 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtending the Massive Text Embedding Benchmark to French
Paper and Code
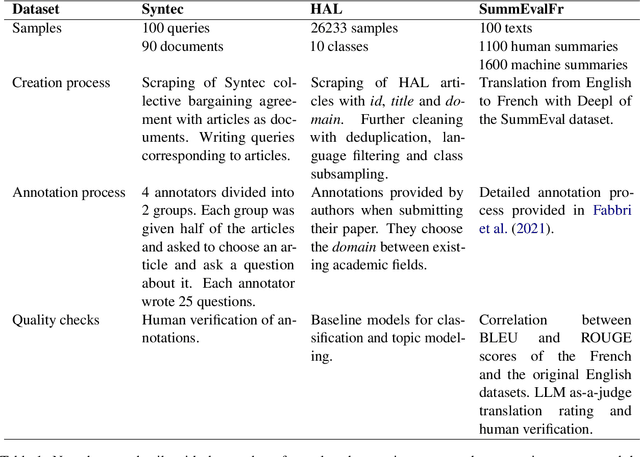
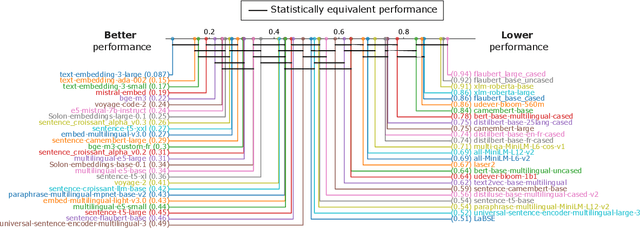
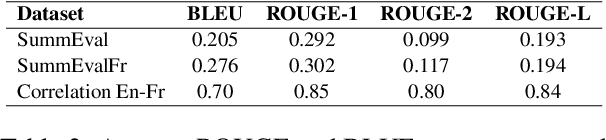
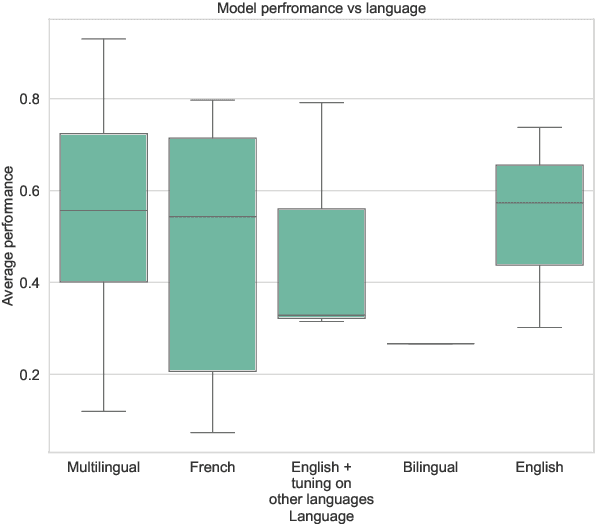
In recent years, numerous embedding models have been made available and widely used for various NLP tasks. Choosing a model that performs well for several tasks in English has been largely simplified by the Massive Text Embedding Benchmark (MTEB), but extensions to other languages remain challenging. This is why we expand MTEB to propose the first massive benchmark of sentence embeddings for French. Not only we gather 22 existing datasets in an easy-to-use interface, but we also create three new French datasets for a global evaluation over 8 different tasks. We perform a large scale comparison with 46 carefully selected embedding models, conduct comprehensive statistical tests, and analyze the correlation between model performance and many of their characteristics. We find out that even if no model is the best on all tasks, large multilingual models pre-trained on sentence similarity perform particularly well. Our work comes with open-source code, new datasets and a public leaderboard.