 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTemporal Fusion Nexus: A task-agnostic multi-modal embedding model for clinical narratives and irregular time series in post-kidney transplant care
Jan 13, 2026We introduce Temporal Fusion Nexus (TFN), a multi-modal and task-agnostic embedding model to integrate irregular time series and unstructured clinical narratives. We analysed TFN in post-kidney transplant (KTx) care, with a retrospective cohort of 3382 patients, on three key outcomes: graft loss, graft rejection, and mortality. Compared to state-of-the-art model in post KTx care, TFN achieved higher performance for graft loss (AUC 0.96 vs. 0.94) and graft rejection (AUC 0.84 vs. 0.74). In mortality prediction, TFN yielded an AUC of 0.86. TFN outperformed unimodal baselines (approx 10% AUC improvement over time series only baseline, approx 5% AUC improvement over time series with static patient data). Integrating clinical text improved performance across all tasks. Disentanglement metrics confirmed robust and interpretable latent factors in the embedding space, and SHAP-based attributions confirmed alignment with clinical reasoning. TFN has potential application in clinical tasks beyond KTx, where heterogeneous data sources, irregular longitudinal data, and rich narrative documentation are available.
One Size Fits None: Rethinking Fairness in Medical AI
Jun 17, 2025Machine learning (ML) models are increasingly used to support clinical decision-making. However, real-world medical datasets are often noisy, incomplete, and imbalanced, leading to performance disparities across patient subgroups. These differences raise fairness concerns, particularly when they reinforce existing disadvantages for marginalized groups. In this work, we analyze several medical prediction tasks and demonstrate how model performance varies with patient characteristics. While ML models may demonstrate good overall performance, we argue that subgroup-level evaluation is essential before integrating them into clinical workflows. By conducting a performance analysis at the subgroup level, differences can be clearly identified-allowing, on the one hand, for performance disparities to be considered in clinical practice, and on the other hand, for these insights to inform the responsible development of more effective models. Thereby, our work contributes to a practical discussion around the subgroup-sensitive development and deployment of medical ML models and the interconnectedness of fairness and transparency.
A Medical Information Extraction Workbench to Process German Clinical Text
Jul 08, 2022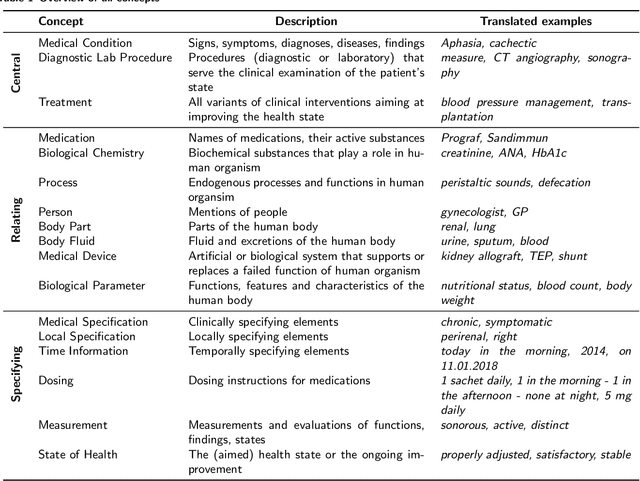
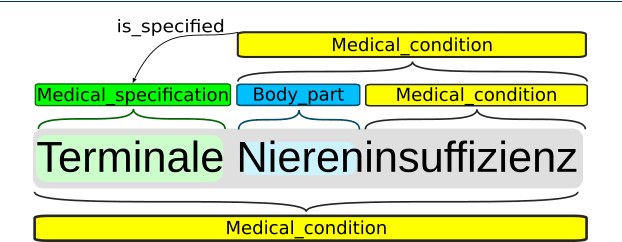

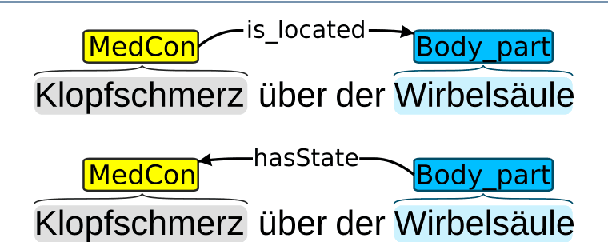
Background: In the information extraction and natural language processing domain, accessible datasets are crucial to reproduce and compare results. Publicly available implementations and tools can serve as benchmark and facilitate the development of more complex applications. However, in the context of clinical text processing the number of accessible datasets is scarce -- and so is the number of existing tools. One of the main reasons is the sensitivity of the data. This problem is even more evident for non-English languages. Approach: In order to address this situation, we introduce a workbench: a collection of German clinical text processing models. The models are trained on a de-identified corpus of German nephrology reports. Result: The presented models provide promising results on in-domain data. Moreover, we show that our models can be also successfully applied to other biomedical text in German. Our workbench is made publicly available so it can be used out of the box, as a benchmark or transferred to related problems.
When Performance is not Enough -- A Multidisciplinary View on Clinical Decision Support
Apr 27, 2022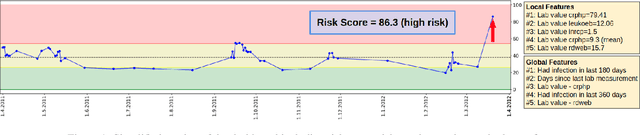
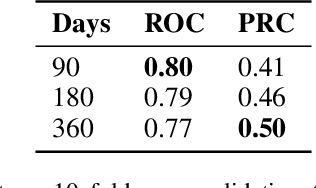
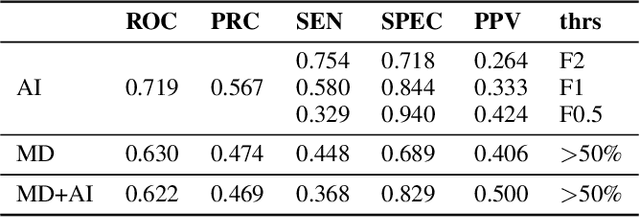

Scientific publications about machine learning in healthcare are often about implementing novel methods and boosting the performance - at least from a computer science perspective. However, beyond such often short-lived improvements, much more needs to be taken into consideration if we want to arrive at a sustainable progress in healthcare. What does it take to actually implement such a system, make it usable for the domain expert, and possibly bring it into practical usage? Targeted at Computer Scientists, this work presents a multidisciplinary view on machine learning in medical decision support systems and covers information technology, medical, as well as ethical aspects. Along with an implemented risk prediction system in nephrology, challenges and lessons learned in a pilot project are presented.
Clinical Outcome Prediction from Admission Notes using Self-Supervised Knowledge Integration
Feb 08, 2021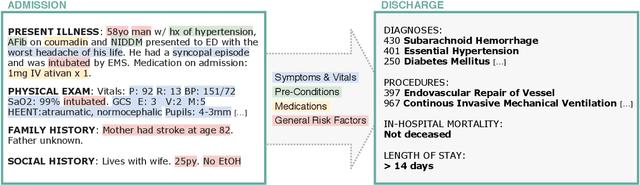
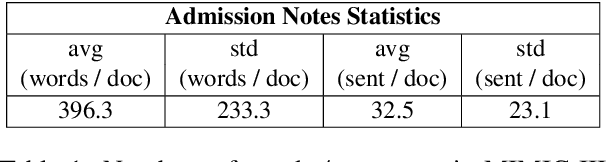

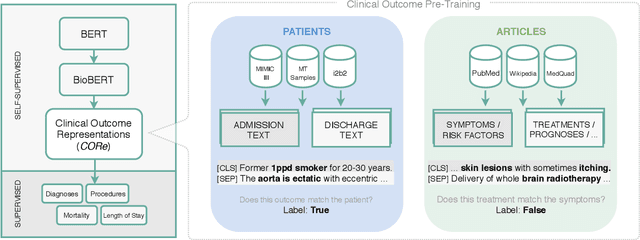
Outcome prediction from clinical text can prevent doctors from overlooking possible risks and help hospitals to plan capacities. We simulate patients at admission time, when decision support can be especially valuable, and contribute a novel admission to discharge task with four common outcome prediction targets: Diagnoses at discharge, procedures performed, in-hospital mortality and length-of-stay prediction. The ideal system should infer outcomes based on symptoms, pre-conditions and risk factors of a patient. We evaluate the effectiveness of language models to handle this scenario and propose clinical outcome pre-training to integrate knowledge about patient outcomes from multiple public sources. We further present a simple method to incorporate ICD code hierarchy into the models. We show that our approach improves performance on the outcome tasks against several baselines. A detailed analysis reveals further strengths of the model, including transferability, but also weaknesses such as handling of vital values and inconsistencies in the underlying data.
Towards a New Science of a Clinical Data Intelligence
Dec 30, 2013
In this paper we define Clinical Data Intelligence as the analysis of data generated in the clinical routine with the goal of improving patient care. We define a science of a Clinical Data Intelligence as a data analysis that permits the derivation of scientific, i.e., generalizable and reliable results. We argue that a science of a Clinical Data Intelligence is sensible in the context of a Big Data analysis, i.e., with data from many patients and with complete patient information. We discuss that Clinical Data Intelligence requires the joint efforts of knowledge engineering, information extraction (from textual and other unstructured data), and statistics and statistical machine learning. We describe some of our main results as conjectures and relate them to a recently funded research project involving two major German university hospitals.