 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning with Hierarchical Prompting for Robust Propaganda Classification Across Annotation Schemas
May 13, 2026Propaganda detection in social media is challenging due to noisy, short texts and low annotation agreements. We introduce a new intent-focused taxonomy of propaganda techniques and compare it against an established, higher-agreement schema. Along three dimensions (model portfolio, schema effects, and prompting strategy) we evaluate the taxonomies as a classification task with the help of four language models (GPT-4.1-nano, Phi-4 14B, Qwen2.5-14B, Qwen3-14B). Our results show that fine-tuning is essential, since it transforms weak zero-shot baselines into competitive systems and reveals methodological differences that are hidden using base models. Across schemas, the Qwen models achieve the strongest overall performance, and Phi-4 14B consistently outperforms GPT-4.1-nano. Our hierarchical prompting method (HiPP), which predicts fine-grained techniques before aggregating them, is especially beneficial after fine-tuning and on the more ambiguous, low-agreement taxonomy, while remaining competitive on the simpler schema. The HQP dataset, annotated with the new intent-based labels, provides a richer lens on propaganda's strategic goals and a challenging benchmark for future work on robust, real-world detection.
From Articles to Premises: Building PrimeFacts, an Extraction Methodology and Resource for Fact-Checking Evidence
May 07, 2026Fact-checking articles encode rich supporting evidence and reasoning, yet this evidence remains largely inaccessible to automated verification systems due to unstructured presentation. We introduce PrimeFacts, a methodology and resource for extracting fine-grained evidence from full fact-checking articles. We compile 13,106 PolitiFact articles with claims, verdicts, and all referenced sources, and we identify 49,718 in-article hyperlinks as natural anchors to pinpoint key evidence. Our framework leverages large language models (LLMs) to rewrite these anchor sentences into stand-alone, context-independent premises and investigates the extraction of additional implicit evidence. In evaluations on cross-article evidence retrieval and claim verification, the extracted premises substantially improve performance. Decontextualized evidence yields higher retrievability, achieving up to a 30 percent relative gain in Mean Reciprocal Rank over verbatim sentences, and using the evidence for verdict prediction raises Macro-F1 by 10-20 points over the baseline. These gains are consistent across different verdict granularities (2-class vs. 5-class) and model architectures. A qualitative analysis indicates that the decontextualized premises remain faithful to the original sources. Our work highlights the promise of reusing fact-checkers' evidence for automation and provides a large-scale resource of structured evidence from real-world fact-checks.
MultiGraSCCo: A Multilingual Anonymization Benchmark with Annotations of Personal Identifiers
Mar 11, 2026Accessing sensitive patient data for machine learning is challenging due to privacy concerns. Datasets with annotations of personally identifiable information are crucial for developing and testing anonymization systems to enable safe data sharing that complies with privacy regulations. Since accessing real patient data is a bottleneck, synthetic data offers an efficient solution for data scarcity, bypassing privacy regulations that apply to real data. Moreover, neural machine translation can help to create high-quality data for low-resource languages by translating validated real or synthetic data from a high-resource language. In this work, we create a multilingual anonymization benchmark in ten languages, using a machine translation methodology that preserves the original annotations and renders names of cities and people in a culturally and contextually appropriate form in each target language. Our evaluation study with medical professionals confirms the quality of the translations, both in general and with respect to the translation and adaptation of personal information. Our benchmark with over 2,500 annotations of personal information can be used in many applications, including training annotators, validating annotations across institutions without legal complications, and helping improve the performance of automatic personal information detection. We make our benchmark and annotation guidelines available for further research.
Content Leakage in LibriSpeech and Its Impact on the Privacy Evaluation of Speaker Anonymization
Jan 19, 2026Speaker anonymization aims to conceal a speaker's identity, without considering the linguistic content. In this study, we reveal a weakness of Librispeech, the dataset that is commonly used to evaluate anonymizers: the books read by the Librispeech speakers are so distinct, that speakers can be identified by their vocabularies. Even perfect anonymizers cannot prevent this identity leakage. The EdAcc dataset is better in this regard: only a few speakers can be identified through their vocabularies, encouraging the attacker to look elsewhere for the identities of the anonymized speakers. EdAcc also comprises spontaneous speech and more diverse speakers, complementing Librispeech and giving more insights into how anonymizers work.
Order in the Evaluation Court: A Critical Analysis of NLG Evaluation Trends
Jan 12, 2026Despite advances in Natural Language Generation (NLG), evaluation remains challenging. Although various new metrics and LLM-as-a-judge (LaaJ) methods are proposed, human judgment persists as the gold standard. To systematically review how NLG evaluation has evolved, we employ an automatic information extraction scheme to gather key information from NLG papers, focusing on different evaluation methods (metrics, LaaJ and human evaluation). With extracted metadata from 14,171 papers across four major conferences (ACL, EMNLP, NAACL, and INLG) over the past six years, we reveal several critical findings: (1) Task Divergence: While Dialogue Generation demonstrates a rapid shift toward LaaJ (>40% in 2025), Machine Translation remains locked into n-gram metrics, and Question Answering exhibits a substantial decline in the proportion of studies conducting human evaluation. (2) Metric Inertia: Despite the development of semantic metrics, general-purpose metrics (e.g., BLEU, ROUGE) continue to be widely used across tasks without empirical justification, often lacking the discriminative power to distinguish between specific quality criteria. (3) Human-LaaJ Divergence: Our association analysis challenges the assumption that LLMs act as mere proxies for humans; LaaJ and human evaluations prioritize very different signals, and explicit validation is scarce (<8% of papers comparing the two), with only moderate to low correlation. Based on these observations, we derive practical recommendations to improve the rigor of future NLG evaluation.
Parallel Universes, Parallel Languages: A Comprehensive Study on LLM-based Multilingual Counterfactual Example Generation
Jan 01, 2026Counterfactuals refer to minimally edited inputs that cause a model's prediction to change, serving as a promising approach to explaining the model's behavior. Large language models (LLMs) excel at generating English counterfactuals and demonstrate multilingual proficiency. However, their effectiveness in generating multilingual counterfactuals remains unclear. To this end, we conduct a comprehensive study on multilingual counterfactuals. We first conduct automatic evaluations on both directly generated counterfactuals in the target languages and those derived via English translation across six languages. Although translation-based counterfactuals offer higher validity than their directly generated counterparts, they demand substantially more modifications and still fall short of matching the quality of the original English counterfactuals. Second, we find the patterns of edits applied to high-resource European-language counterfactuals to be remarkably similar, suggesting that cross-lingual perturbations follow common strategic principles. Third, we identify and categorize four main types of errors that consistently appear in the generated counterfactuals across languages. Finally, we reveal that multilingual counterfactual data augmentation (CDA) yields larger model performance improvements than cross-lingual CDA, especially for lower-resource languages. Yet, the imperfections of the generated counterfactuals limit gains in model performance and robustness.
Can Large Language Models Still Explain Themselves? Investigating the Impact of Quantization on Self-Explanations
Jan 01, 2026Quantization is widely used to accelerate inference and streamline the deployment of large language models (LLMs), yet its effects on self-explanations (SEs) remain unexplored. SEs, generated by LLMs to justify their own outputs, require reasoning about the model's own decision-making process, a capability that may exhibit particular sensitivity to quantization. As SEs are increasingly relied upon for transparency in high-stakes applications, understanding whether and to what extent quantization degrades SE quality and faithfulness is critical. To address this gap, we examine two types of SEs: natural language explanations (NLEs) and counterfactual examples, generated by LLMs quantized using three common techniques at distinct bit widths. Our findings indicate that quantization typically leads to moderate declines in both SE quality (up to 4.4\%) and faithfulness (up to 2.38\%). The user study further demonstrates that quantization diminishes both the coherence and trustworthiness of SEs (up to 8.5\%). Compared to smaller models, larger models show limited resilience to quantization in terms of SE quality but better maintain faithfulness. Moreover, no quantization technique consistently excels across task accuracy, SE quality, and faithfulness. Given that quantization's impact varies by context, we recommend validating SE quality for specific use cases, especially for NLEs, which show greater sensitivity. Nonetheless, the relatively minor deterioration in SE quality and faithfulness does not undermine quantization's effectiveness as a model compression technique.
Multilingual Datasets for Custom Input Extraction and Explanation Requests Parsing in Conversational XAI Systems
Aug 20, 2025Conversational explainable artificial intelligence (ConvXAI) systems based on large language models (LLMs) have garnered considerable attention for their ability to enhance user comprehension through dialogue-based explanations. Current ConvXAI systems often are based on intent recognition to accurately identify the user's desired intention and map it to an explainability method. While such methods offer great precision and reliability in discerning users' underlying intentions for English, a significant challenge in the scarcity of training data persists, which impedes multilingual generalization. Besides, the support for free-form custom inputs, which are user-defined data distinct from pre-configured dataset instances, remains largely limited. To bridge these gaps, we first introduce MultiCoXQL, a multilingual extension of the CoXQL dataset spanning five typologically diverse languages, including one low-resource language. Subsequently, we propose a new parsing approach aimed at enhancing multilingual parsing performance, and evaluate three LLMs on MultiCoXQL using various parsing strategies. Furthermore, we present Compass, a new multilingual dataset designed for custom input extraction in ConvXAI systems, encompassing 11 intents across the same five languages as MultiCoXQL. We conduct monolingual, cross-lingual, and multilingual evaluations on Compass, employing three LLMs of varying sizes alongside BERT-type models.
The TUB Sign Language Corpus Collection
Aug 07, 2025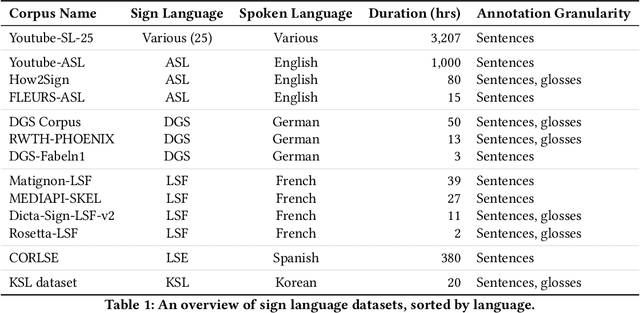
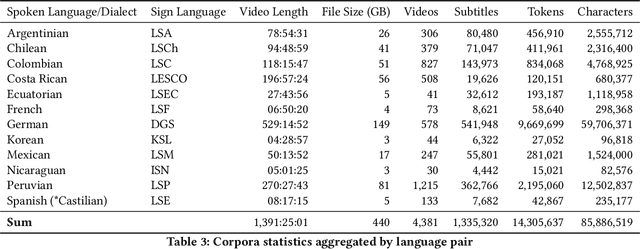
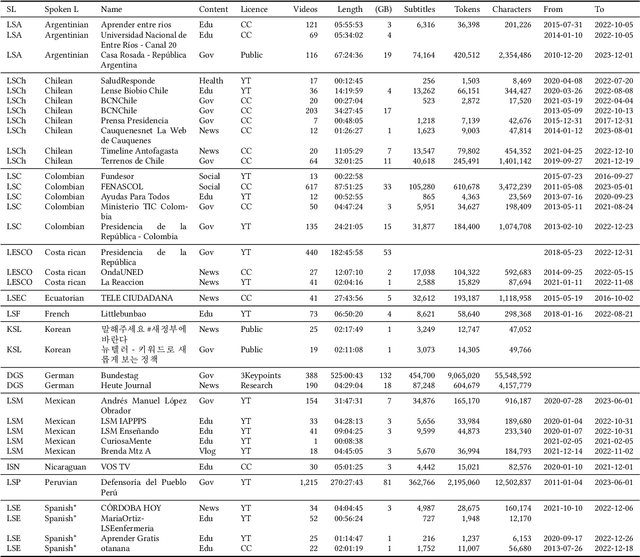
We present a collection of parallel corpora of 12 sign languages in video format, together with subtitles in the dominant spoken languages of the corresponding countries. The entire collection includes more than 1,300 hours in 4,381 video files, accompanied by 1,3~M subtitles containing 14~M tokens. Most notably, it includes the first consistent parallel corpora for 8 Latin American sign languages, whereas the size of the German Sign Language corpora is ten times the size of the previously available corpora. The collection was created by collecting and processing videos of multiple sign languages from various online sources, mainly broadcast material of news shows, governmental bodies and educational channels. The preparation involved several stages, including data collection, informing the content creators and seeking usage approvals, scraping, and cropping. The paper provides statistics on the collection and an overview of the methods used to collect the data.
Evaluation of a Sign Language Avatar on Comprehensibility, User Experience \& Acceptability
Aug 07, 2025This paper presents an investigation into the impact of adding adjustment features to an existing sign language (SL) avatar on a Microsoft Hololens 2 device. Through a detailed analysis of interactions of expert German Sign Language (DGS) users with both adjustable and non-adjustable avatars in a specific use case, this study identifies the key factors influencing the comprehensibility, the user experience (UX), and the acceptability of such a system. Despite user preference for adjustable settings, no significant improvements in UX or comprehensibility were observed, which remained at low levels, amid missing SL elements (mouthings and facial expressions) and implementation issues (indistinct hand shapes, lack of feedback and menu positioning). Hedonic quality was rated higher than pragmatic quality, indicating that users found the system more emotionally or aesthetically pleasing than functionally useful. Stress levels were higher for the adjustable avatar, reflecting lower performance, greater effort and more frustration. Additionally, concerns were raised about whether the Hololens adjustment gestures are intuitive and easy to familiarise oneself with. While acceptability of the concept of adjustability was generally positive, it was strongly dependent on usability and animation quality. This study highlights that personalisation alone is insufficient, and that SL avatars must be comprehensible by default. Key recommendations include enhancing mouthing and facial animation, improving interaction interfaces, and applying participatory design.