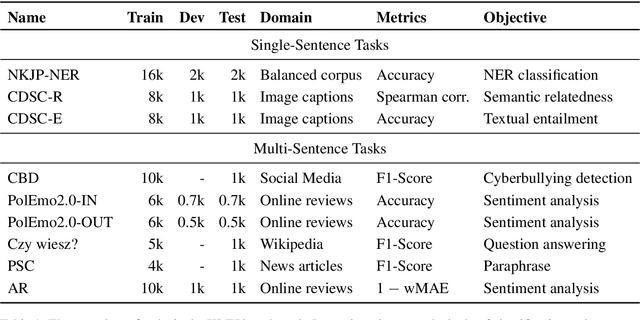


In recent years, a series of Transformer-based models unlocked major improvements in general natural language understanding (NLU) tasks. Such a fast pace of research would not be possible without general NLU benchmarks, which allow for a fair comparison of the proposed methods. However, such benchmarks are available only for a handful of languages. To alleviate this issue, we introduce a comprehensive multi-task benchmark for the Polish language understanding, accompanied by an online leaderboard. It consists of a diverse set of tasks, adopted from existing datasets for named entity recognition, question-answering, textual entailment, and others. We also introduce a new sentiment analysis task for the e-commerce domain, named Allegro Reviews (AR). To ensure a common evaluation scheme and promote models that generalize to different NLU tasks, the benchmark includes datasets from varying domains and applications. Additionally, we release HerBERT, a Transformer-based model trained specifically for the Polish language, which has the best average performance and obtains the best results for three out of nine tasks. Finally, we provide an extensive evaluation, including several standard baselines and recently proposed, multilingual Transformer-based models.