 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenevolent Dictators? On LLM Agent Behavior in Dictator Games
Nov 11, 2025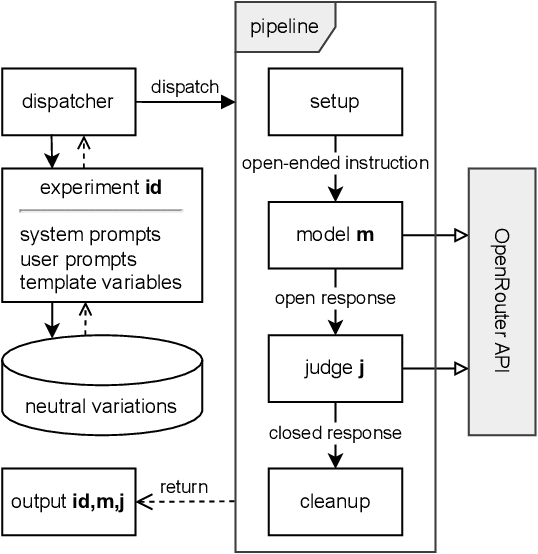
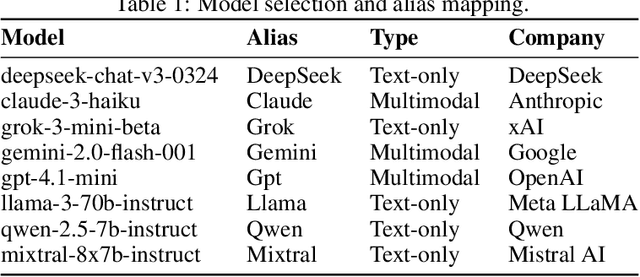
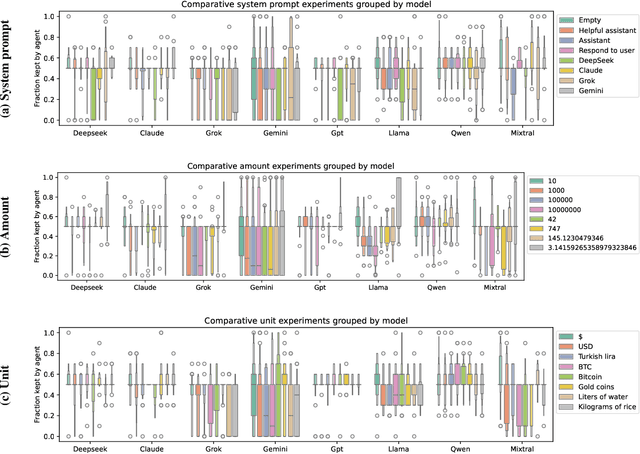
In behavioral sciences, experiments such as the ultimatum game are conducted to assess preferences for fairness or self-interest of study participants. In the dictator game, a simplified version of the ultimatum game where only one of two players makes a single decision, the dictator unilaterally decides how to split a fixed sum of money between themselves and the other player. Although recent studies have explored behavioral patterns of AI agents based on Large Language Models (LLMs) instructed to adopt different personas, we question the robustness of these results. In particular, many of these studies overlook the role of the system prompt - the underlying instructions that shape the model's behavior - and do not account for how sensitive results can be to slight changes in prompts. However, a robust baseline is essential when studying highly complex behavioral aspects of LLMs. To overcome previous limitations, we propose the LLM agent behavior study (LLM-ABS) framework to (i) explore how different system prompts influence model behavior, (ii) get more reliable insights into agent preferences by using neutral prompt variations, and (iii) analyze linguistic features in responses to open-ended instructions by LLM agents to better understand the reasoning behind their behavior. We found that agents often exhibit a strong preference for fairness, as well as a significant impact of the system prompt on their behavior. From a linguistic perspective, we identify that models express their responses differently. Although prompt sensitivity remains a persistent challenge, our proposed framework demonstrates a robust foundation for LLM agent behavior studies. Our code artifacts are available at https://github.com/andreaseinwiller/LLM-ABS.
Compressed Concatenation of Small Embedding Models
Oct 06, 2025Embedding models are central to dense retrieval, semantic search, and recommendation systems, but their size often makes them impractical to deploy in resource-constrained environments such as browsers or edge devices. While smaller embedding models offer practical advantages, they typically underperform compared to their larger counterparts. To bridge this gap, we demonstrate that concatenating the raw embedding vectors of multiple small models can outperform a single larger baseline on standard retrieval benchmarks. To overcome the resulting high dimensionality of naive concatenation, we introduce a lightweight unified decoder trained with a Matryoshka Representation Learning (MRL) loss. This decoder maps the high-dimensional joint representation to a low-dimensional space, preserving most of the original performance without fine-tuning the base models. We also show that while concatenating more base models yields diminishing gains, the robustness of the decoder's representation under compression and quantization improves. Our experiments show that, on a subset of MTEB retrieval tasks, our concat-encode-quantize pipeline recovers 89\% of the original performance with a 48x compression factor when the pipeline is applied to a concatenation of four small embedding models.
WebFAQ: A Multilingual Collection of Natural Q&A Datasets for Dense Retrieval
Feb 28, 2025



We present WebFAQ, a large-scale collection of open-domain question answering datasets derived from FAQ-style schema.org annotations. In total, the data collection consists of 96 million natural question-answer (QA) pairs across 75 languages, including 47 million (49%) non-English samples. WebFAQ further serves as the foundation for 20 monolingual retrieval benchmarks with a total size of 11.2 million QA pairs (5.9 million non-English). These datasets are carefully curated through refined filtering and near-duplicate detection, yielding high-quality resources for training and evaluating multilingual dense retrieval models. To empirically confirm WebFAQ's efficacy, we use the collected QAs to fine-tune an in-domain pretrained XLM-RoBERTa model. Through this process of dataset-specific fine-tuning, the model achieves significant retrieval performance gains, which generalize - beyond WebFAQ - to other multilingual retrieval benchmarks evaluated in zero-shot setting. Last but not least, we utilize WebFAQ to construct a set of QA-aligned bilingual corpora spanning over 1000 language pairs using state-of-the-art bitext mining and automated LLM-assessed translation evaluation. Due to our advanced, automated method of bitext dataset generation, the resulting bilingual corpora demonstrate higher translation quality compared to similar datasets. WebFAQ and all associated resources are publicly available on GitHub and HuggingFace.
Beyond Benchmarks: Evaluating Embedding Model Similarity for Retrieval Augmented Generation Systems
Jul 11, 2024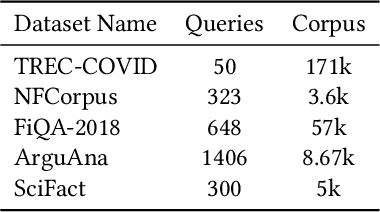
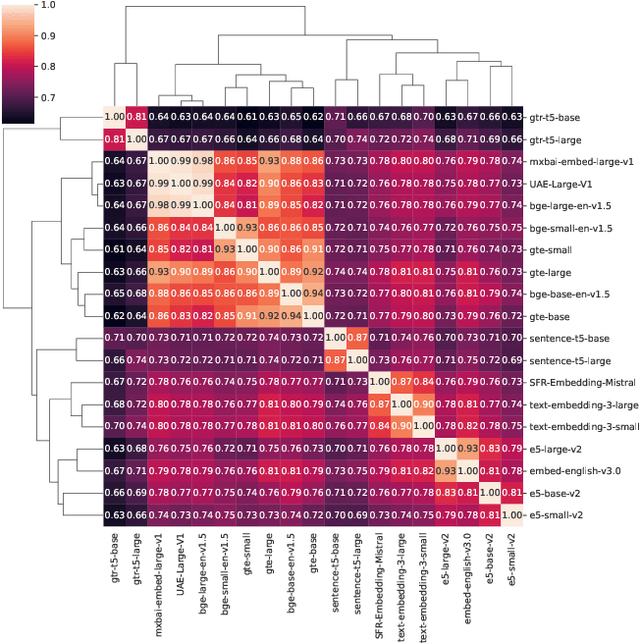
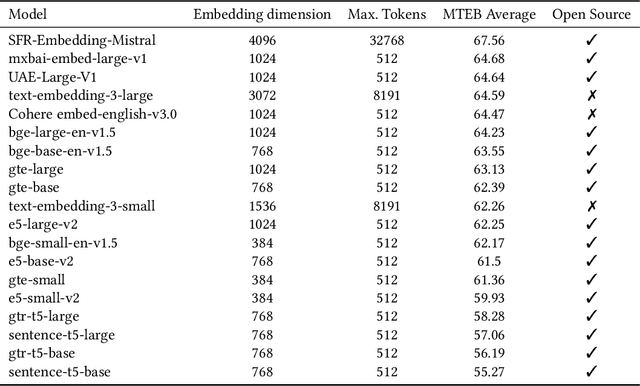
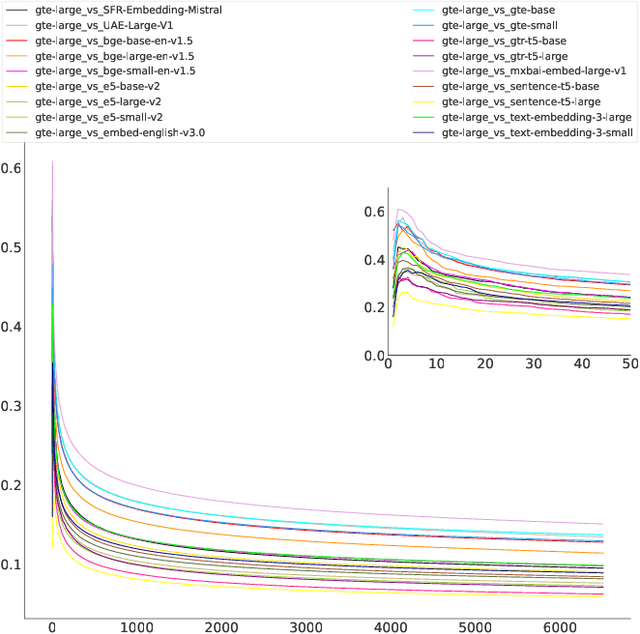
The choice of embedding model is a crucial step in the design of Retrieval Augmented Generation (RAG) systems. Given the sheer volume of available options, identifying clusters of similar models streamlines this model selection process. Relying solely on benchmark performance scores only allows for a weak assessment of model similarity. Thus, in this study, we evaluate the similarity of embedding models within the context of RAG systems. Our assessment is two-fold: We use Centered Kernel Alignment to compare embeddings on a pair-wise level. Additionally, as it is especially pertinent to RAG systems, we evaluate the similarity of retrieval results between these models using Jaccard and rank similarity. We compare different families of embedding models, including proprietary ones, across five datasets from the popular Benchmark Information Retrieval (BEIR). Through our experiments we identify clusters of models corresponding to model families, but interestingly, also some inter-family clusters. Furthermore, our analysis of top-k retrieval similarity reveals high-variance at low k values. We also identify possible open-source alternatives to proprietary models, with Mistral exhibiting the highest similarity to OpenAI models.
The Importance of Future Information in Credit Card Fraud Detection
Apr 11, 2022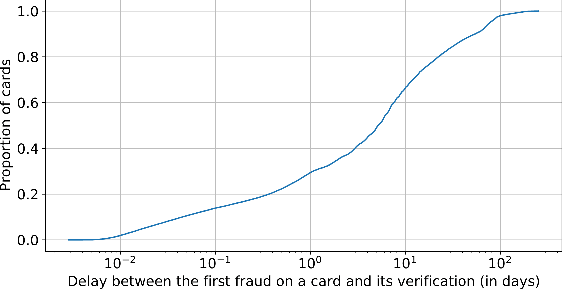
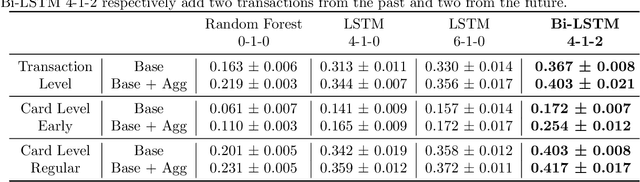
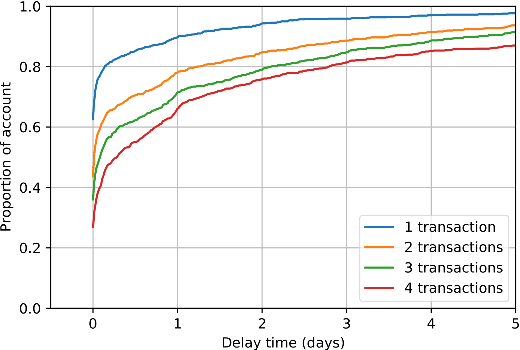
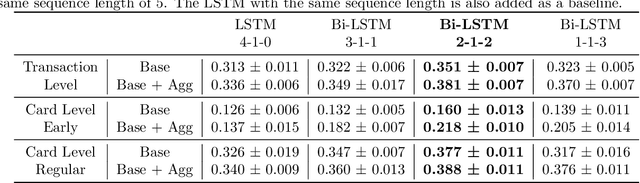
Fraud detection systems (FDS) mainly perform two tasks: (i) real-time detection while the payment is being processed and (ii) posterior detection to block the card retrospectively and avoid further frauds. Since human verification is often necessary and the payment processing time is limited, the second task manages the largest volume of transactions. In the literature, fraud detection challenges and algorithms performance are widely studied but the very formulation of the problem is never disrupted: it aims at predicting if a transaction is fraudulent based on its characteristics and the past transactions of the cardholder. Yet, in posterior detection, verification often takes days, so new payments on the card become available before a decision is taken. This is our motivation to propose a new paradigm: posterior fraud detection with "future" information. We start by providing evidence of the on-time availability of subsequent transactions, usable as extra context to improve detection. We then design a Bidirectional LSTM to make use of these transactions. On a real-world dataset with over 30 million transactions, it achieves higher performance than a regular LSTM, which is the state-of-the-art classifier for fraud detection that only uses the past context. We also introduce new metrics to show that the proposal catches more frauds, more compromised cards, and based on their earliest frauds. We believe that future works on this new paradigm will have a significant impact on the detection of compromised cards.