 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParallel Universes, Parallel Languages: A Comprehensive Study on LLM-based Multilingual Counterfactual Example Generation
Jan 01, 2026Counterfactuals refer to minimally edited inputs that cause a model's prediction to change, serving as a promising approach to explaining the model's behavior. Large language models (LLMs) excel at generating English counterfactuals and demonstrate multilingual proficiency. However, their effectiveness in generating multilingual counterfactuals remains unclear. To this end, we conduct a comprehensive study on multilingual counterfactuals. We first conduct automatic evaluations on both directly generated counterfactuals in the target languages and those derived via English translation across six languages. Although translation-based counterfactuals offer higher validity than their directly generated counterparts, they demand substantially more modifications and still fall short of matching the quality of the original English counterfactuals. Second, we find the patterns of edits applied to high-resource European-language counterfactuals to be remarkably similar, suggesting that cross-lingual perturbations follow common strategic principles. Third, we identify and categorize four main types of errors that consistently appear in the generated counterfactuals across languages. Finally, we reveal that multilingual counterfactual data augmentation (CDA) yields larger model performance improvements than cross-lingual CDA, especially for lower-resource languages. Yet, the imperfections of the generated counterfactuals limit gains in model performance and robustness.
Truth or Twist? Optimal Model Selection for Reliable Label Flipping Evaluation in LLM-based Counterfactuals
May 20, 2025Counterfactual examples are widely employed to enhance the performance and robustness of large language models (LLMs) through counterfactual data augmentation (CDA). However, the selection of the judge model used to evaluate label flipping, the primary metric for assessing the validity of generated counterfactuals for CDA, yields inconsistent results. To decipher this, we define four types of relationships between the counterfactual generator and judge models. Through extensive experiments involving two state-of-the-art LLM-based methods, three datasets, five generator models, and 15 judge models, complemented by a user study (n = 90), we demonstrate that judge models with an independent, non-fine-tuned relationship to the generator model provide the most reliable label flipping evaluations. Relationships between the generator and judge models, which are closely aligned with the user study for CDA, result in better model performance and robustness. Nevertheless, we find that the gap between the most effective judge models and the results obtained from the user study remains considerably large. This suggests that a fully automated pipeline for CDA may be inadequate and requires human intervention.
Guiding LLMs to Generate High-Fidelity and High-Quality Counterfactual Explanations for Text Classification
Mar 06, 2025The need for interpretability in deep learning has driven interest in counterfactual explanations, which identify minimal changes to an instance that change a model's prediction. Current counterfactual (CF) generation methods require task-specific fine-tuning and produce low-quality text. Large Language Models (LLMs), though effective for high-quality text generation, struggle with label-flipping counterfactuals (i.e., counterfactuals that change the prediction) without fine-tuning. We introduce two simple classifier-guided approaches to support counterfactual generation by LLMs, eliminating the need for fine-tuning while preserving the strengths of LLMs. Despite their simplicity, our methods outperform state-of-the-art counterfactual generation methods and are effective across different LLMs, highlighting the benefits of guiding counterfactual generation by LLMs with classifier information. We further show that data augmentation by our generated CFs can improve a classifier's robustness. Our analysis reveals a critical issue in counterfactual generation by LLMs: LLMs rely on parametric knowledge rather than faithfully following the classifier.
LLMs for Generating and Evaluating Counterfactuals: A Comprehensive Study
Apr 26, 2024As NLP models become more complex, understanding their decisions becomes more crucial. Counterfactuals (CFs), where minimal changes to inputs flip a model's prediction, offer a way to explain these models. While Large Language Models (LLMs) have shown remarkable performance in NLP tasks, their efficacy in generating high-quality CFs remains uncertain. This work fills this gap by investigating how well LLMs generate CFs for two NLU tasks. We conduct a comprehensive comparison of several common LLMs, and evaluate their CFs, assessing both intrinsic metrics, and the impact of these CFs on data augmentation. Moreover, we analyze differences between human and LLM-generated CFs, providing insights for future research directions. Our results show that LLMs generate fluent CFs, but struggle to keep the induced changes minimal. Generating CFs for Sentiment Analysis (SA) is less challenging than NLI where LLMs show weaknesses in generating CFs that flip the original label. This also reflects on the data augmentation performance, where we observe a large gap between augmenting with human and LLMs CFs. Furthermore, we evaluate LLMs' ability to assess CFs in a mislabelled data setting, and show that they have a strong bias towards agreeing with the provided labels. GPT4 is more robust against this bias and its scores correlate well with automatic metrics. Our findings reveal several limitations and point to potential future work directions.
CEval: A Benchmark for Evaluating Counterfactual Text Generation
Apr 26, 2024Counterfactual text generation aims to minimally change a text, such that it is classified differently. Judging advancements in method development for counterfactual text generation is hindered by a non-uniform usage of data sets and metrics in related work. We propose CEval, a benchmark for comparing counterfactual text generation methods. CEval unifies counterfactual and text quality metrics, includes common counterfactual datasets with human annotations, standard baselines (MICE, GDBA, CREST) and the open-source language model LLAMA-2. Our experiments found no perfect method for generating counterfactual text. Methods that excel at counterfactual metrics often produce lower-quality text while LLMs with simple prompts generate high-quality text but struggle with counterfactual criteria. By making CEval available as an open-source Python library, we encourage the community to contribute more methods and maintain consistent evaluation in future work.
Explaining Machine Learning Models in Natural Conversations: Towards a Conversational XAI Agent
Sep 06, 2022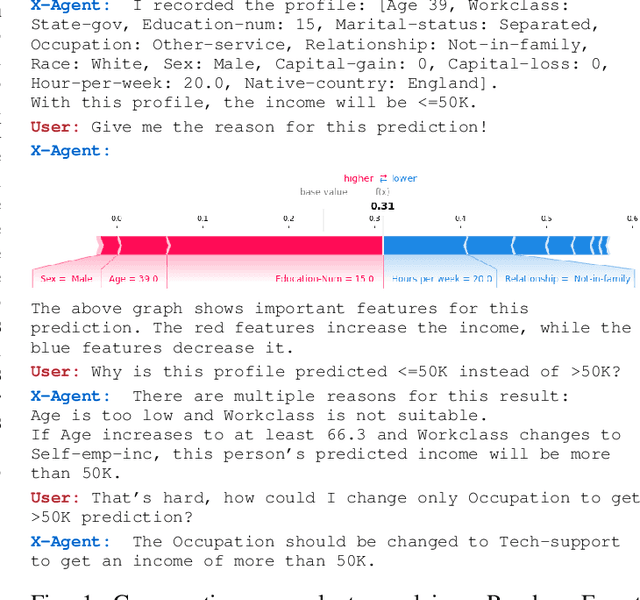
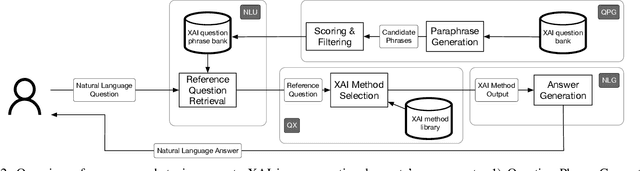


The goal of Explainable AI (XAI) is to design methods to provide insights into the reasoning process of black-box models, such as deep neural networks, in order to explain them to humans. Social science research states that such explanations should be conversational, similar to human-to-human explanations. In this work, we show how to incorporate XAI in a conversational agent, using a standard design for the agent comprising natural language understanding and generation components. We build upon an XAI question bank which we extend by quality-controlled paraphrases to understand the user's information needs. We further systematically survey the literature for suitable explanation methods that provide the information to answer those questions, and present a comprehensive list of suggestions. Our work is the first step towards truly natural conversations about machine learning models with an explanation agent. The comprehensive list of XAI questions and the corresponding explanation methods may support other researchers in providing the necessary information to address users' demands.
The Importance of Future Information in Credit Card Fraud Detection
Apr 11, 2022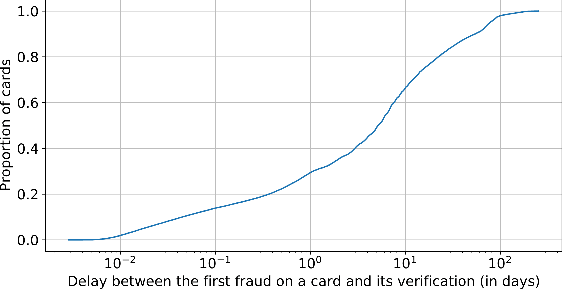
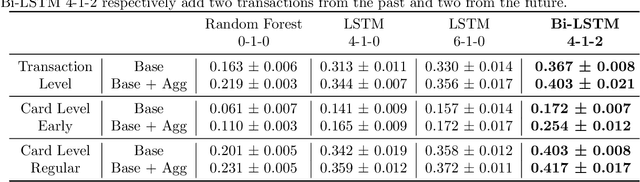
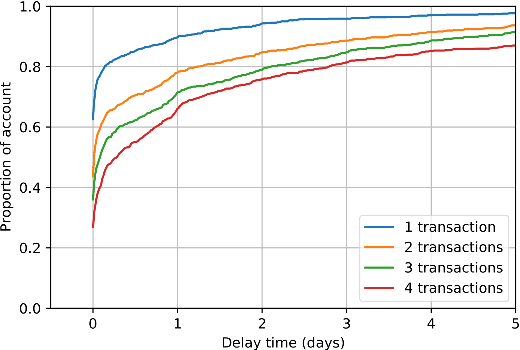
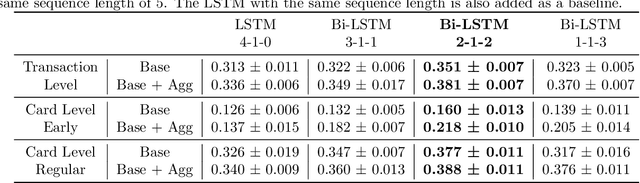
Fraud detection systems (FDS) mainly perform two tasks: (i) real-time detection while the payment is being processed and (ii) posterior detection to block the card retrospectively and avoid further frauds. Since human verification is often necessary and the payment processing time is limited, the second task manages the largest volume of transactions. In the literature, fraud detection challenges and algorithms performance are widely studied but the very formulation of the problem is never disrupted: it aims at predicting if a transaction is fraudulent based on its characteristics and the past transactions of the cardholder. Yet, in posterior detection, verification often takes days, so new payments on the card become available before a decision is taken. This is our motivation to propose a new paradigm: posterior fraud detection with "future" information. We start by providing evidence of the on-time availability of subsequent transactions, usable as extra context to improve detection. We then design a Bidirectional LSTM to make use of these transactions. On a real-world dataset with over 30 million transactions, it achieves higher performance than a regular LSTM, which is the state-of-the-art classifier for fraud detection that only uses the past context. We also introduce new metrics to show that the proposal catches more frauds, more compromised cards, and based on their earliest frauds. We believe that future works on this new paradigm will have a significant impact on the detection of compromised cards.
Policy Learning for Malaria Control
Oct 20, 2019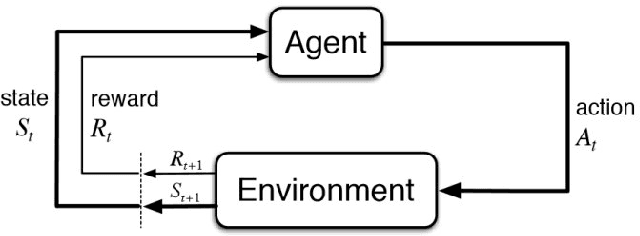
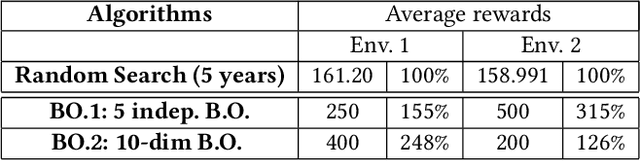
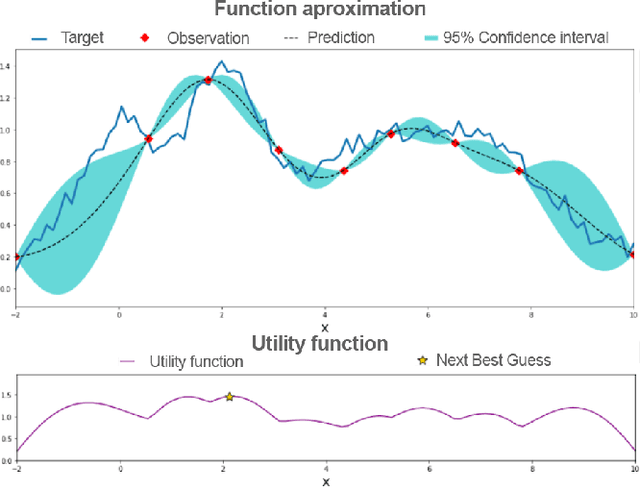

Sequential decision making is a typical problem in reinforcement learning with plenty of algorithms to solve it. However, only a few of them can work effectively with a very small number of observations. In this report, we introduce the progress to learn the policy for Malaria Control as a Reinforcement Learning problem in the KDD Cup Challenge 2019 and propose diverse solutions to deal with the limited observations problem. We apply the Genetic Algorithm, Bayesian Optimization, Q-learning with sequence breaking to find the optimal policy for five years in a row with only 20 episodes/100 evaluations. We evaluate those algorithms and compare their performance with Random Search as a baseline. Among these algorithms, Q-Learning with sequence breaking has been submitted to the challenge and got ranked 7th in KDD Cup.