 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDelaying Interaction Layers in Transformer-based Encoders for Efficient Open Domain Question Answering
Oct 16, 2020



Open Domain Question Answering (ODQA) on a large-scale corpus of documents (e.g. Wikipedia) is a key challenge in computer science. Although transformer-based language models such as Bert have shown on SQuAD the ability to surpass humans for extracting answers in small passages of text, they suffer from their high complexity when faced to a much larger search space. The most common way to tackle this problem is to add a preliminary Information Retrieval step to heavily filter the corpus and only keep the relevant passages. In this paper, we propose a more direct and complementary solution which consists in applying a generic change in the architecture of transformer-based models to delay the attention between subparts of the input and allow a more efficient management of computations. The resulting variants are competitive with the original models on the extractive task and allow, on the ODQA setting, a significant speedup and even a performance improvement in many cases.
Multilingual Question Answering from Formatted Text applied to Conversational Agents
Oct 10, 2019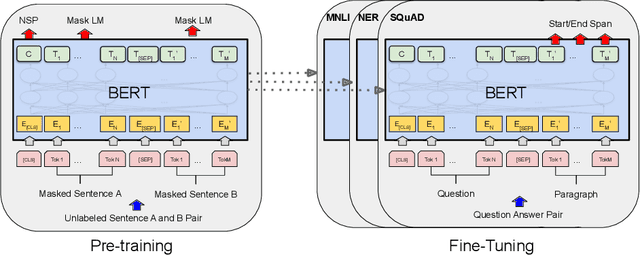

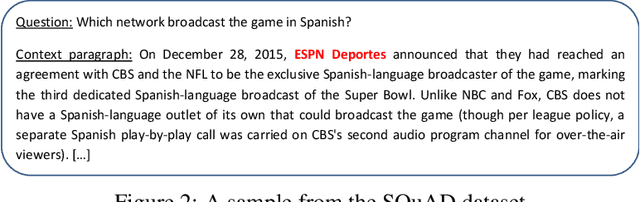
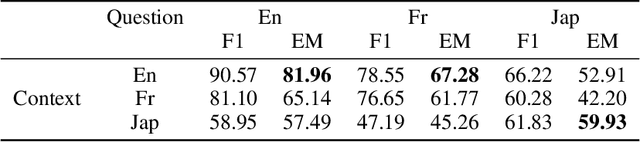
Recent advances in NLP with language models such as BERT, GPT-2, XLNet or XLM, have allowed surpassing human performance on Reading Comprehension tasks on large-scale datasets (e.g. SQuAD), and this opens up many perspectives for Conversational AI. However, task-specific datasets are mostly in English which makes it difficult to acknowledge progress in foreign languages. Fortunately, state-of-the-art models are now being pre-trained on multiple languages (e.g. BERT was released in a multilingual version managing a hundred languages) and are exhibiting ability for zero-shot transfer from English to others languages on XNLI. In this paper, we run experiments that show that multilingual BERT, trained to solve the complex Question Answering task defined in the English SQuAD dataset, is able to achieve the same task in Japanese and French. It even outperforms the best published results of a baseline which explicitly combines an English model for Reading Comprehension and a Machine Translation Model for transfer. We run further tests on crafted cross-lingual QA datasets (context in one language and question in another) to provide intuition on the mechanisms that allow BERT to transfer the task from one language to another. Finally, we introduce our application Kate. Kate is a conversational agent dedicated to HR support for employees that exploits multilingual models to accurately answer to questions, in several languages, directly from information web pages.