 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaster your Metrics with Calibration
Sep 06, 2019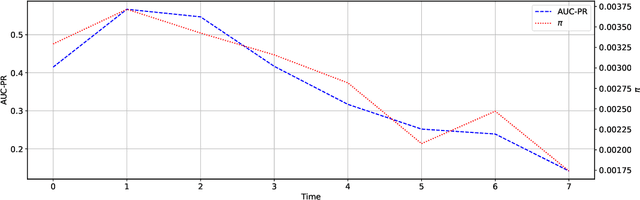
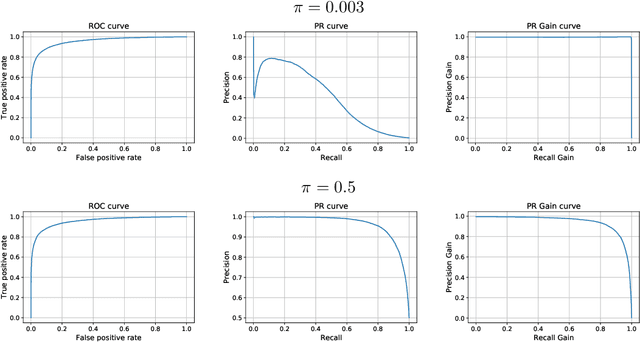
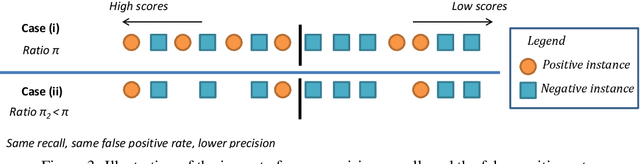
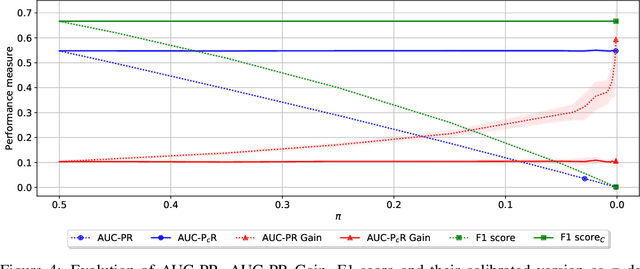
Machine learning models deployed in real-world applications are often evaluated with precision-based metrics such as F1-score or AUC-PR (Area Under the Curve of Precision Recall). Heavily dependent on the class prior, such metrics may sometimes lead to wrong conclusions about the performance. For example, when dealing with non-stationary data streams, they do not allow the user to discern the reasons why a model performance varies across different periods. In this paper, we propose a way to calibrate the metrics so that they are no longer tied to the class prior. It corresponds to a readjustment, based on probabilities, to the value that the metric would have if the class prior was equal to a reference prior (user parameter). We conduct a large number of experiments on balanced and imbalanced data to assess the behavior of calibrated metrics and show that they improve interpretability and provide a better control over what is really measured. We describe specific real-world use-cases where calibration is beneficial such as, for instance, model monitoring in production, reporting, or fairness evaluation.
Adversarial confidence and smoothness regularizations for scalable unsupervised discriminative learning
Jun 04, 2018
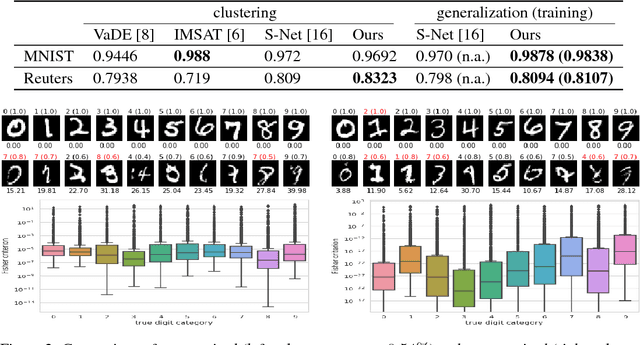


In this paper, we consider a generic probabilistic discriminative learner from the functional viewpoint and argue that, to make it learn well, it is necessary to constrain its hypothesis space to a set of non-trivial piecewise constant functions. To achieve this goal, we present a scalable unsupervised regularization framework. On the theoretical front, we prove that this framework is conducive to a factually confident and smooth discriminative model and connect it to an adversarial Taboo game, spectral clustering and virtual adversarial training. Experimentally, we take deep neural networks as our learners and demonstrate that, when trained under our framework in the unsupervised setting, they not only achieve state-of-the-art clustering results but also generalize well on both synthetic and real data.