 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePLLuM: A Family of Polish Large Language Models
Nov 05, 2025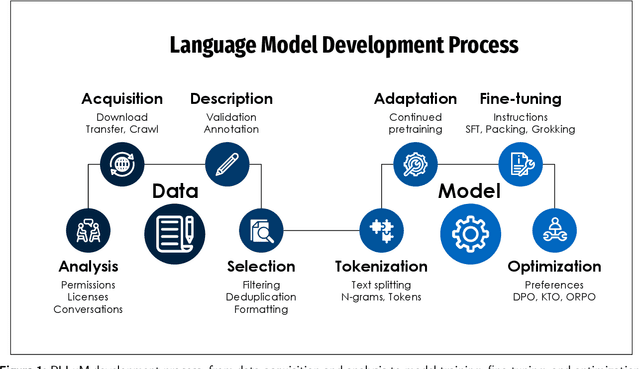
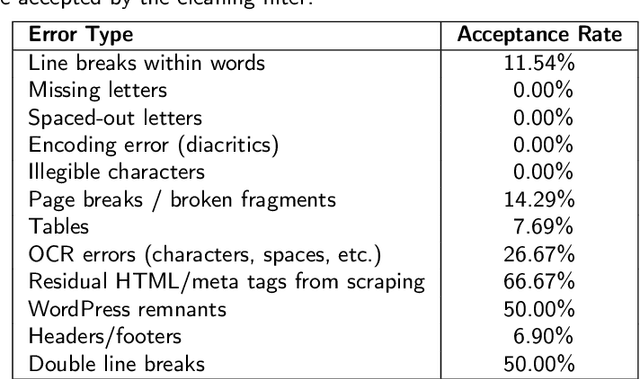
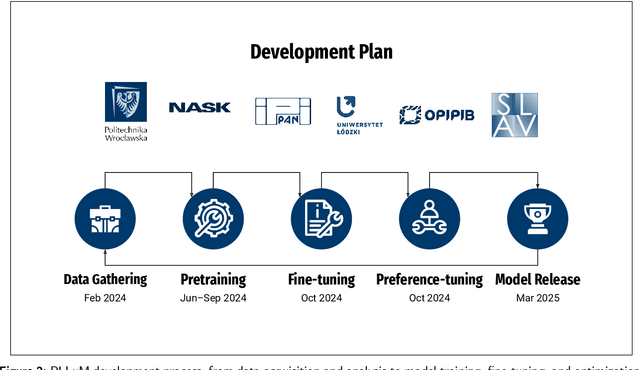

Large Language Models (LLMs) play a central role in modern artificial intelligence, yet their development has been primarily focused on English, resulting in limited support for other languages. We present PLLuM (Polish Large Language Model), the largest open-source family of foundation models tailored specifically for the Polish language. Developed by a consortium of major Polish research institutions, PLLuM addresses the need for high-quality, transparent, and culturally relevant language models beyond the English-centric commercial landscape. We describe the development process, including the construction of a new 140-billion-token Polish text corpus for pre-training, a 77k custom instructions dataset, and a 100k preference optimization dataset. A key component is a Responsible AI framework that incorporates strict data governance and a hybrid module for output correction and safety filtering. We detail the models' architecture, training procedures, and alignment techniques for both base and instruction-tuned variants, and demonstrate their utility in a downstream task within public administration. By releasing these models publicly, PLLuM aims to foster open research and strengthen sovereign AI technologies in Poland.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Developing PUGG for Polish: A Modern Approach to KBQA, MRC, and IR Dataset Construction
Aug 05, 2024



Advancements in AI and natural language processing have revolutionized machine-human language interactions, with question answering (QA) systems playing a pivotal role. The knowledge base question answering (KBQA) task, utilizing structured knowledge graphs (KG), allows for handling extensive knowledge-intensive questions. However, a significant gap exists in KBQA datasets, especially for low-resource languages. Many existing construction pipelines for these datasets are outdated and inefficient in human labor, and modern assisting tools like Large Language Models (LLM) are not utilized to reduce the workload. To address this, we have designed and implemented a modern, semi-automated approach for creating datasets, encompassing tasks such as KBQA, Machine Reading Comprehension (MRC), and Information Retrieval (IR), tailored explicitly for low-resource environments. We executed this pipeline and introduced the PUGG dataset, the first Polish KBQA dataset, and novel datasets for MRC and IR. Additionally, we provide a comprehensive implementation, insightful findings, detailed statistics, and evaluation of baseline models.
BEIR-PL: Zero Shot Information Retrieval Benchmark for the Polish Language
May 31, 2023The BEIR dataset is a large, heterogeneous benchmark for Information Retrieval (IR) in zero-shot settings, garnering considerable attention within the research community. However, BEIR and analogous datasets are predominantly restricted to the English language. Our objective is to establish extensive large-scale resources for IR in the Polish language, thereby advancing the research in this NLP area. In this work, inspired by mMARCO and Mr.~TyDi datasets, we translated all accessible open IR datasets into Polish, and we introduced the BEIR-PL benchmark -- a new benchmark which comprises 13 datasets, facilitating further development, training and evaluation of modern Polish language models for IR tasks. We executed an evaluation and comparison of numerous IR models on the newly introduced BEIR-PL benchmark. Furthermore, we publish pre-trained open IR models for Polish language,d marking a pioneering development in this field. Additionally, the evaluation revealed that BM25 achieved significantly lower scores for Polish than for English, which can be attributed to high inflection and intricate morphological structure of the Polish language. Finally, we trained various re-ranking models to enhance the BM25 retrieval, and we compared their performance to identify their unique characteristic features. To ensure accurate model comparisons, it is necessary to scrutinise individual results rather than to average across the entire benchmark. Thus, we thoroughly analysed the outcomes of IR models in relation to each individual data subset encompassed by the BEIR benchmark. The benchmark data is available at URL {\bf https://huggingface.co/clarin-knext}.
ChatGPT: Jack of all trades, master of none
Feb 21, 2023



OpenAI has released the Chat Generative Pre-trained Transformer (ChatGPT) and revolutionized the approach in artificial intelligence to human-model interaction. The first contact with the chatbot reveals its ability to provide detailed and precise answers in various areas. There are several publications on ChatGPT evaluation, testing its effectiveness on well-known natural language processing (NLP) tasks. However, the existing studies are mostly non-automated and tested on a very limited scale. In this work, we examined ChatGPT's capabilities on 25 diverse analytical NLP tasks, most of them subjective even to humans, such as sentiment analysis, emotion recognition, offensiveness and stance detection, natural language inference, word sense disambiguation, linguistic acceptability and question answering. We automated ChatGPT's querying process and analyzed more than 38k responses. Our comparison of its results with available State-of-the-Art (SOTA) solutions showed that the average loss in quality of the ChatGPT model was about 25% for zero-shot and few-shot evaluation. We showed that the more difficult the task (lower SOTA performance), the higher the ChatGPT loss. It especially refers to pragmatic NLP problems like emotion recognition. We also tested the ability of personalizing ChatGPT responses for selected subjective tasks via Random Contextual Few-Shot Personalization, and we obtained significantly better user-based predictions. Additional qualitative analysis revealed a ChatGPT bias, most likely due to the rules imposed on human trainers by OpenAI. Our results provide the basis for a fundamental discussion of whether the high quality of recent predictive NLP models can indicate a tool's usefulness to society and how the learning and validation procedures for such systems should be established.