 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMVEB: Massive Video Embedding Benchmark
Jun 12, 2026We introduce the Massive Video Embedding Benchmark (MVEB), a 23-task benchmark for video embeddings spanning classification, zero-shot classification, clustering, pair classification, retrieval, and video-centric question answering. We evaluate 33 models and find that no single model dominates: MLLM-based embeddings lead on classification, clustering, pair classification, and QA; multimodal binding leads on retrieval and zero-shot classification; generative MLLMs without contrastive adaptation collapse on cross-modal tasks. Paired video-only vs. audio+video evaluations show that audio's contribution depends on dataset annotation provenance: audio helps when labels were produced from both modalities and hurts when they were produced from visuals alone, a six-point gap consistent across model families. MVEB is derived from MVEB+, a 184-task pool, and is designed to maintain task diversity while reducing evaluation cost. It integrates into the MTEB ecosystem for unified evaluation across text, image, audio, and video. We release MVEB and all 184 tasks along with code and a leaderboard at https://github.com/embeddings-benchmark/mteb.
MMTEB: Massive Multilingual Text Embedding Benchmark
Feb 19, 2025Text embeddings are typically evaluated on a limited set of tasks, which are constrained by language, domain, and task diversity. To address these limitations and provide a more comprehensive evaluation, we introduce the Massive Multilingual Text Embedding Benchmark (MMTEB) - a large-scale, community-driven expansion of MTEB, covering over 500 quality-controlled evaluation tasks across 250+ languages. MMTEB includes a diverse set of challenging, novel tasks such as instruction following, long-document retrieval, and code retrieval, representing the largest multilingual collection of evaluation tasks for embedding models to date. Using this collection, we develop several highly multilingual benchmarks, which we use to evaluate a representative set of models. We find that while large language models (LLMs) with billions of parameters can achieve state-of-the-art performance on certain language subsets and task categories, the best-performing publicly available model is multilingual-e5-large-instruct with only 560 million parameters. To facilitate accessibility and reduce computational cost, we introduce a novel downsampling method based on inter-task correlation, ensuring a diverse selection while preserving relative model rankings. Furthermore, we optimize tasks such as retrieval by sampling hard negatives, creating smaller but effective splits. These optimizations allow us to introduce benchmarks that drastically reduce computational demands. For instance, our newly introduced zero-shot English benchmark maintains a ranking order similar to the full-scale version but at a fraction of the computational cost.
Extending the Massive Text Embedding Benchmark to French
May 30, 2024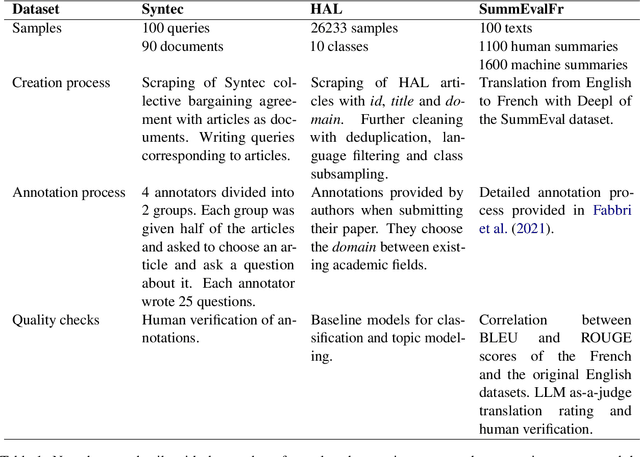
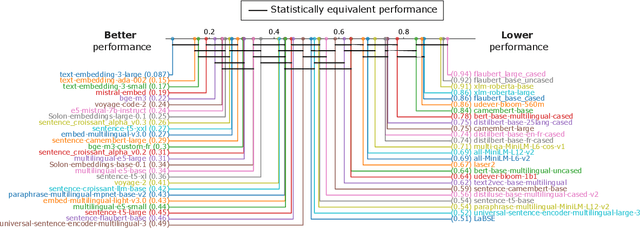
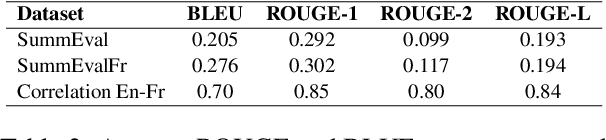
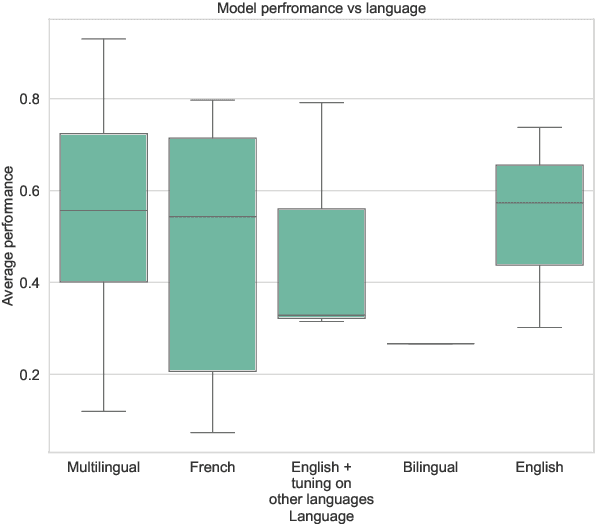
In recent years, numerous embedding models have been made available and widely used for various NLP tasks. Choosing a model that performs well for several tasks in English has been largely simplified by the Massive Text Embedding Benchmark (MTEB), but extensions to other languages remain challenging. This is why we expand MTEB to propose the first massive benchmark of sentence embeddings for French. Not only we gather 22 existing datasets in an easy-to-use interface, but we also create three new French datasets for a global evaluation over 8 different tasks. We perform a large scale comparison with 46 carefully selected embedding models, conduct comprehensive statistical tests, and analyze the correlation between model performance and many of their characteristics. We find out that even if no model is the best on all tasks, large multilingual models pre-trained on sentence similarity perform particularly well. Our work comes with open-source code, new datasets and a public leaderboard.
The Importance of Future Information in Credit Card Fraud Detection
Apr 11, 2022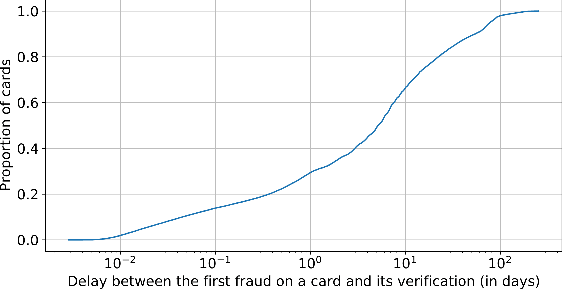
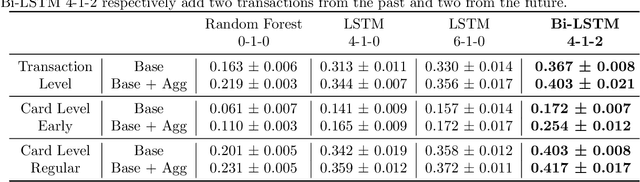
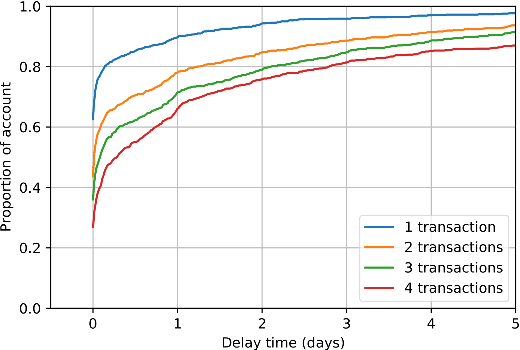
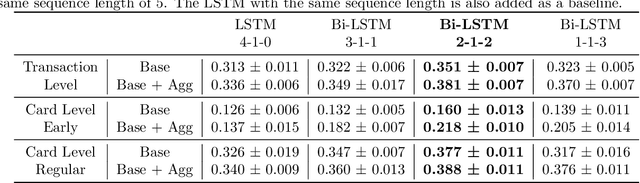
Fraud detection systems (FDS) mainly perform two tasks: (i) real-time detection while the payment is being processed and (ii) posterior detection to block the card retrospectively and avoid further frauds. Since human verification is often necessary and the payment processing time is limited, the second task manages the largest volume of transactions. In the literature, fraud detection challenges and algorithms performance are widely studied but the very formulation of the problem is never disrupted: it aims at predicting if a transaction is fraudulent based on its characteristics and the past transactions of the cardholder. Yet, in posterior detection, verification often takes days, so new payments on the card become available before a decision is taken. This is our motivation to propose a new paradigm: posterior fraud detection with "future" information. We start by providing evidence of the on-time availability of subsequent transactions, usable as extra context to improve detection. We then design a Bidirectional LSTM to make use of these transactions. On a real-world dataset with over 30 million transactions, it achieves higher performance than a regular LSTM, which is the state-of-the-art classifier for fraud detection that only uses the past context. We also introduce new metrics to show that the proposal catches more frauds, more compromised cards, and based on their earliest frauds. We believe that future works on this new paradigm will have a significant impact on the detection of compromised cards.
Transfer Learning for Credit Card Fraud Detection: A Journey from Research to Production
Jul 20, 2021
The dark face of digital commerce generalization is the increase of fraud attempts. To prevent any type of attacks, state of the art fraud detection systems are now embedding Machine Learning (ML) modules. The conception of such modules is only communicated at the level of research and papers mostly focus on results for isolated benchmark datasets and metrics. But research is only a part of the journey, preceded by the right formulation of the business problem and collection of data, and followed by a practical integration. In this paper, we give a wider vision of the process, on a case study of transfer learning for fraud detection, from business to research, and back to business.
Delaying Interaction Layers in Transformer-based Encoders for Efficient Open Domain Question Answering
Oct 16, 2020



Open Domain Question Answering (ODQA) on a large-scale corpus of documents (e.g. Wikipedia) is a key challenge in computer science. Although transformer-based language models such as Bert have shown on SQuAD the ability to surpass humans for extracting answers in small passages of text, they suffer from their high complexity when faced to a much larger search space. The most common way to tackle this problem is to add a preliminary Information Retrieval step to heavily filter the corpus and only keep the relevant passages. In this paper, we propose a more direct and complementary solution which consists in applying a generic change in the architecture of transformer-based models to delay the attention between subparts of the input and allow a more efficient management of computations. The resulting variants are competitive with the original models on the extractive task and allow, on the ODQA setting, a significant speedup and even a performance improvement in many cases.
Multilingual Question Answering from Formatted Text applied to Conversational Agents
Oct 10, 2019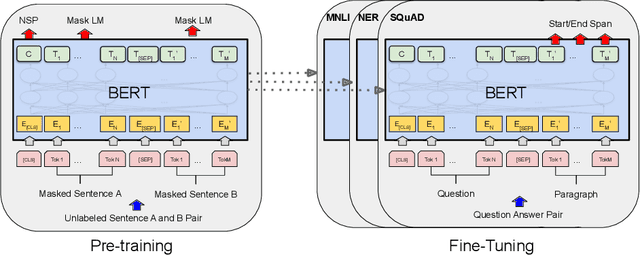

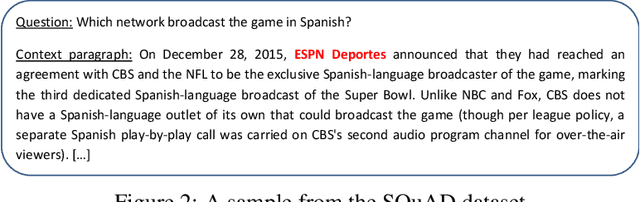
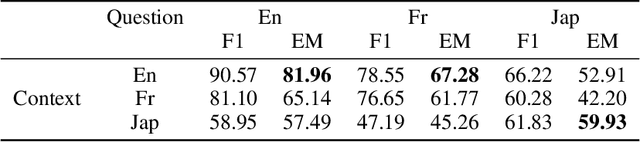
Recent advances in NLP with language models such as BERT, GPT-2, XLNet or XLM, have allowed surpassing human performance on Reading Comprehension tasks on large-scale datasets (e.g. SQuAD), and this opens up many perspectives for Conversational AI. However, task-specific datasets are mostly in English which makes it difficult to acknowledge progress in foreign languages. Fortunately, state-of-the-art models are now being pre-trained on multiple languages (e.g. BERT was released in a multilingual version managing a hundred languages) and are exhibiting ability for zero-shot transfer from English to others languages on XNLI. In this paper, we run experiments that show that multilingual BERT, trained to solve the complex Question Answering task defined in the English SQuAD dataset, is able to achieve the same task in Japanese and French. It even outperforms the best published results of a baseline which explicitly combines an English model for Reading Comprehension and a Machine Translation Model for transfer. We run further tests on crafted cross-lingual QA datasets (context in one language and question in another) to provide intuition on the mechanisms that allow BERT to transfer the task from one language to another. Finally, we introduce our application Kate. Kate is a conversational agent dedicated to HR support for employees that exploits multilingual models to accurately answer to questions, in several languages, directly from information web pages.
Master your Metrics with Calibration
Sep 06, 2019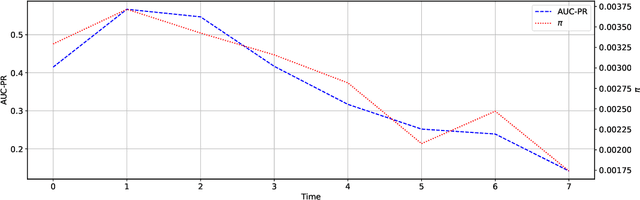
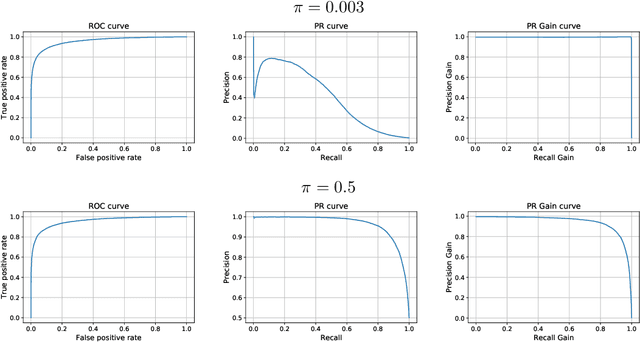
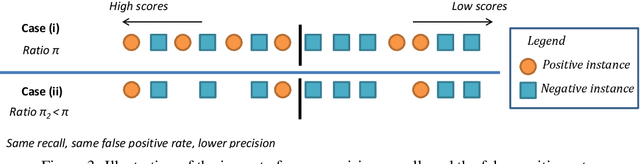
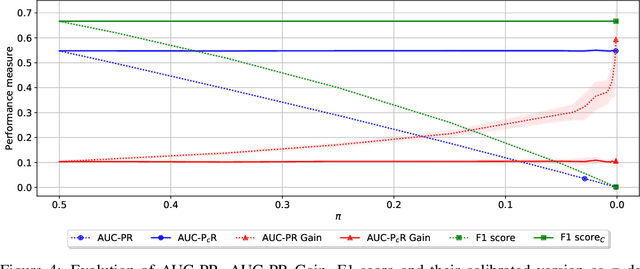
Machine learning models deployed in real-world applications are often evaluated with precision-based metrics such as F1-score or AUC-PR (Area Under the Curve of Precision Recall). Heavily dependent on the class prior, such metrics may sometimes lead to wrong conclusions about the performance. For example, when dealing with non-stationary data streams, they do not allow the user to discern the reasons why a model performance varies across different periods. In this paper, we propose a way to calibrate the metrics so that they are no longer tied to the class prior. It corresponds to a readjustment, based on probabilities, to the value that the metric would have if the class prior was equal to a reference prior (user parameter). We conduct a large number of experiments on balanced and imbalanced data to assess the behavior of calibrated metrics and show that they improve interpretability and provide a better control over what is really measured. We describe specific real-world use-cases where calibration is beneficial such as, for instance, model monitoring in production, reporting, or fairness evaluation.