 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTruth or Twist? Optimal Model Selection for Reliable Label Flipping Evaluation in LLM-based Counterfactuals
May 20, 2025Counterfactual examples are widely employed to enhance the performance and robustness of large language models (LLMs) through counterfactual data augmentation (CDA). However, the selection of the judge model used to evaluate label flipping, the primary metric for assessing the validity of generated counterfactuals for CDA, yields inconsistent results. To decipher this, we define four types of relationships between the counterfactual generator and judge models. Through extensive experiments involving two state-of-the-art LLM-based methods, three datasets, five generator models, and 15 judge models, complemented by a user study (n = 90), we demonstrate that judge models with an independent, non-fine-tuned relationship to the generator model provide the most reliable label flipping evaluations. Relationships between the generator and judge models, which are closely aligned with the user study for CDA, result in better model performance and robustness. Nevertheless, we find that the gap between the most effective judge models and the results obtained from the user study remains considerably large. This suggests that a fully automated pipeline for CDA may be inadequate and requires human intervention.
FitCF: A Framework for Automatic Feature Importance-guided Counterfactual Example Generation
Jan 01, 2025
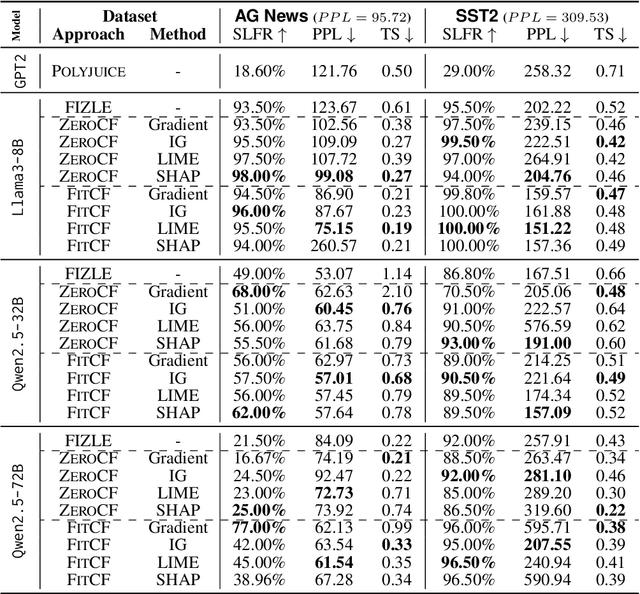
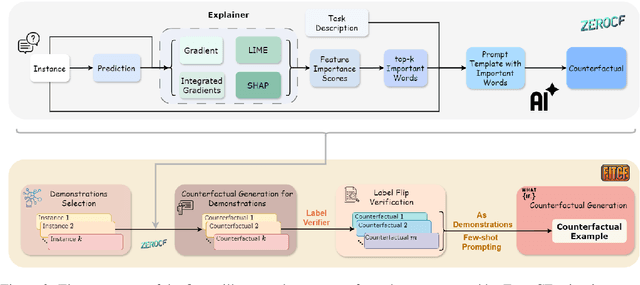
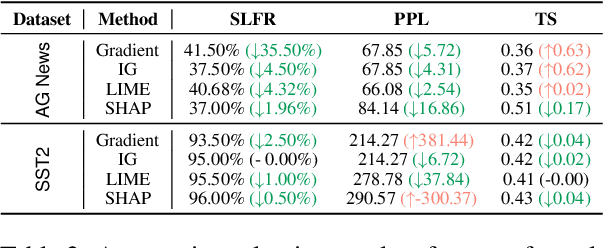
Counterfactual examples are widely used in natural language processing (NLP) as valuable data to improve models, and in explainable artificial intelligence (XAI) to understand model behavior. The automated generation of counterfactual examples remains a challenging task even for large language models (LLMs), despite their impressive performance on many tasks. In this paper, we first introduce ZeroCF, a faithful approach for leveraging important words derived from feature attribution methods to generate counterfactual examples in a zero-shot setting. Second, we present a new framework, FitCF, which further verifies aforementioned counterfactuals by label flip verification and then inserts them as demonstrations for few-shot prompting, outperforming two state-of-the-art baselines. Through ablation studies, we identify the importance of each of FitCF's core components in improving the quality of counterfactuals, as assessed through flip rate, perplexity, and similarity measures. Furthermore, we show the effectiveness of LIME and Integrated Gradients as backbone attribution methods for FitCF and find that the number of demonstrations has the largest effect on performance. Finally, we reveal a strong correlation between the faithfulness of feature attribution scores and the quality of generated counterfactuals.
Anchored Alignment for Self-Explanations Enhancement
Oct 17, 2024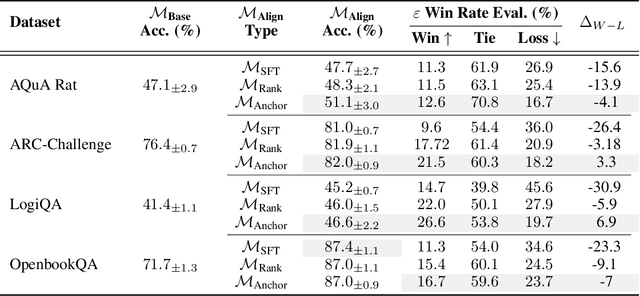
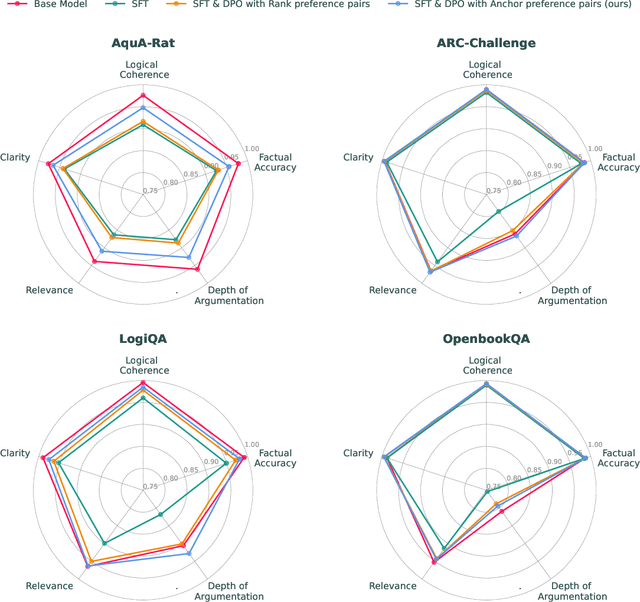
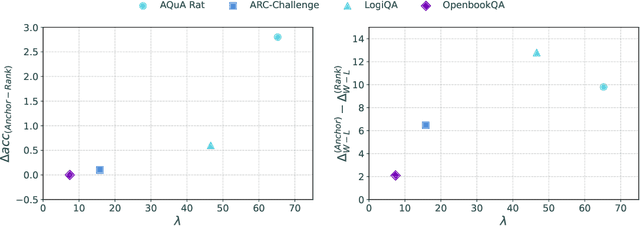
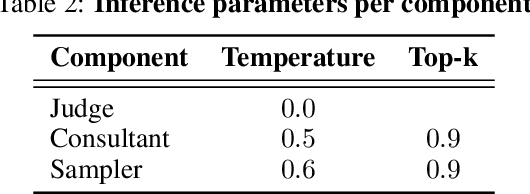
In this work, we introduce a methodology for alignment designed to enhance the ability of large language models (LLMs) to articulate their reasoning (self-explanation) even in the absence of annotated rationale explanations. Our alignment methodology comprises three key components: explanation quality assessment, self-instruction dataset generation, and model alignment. Additionally, we present a novel technique called Alignment with Anchor Preference Pairs, which improves the selection of preference pairs by categorizing model outputs into three groups: consistently correct, consistently incorrect, and variable. By applying tailored strategies to each category, we enhance the effectiveness of Direct Preference Optimization (DPO). Our experimental results demonstrate that this approach significantly improves explanation quality while maintaining accuracy compared to other fine-tuning strategies.