 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Weight Imprinting: Insights from Neural Collapse and Proxy-Based Aggregation
Mar 18, 2025The capacity of a foundation model allows for adaptation to new downstream tasks. Weight imprinting is a universal and efficient method to fulfill this purpose. It has been reinvented several times, but it has not been systematically studied. In this paper, we propose a framework for imprinting, identifying three main components: generation, normalization, and aggregation. This allows us to conduct an in-depth analysis of imprinting and a comparison of the existing work. We reveal the benefits of representing novel data with multiple proxies in the generation step and show the importance of proper normalization. We determine those proxies through clustering and propose a novel variant of imprinting that outperforms previous work. We motivate this by the neural collapse phenomenon -- an important connection that we can draw for the first time. Our results show an increase of up to 4% in challenging scenarios with complex data distributions for new classes.
This Patient Looks Like That Patient: Prototypical Networks for Interpretable Diagnosis Prediction from Clinical Text
Oct 16, 2022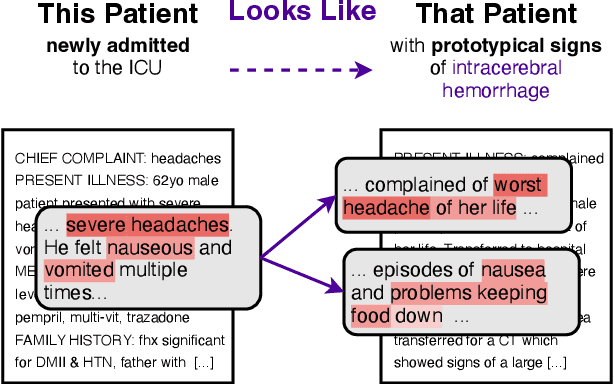
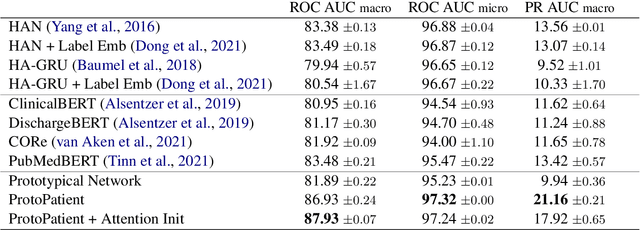

The use of deep neural models for diagnosis prediction from clinical text has shown promising results. However, in clinical practice such models must not only be accurate, but provide doctors with interpretable and helpful results. We introduce ProtoPatient, a novel method based on prototypical networks and label-wise attention with both of these abilities. ProtoPatient makes predictions based on parts of the text that are similar to prototypical patients - providing justifications that doctors understand. We evaluate the model on two publicly available clinical datasets and show that it outperforms existing baselines. Quantitative and qualitative evaluations with medical doctors further demonstrate that the model provides valuable explanations for clinical decision support.
Clinical Outcome Prediction from Admission Notes using Self-Supervised Knowledge Integration
Feb 08, 2021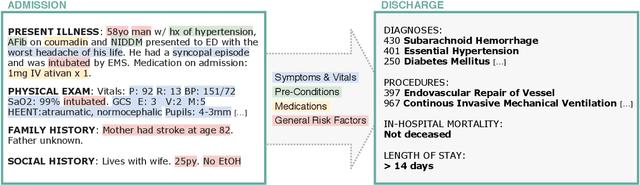
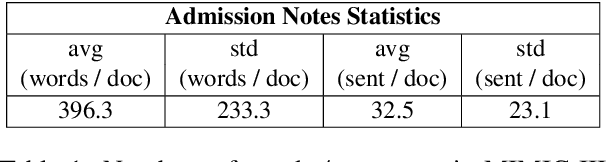

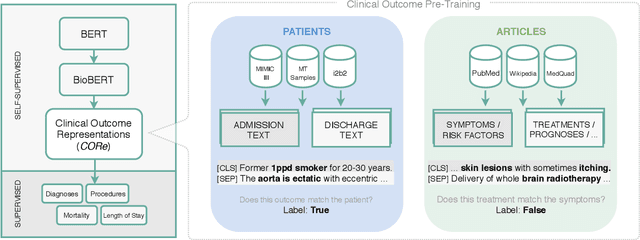
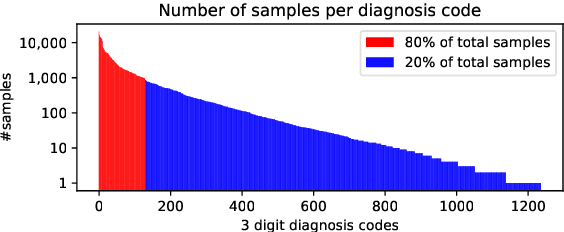
Outcome prediction from clinical text can prevent doctors from overlooking possible risks and help hospitals to plan capacities. We simulate patients at admission time, when decision support can be especially valuable, and contribute a novel admission to discharge task with four common outcome prediction targets: Diagnoses at discharge, procedures performed, in-hospital mortality and length-of-stay prediction. The ideal system should infer outcomes based on symptoms, pre-conditions and risk factors of a patient. We evaluate the effectiveness of language models to handle this scenario and propose clinical outcome pre-training to integrate knowledge about patient outcomes from multiple public sources. We further present a simple method to incorporate ICD code hierarchy into the models. We show that our approach improves performance on the outcome tasks against several baselines. A detailed analysis reveals further strengths of the model, including transferability, but also weaknesses such as handling of vital values and inconsistencies in the underlying data.
VisBERT: Hidden-State Visualizations for Transformers
Nov 09, 2020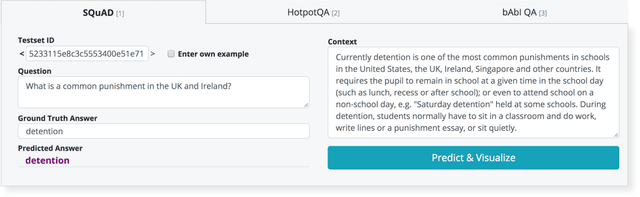
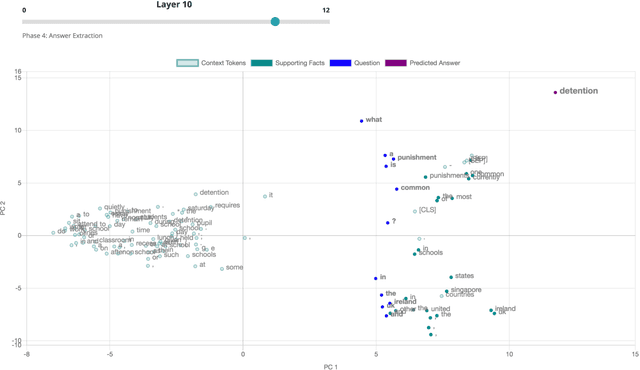
Explainability and interpretability are two important concepts, the absence of which can and should impede the application of well-performing neural networks to real-world problems. At the same time, they are difficult to incorporate into the large, black-box models that achieve state-of-the-art results in a multitude of NLP tasks. Bidirectional Encoder Representations from Transformers (BERT) is one such black-box model. It has become a staple architecture to solve many different NLP tasks and has inspired a number of related Transformer models. Understanding how these models draw conclusions is crucial for both their improvement and application. We contribute to this challenge by presenting VisBERT, a tool for visualizing the contextual token representations within BERT for the task of (multi-hop) Question Answering. Instead of analyzing attention weights, we focus on the hidden states resulting from each encoder block within the BERT model. This way we can observe how the semantic representations are transformed throughout the layers of the model. VisBERT enables users to get insights about the model's internal state and to explore its inference steps or potential shortcomings. The tool allows us to identify distinct phases in BERT's transformations that are similar to a traditional NLP pipeline and offer insights during failed predictions.
* Published in WWW '20: Companion Proceedings of the Web Conference 2020
Learning Contextualized Document Representations for Healthcare Answer Retrieval
Feb 03, 2020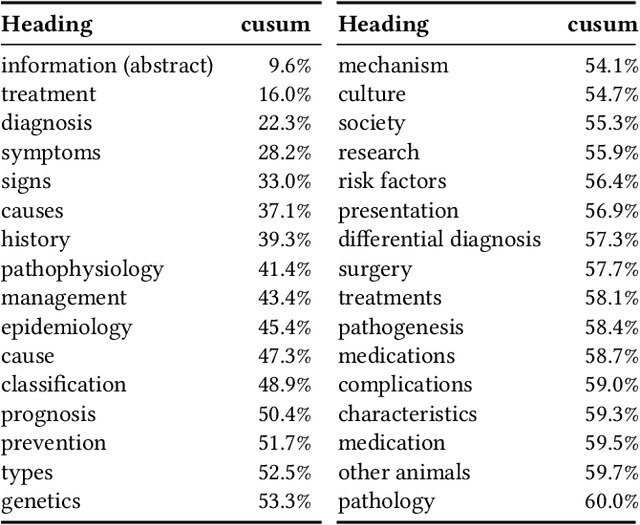
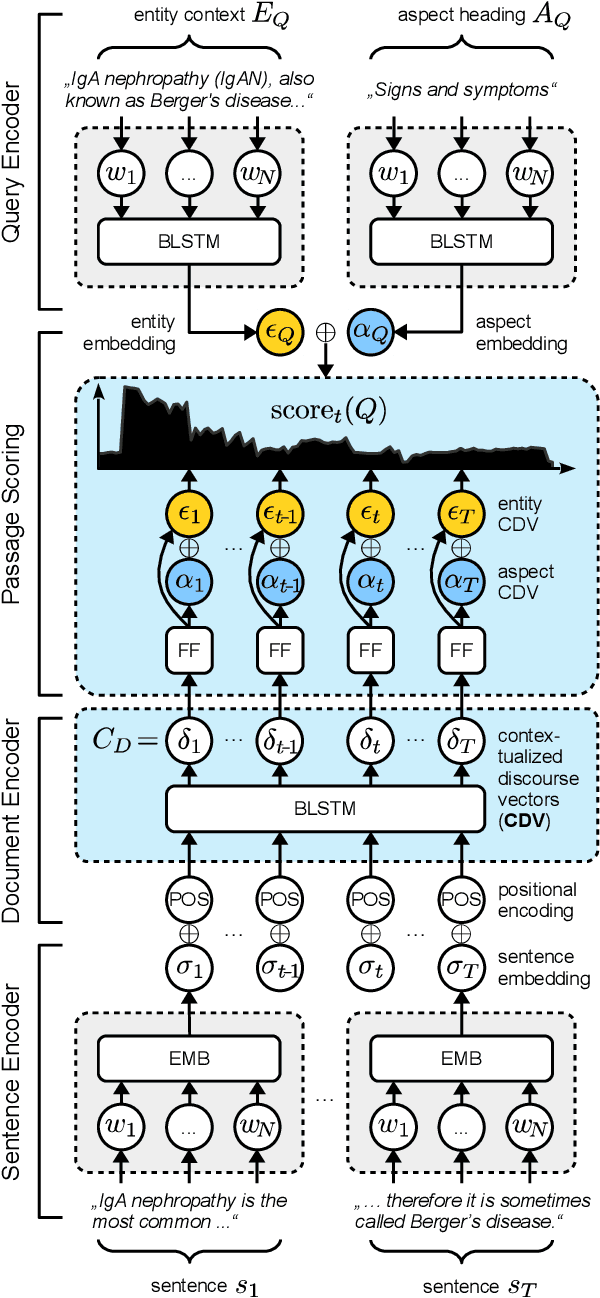
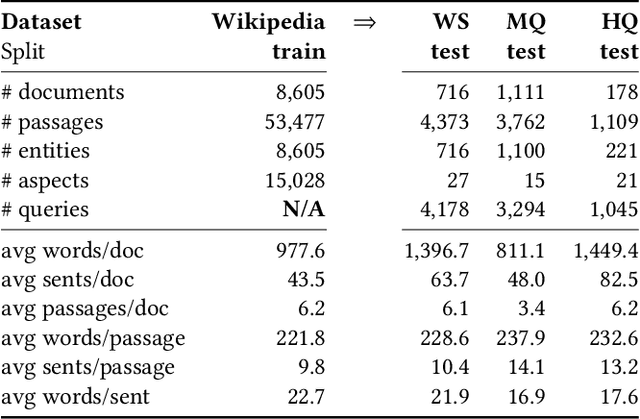
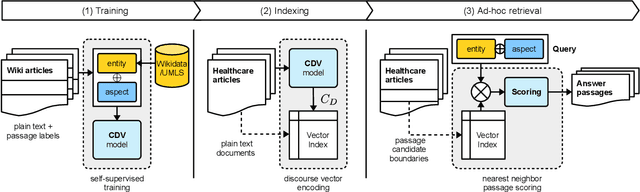
We present Contextual Discourse Vectors (CDV), a distributed document representation for efficient answer retrieval from long healthcare documents. Our approach is based on structured query tuples of entities and aspects from free text and medical taxonomies. Our model leverages a dual encoder architecture with hierarchical LSTM layers and multi-task training to encode the position of clinical entities and aspects alongside the document discourse. We use our continuous representations to resolve queries with short latency using approximate nearest neighbor search on sentence level. We apply the CDV model for retrieving coherent answer passages from nine English public health resources from the Web, addressing both patients and medical professionals. Because there is no end-to-end training data available for all application scenarios, we train our model with self-supervised data from Wikipedia. We show that our generalized model significantly outperforms several state-of-the-art baselines for healthcare passage ranking and is able to adapt to heterogeneous domains without additional fine-tuning.
How Does BERT Answer Questions? A Layer-Wise Analysis of Transformer Representations
Sep 11, 2019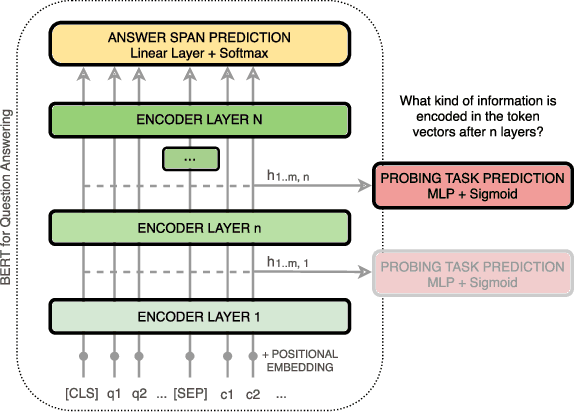


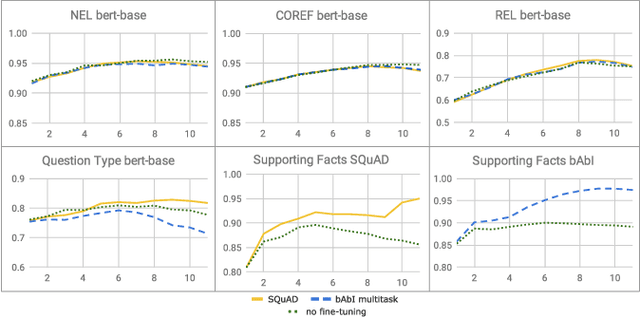
Bidirectional Encoder Representations from Transformers (BERT) reach state-of-the-art results in a variety of Natural Language Processing tasks. However, understanding of their internal functioning is still insufficient and unsatisfactory. In order to better understand BERT and other Transformer-based models, we present a layer-wise analysis of BERT's hidden states. Unlike previous research, which mainly focuses on explaining Transformer models by their attention weights, we argue that hidden states contain equally valuable information. Specifically, our analysis focuses on models fine-tuned on the task of Question Answering (QA) as an example of a complex downstream task. We inspect how QA models transform token vectors in order to find the correct answer. To this end, we apply a set of general and QA-specific probing tasks that reveal the information stored in each representation layer. Our qualitative analysis of hidden state visualizations provides additional insights into BERT's reasoning process. Our results show that the transformations within BERT go through phases that are related to traditional pipeline tasks. The system can therefore implicitly incorporate task-specific information into its token representations. Furthermore, our analysis reveals that fine-tuning has little impact on the models' semantic abilities and that prediction errors can be recognized in the vector representations of even early layers.
SECTOR: A Neural Model for Coherent Topic Segmentation and Classification
Feb 13, 2019When searching for information, a human reader first glances over a document, spots relevant sections and then focuses on a few sentences for resolving her intention. However, the high variance of document structure complicates to identify the salient topic of a given section at a glance. To tackle this challenge, we present SECTOR, a model to support machine reading systems by segmenting documents into coherent sections and assigning topic labels to each section. Our deep neural network architecture learns a latent topic embedding over the course of a document. This can be leveraged to classify local topics from plain text and segment a document at topic shifts. In addition, we contribute WikiSection, a publicly available dataset with 242k labeled sections in English and German from two distinct domains: diseases and cities. From our extensive evaluation of 20 architectures, we report a highest score of 71.6% F1 for the segmentation and classification of 30 topics from the English city domain, scored by our SECTOR LSTM model with bloom filter embeddings and bidirectional segmentation. This is a significant improvement of 29.5 points F1 compared to state-of-the-art CNN classifiers with baseline segmentation.
Crowd-Labeling Fashion Reviews with Quality Control
Apr 05, 2018


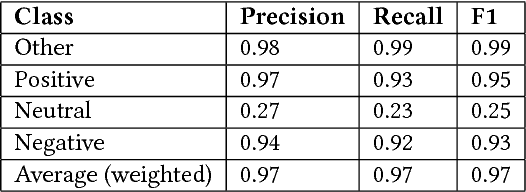
We present a new methodology for high-quality labeling in the fashion domain with crowd workers instead of experts. We focus on the Aspect-Based Sentiment Analysis task. Our methods filter out inaccurate input from crowd workers but we preserve different worker labeling to capture the inherent high variability of the opinions. We demonstrate the quality of labeled data based on Facebook's FastText framework as a baseline.
IDEL: In-Database Entity Linking with Neural Embeddings
Mar 13, 2018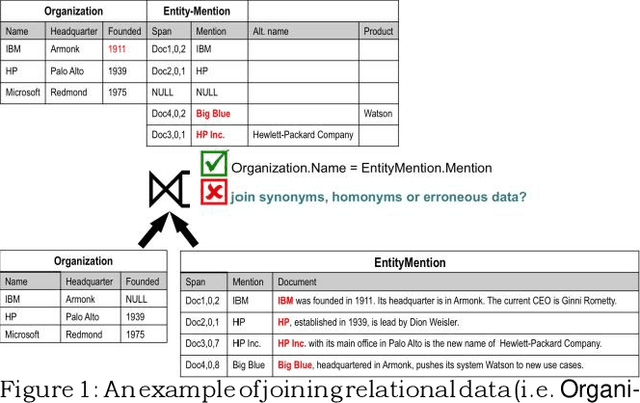
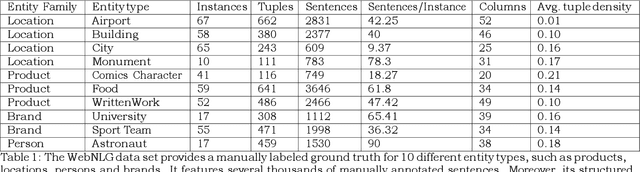
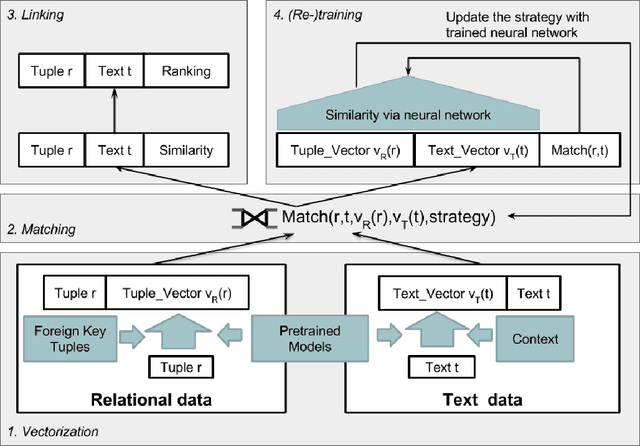

We present a novel architecture, In-Database Entity Linking (IDEL), in which we integrate the analytics-optimized RDBMS MonetDB with neural text mining abilities. Our system design abstracts core tasks of most neural entity linking systems for MonetDB. To the best of our knowledge, this is the first defacto implemented system integrating entity-linking in a database. We leverage the ability of MonetDB to support in-database-analytics with user defined functions (UDFs) implemented in Python. These functions call machine learning libraries for neural text mining, such as TensorFlow. The system achieves zero cost for data shipping and transformation by utilizing MonetDB's ability to embed Python processes in the database kernel and exchange data in NumPy arrays. IDEL represents text and relational data in a joint vector space with neural embeddings and can compensate errors with ambiguous entity representations. For detecting matching entities, we propose a novel similarity function based on joint neural embeddings which are learned via minimizing pairwise contrastive ranking loss. This function utilizes a high dimensional index structures for fast retrieval of matching entities. Our first implementation and experiments using the WebNLG corpus show the effectiveness and the potentials of IDEL.
Analysing Errors of Open Information Extraction Systems
Jul 24, 2017
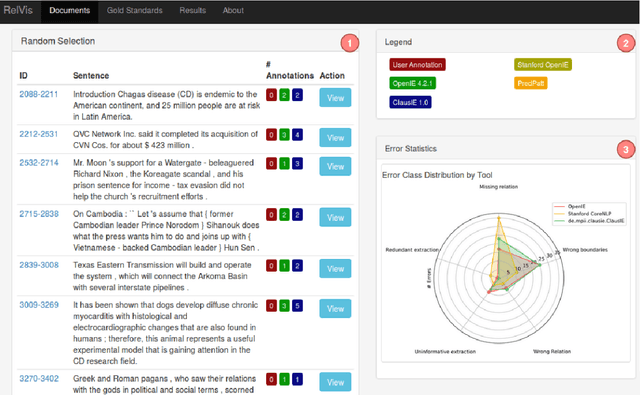
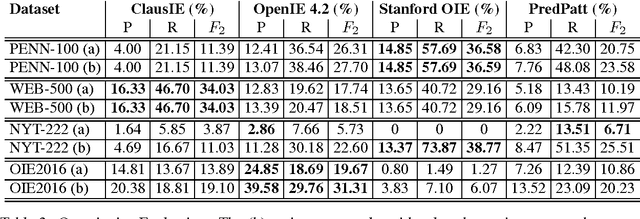
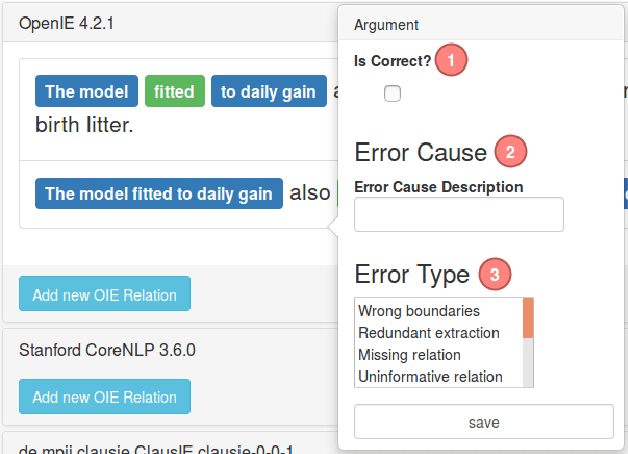
We report results on benchmarking Open Information Extraction (OIE) systems using RelVis, a toolkit for benchmarking Open Information Extraction systems. Our comprehensive benchmark contains three data sets from the news domain and one data set from Wikipedia with overall 4522 labeled sentences and 11243 binary or n-ary OIE relations. In our analysis on these data sets we compared the performance of four popular OIE systems, ClausIE, OpenIE 4.2, Stanford OpenIE and PredPatt. In addition, we evaluated the impact of five common error classes on a subset of 749 n-ary tuples. From our deep analysis we unreveal important research directions for a next generation of OIE systems.