 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM Probe: Evaluating LLMs for Low-Resource Languages
Mar 31, 2026Despite rapid advances in large language models (LLMs), their linguistic abilities in low-resource and morphologically rich languages are still not well understood due to limited annotated resources and the absence of standardized evaluation frameworks. This paper presents LLM Probe, a lexicon-based assessment framework designed to systematically evaluate the linguistic skills of LLMs in low-resource language environments. The framework analyzes models across four areas of language understanding: lexical alignment, part-of-speech recognition, morphosyntactic probing, and translation accuracy. To illustrate the framework, we create a manually annotated benchmark dataset using a low-resource Semitic language as a case study. The dataset comprises bilingual lexicons with linguistic annotations, including part-of-speech tags, grammatical gender, and morphosyntactic features, which demonstrate high inter-annotator agreement to ensure reliable annotations. We test a variety of models, including causal language models and sequence-to-sequence architectures. The results reveal notable differences in performance across various linguistic tasks: sequence-to-sequence models generally excel in morphosyntactic analysis and translation quality, whereas causal models demonstrate strong performance in lexical alignment but exhibit weaker translation accuracy. Our results emphasize the need for linguistically grounded evaluation to better understand LLM limitations in low-resource settings. We release LLM Probe and the accompanying benchmark dataset as open-source tools to promote reproducible benchmarking and to support the development of more inclusive multilingual language technologies.
LGSE: Lexically Grounded Subword Embedding Initialization for Low-Resource Language Adaptation
Mar 23, 2026Adapting pretrained language models to low-resource, morphologically rich languages remains a significant challenge. Existing vocabulary expansion methods typically rely on arbitrarily segmented subword units, resulting in fragmented lexical representations and loss of critical morphological information. To address this limitation, we propose the Lexically Grounded Subword Embedding Initialization (LGSE) framework, which introduces morphologically informed segmentation for initializing embeddings of novel tokens. Instead of using random vectors or arbitrary subwords, LGSE decomposes words into their constituent morphemes and constructs semantically coherent embeddings by averaging pretrained subword or FastText-based morpheme representations. When a token cannot be segmented into meaningful morphemes, its embedding is constructed using character n-gram representations to capture structural information. During Language-Adaptive Pretraining, we apply a regularization term that penalizes large deviations of newly introduced embeddings from their initialized values, preserving alignment with the original pretrained embedding space while enabling adaptation to the target language. To isolate the effect of initialization, we retain the original pre-trained model vocabulary and tokenizer and update only the new embeddings during adaptation. We evaluate LGSE on three NLP tasks: Question Answering, Named Entity Recognition, and Text Classification, in two morphologically rich, low-resource languages: Amharic and Tigrinya, where morphological segmentation resources are available. Experimental results show that LGSE consistently outperforms baseline methods across all tasks, demonstrating the effectiveness of morphologically grounded embedding initialization for improving representation quality in underrepresented languages. Project resources are available in the GitHub link.
Cross-Modal Rationale Transfer for Explainable Humanitarian Classification on Social Media
Mar 19, 2026Advances in social media data dissemination enable the provision of real-time information during a crisis. The information comes from different classes, such as infrastructure damages, persons missing or stranded in the affected zone, etc. Existing methods attempted to classify text and images into various humanitarian categories, but their decision-making process remains largely opaque, which affects their deployment in real-life applications. Recent work has sought to improve transparency by extracting textual rationales from tweets to explain predicted classes. However, such explainable classification methods have mostly focused on text, rather than crisis-related images. In this paper, we propose an interpretable-by-design multimodal classification framework. Our method first learns the joint representation of text and image using a visual language transformer model and extracts text rationales. Next, it extracts the image rationales via the mapping with text rationales. Our approach demonstrates how to learn rationales in one modality from another through cross-modal rationale transfer, which saves annotation effort. Finally, tweets are classified based on extracted rationales. Experiments are conducted over CrisisMMD benchmark dataset, and results show that our proposed method boosts the classification Macro-F1 by 2-35% while extracting accurate text tokens and image patches as rationales. Human evaluation also supports the claim that our proposed method is able to retrieve better image rationale patches (12%) that help to identify humanitarian classes. Our method adapts well to new, unseen datasets in zero-shot mode, achieving an accuracy of 80%.
Training-Induced Bias Toward LLM-Generated Content in Dense Retrieval
Feb 11, 2026Dense retrieval is a promising approach for acquiring relevant context or world knowledge in open-domain natural language processing tasks and is now widely used in information retrieval applications. However, recent reports claim a broad preference for text generated by large language models (LLMs). This bias is called "source bias", and it has been hypothesized that lower perplexity contributes to this effect. In this study, we revisit this claim by conducting a controlled evaluation to trace the emergence of such preferences across training stages and data sources. Using parallel human- and LLM-generated counterparts of the SciFact and Natural Questions (NQ320K) datasets, we compare unsupervised checkpoints with models fine-tuned using in-domain human text, in-domain LLM-generated text, and MS MARCO. Our results show the following: 1) Unsupervised retrievers do not exhibit a uniform pro-LLM preference. The direction and magnitude depend on the dataset. 2) Across the settings tested, supervised fine-tuning on MS MARCO consistently shifts the rankings toward LLM-generated text. 3) In-domain fine-tuning produces dataset-specific and inconsistent shifts in preference. 4) Fine-tuning on LLM-generated corpora induces a pronounced pro-LLM bias. Finally, a retriever-centric perplexity probe involving the reattachment of a language modeling head to the fine-tuned dense retriever encoder indicates agreement with relevance near chance, thereby weakening the explanatory power of perplexity. Our study demonstrates that source bias is a training-induced phenomenon rather than an inherent property of dense retrievers.
Investigating the Impact of Histopathological Foundation Models on Regressive Prediction of Homologous Recombination Deficiency
Jan 29, 2026Foundation models pretrained on large-scale histopathology data have found great success in various fields of computational pathology, but their impact on regressive biomarker prediction remains underexplored. In this work, we systematically evaluate histopathological foundation models for regression-based tasks, demonstrated through the prediction of homologous recombination deficiency (HRD) score - a critical biomarker for personalized cancer treatment. Within multiple instance learning frameworks, we extract patch-level features from whole slide images (WSI) using five state-of-the-art foundation models, and evaluate their impact compared to contrastive learning-based features. Models are trained to predict continuous HRD scores based on these extracted features across breast, endometrial, and lung cancer cohorts from two public medical data collections. Extensive experiments demonstrate that models trained on foundation model features consistently outperform the baseline in terms of predictive accuracy and generalization capabilities while exhibiting systematic differences among the foundation models. Additionally, we propose a distribution-based upsampling strategy to mitigate target imbalance in these datasets, significantly improving the recall and balanced accuracy for underrepresented but clinically important patient populations. Furthermore, we investigate the impact of different sampling strategies and instance bagsizes by ablation studies. Our results highlight the benefits of large-scale histopathological pretraining for more precise and transferable regressive biomarker prediction, showcasing its potential to advance AI-driven precision oncology.
MedAI: Evaluating TxAgent's Therapeutic Agentic Reasoning in the NeurIPS CURE-Bench Competition
Dec 12, 2025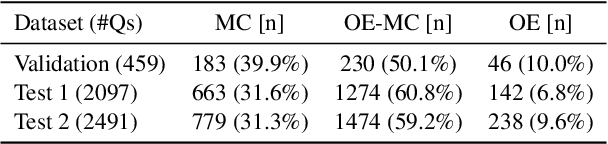
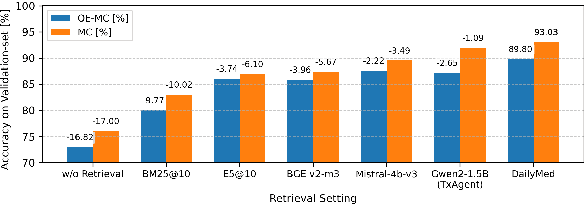
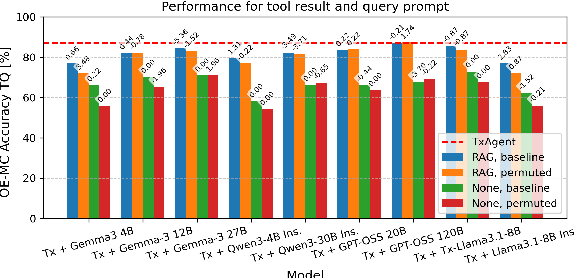
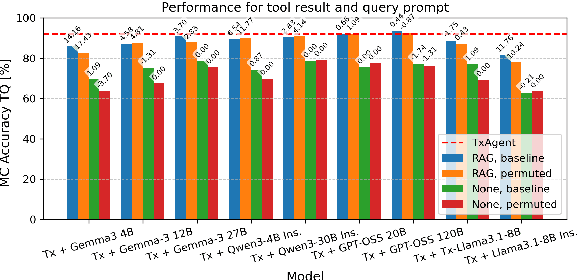
Therapeutic decision-making in clinical medicine constitutes a high-stakes domain in which AI guidance interacts with complex interactions among patient characteristics, disease processes, and pharmacological agents. Tasks such as drug recommendation, treatment planning, and adverse-effect prediction demand robust, multi-step reasoning grounded in reliable biomedical knowledge. Agentic AI methods, exemplified by TxAgent, address these challenges through iterative retrieval-augmented generation (RAG). TxAgent employs a fine-tuned Llama-3.1-8B model that dynamically generates and executes function calls to a unified biomedical tool suite (ToolUniverse), integrating FDA Drug API, OpenTargets, and Monarch resources to ensure access to current therapeutic information. In contrast to general-purpose RAG systems, medical applications impose stringent safety constraints, rendering the accuracy of both the reasoning trace and the sequence of tool invocations critical. These considerations motivate evaluation protocols treating token-level reasoning and tool-usage behaviors as explicit supervision signals. This work presents insights derived from our participation in the CURE-Bench NeurIPS 2025 Challenge, which benchmarks therapeutic-reasoning systems using metrics that assess correctness, tool utilization, and reasoning quality. We analyze how retrieval quality for function (tool) calls influences overall model performance and demonstrate performance gains achieved through improved tool-retrieval strategies. Our work was awarded the Excellence Award in Open Science. Complete information can be found at https://curebench.ai/.
Towards Transparent Stance Detection: A Zero-Shot Approach Using Implicit and Explicit Interpretability
Nov 05, 2025Zero-Shot Stance Detection (ZSSD) identifies the attitude of the post toward unseen targets. Existing research using contrastive, meta-learning, or data augmentation suffers from generalizability issues or lack of coherence between text and target. Recent works leveraging large language models (LLMs) for ZSSD focus either on improving unseen target-specific knowledge or generating explanations for stance analysis. However, most of these works are limited by their over-reliance on explicit reasoning, provide coarse explanations that lack nuance, and do not explicitly model the reasoning process, making it difficult to interpret the model's predictions. To address these issues, in our study, we develop a novel interpretable ZSSD framework, IRIS. We provide an interpretable understanding of the attitude of the input towards the target implicitly based on sequences within the text (implicit rationales) and explicitly based on linguistic measures (explicit rationales). IRIS considers stance detection as an information retrieval ranking task, understanding the relevance of implicit rationales for different stances to guide the model towards correct predictions without requiring the ground-truth of rationales, thus providing inherent interpretability. In addition, explicit rationales based on communicative features help decode the emotional and cognitive dimensions of stance, offering an interpretable understanding of the author's attitude towards the given target. Extensive experiments on the benchmark datasets of VAST, EZ-STANCE, P-Stance, and RFD using 50%, 30%, and even 10% training data prove the generalizability of our model, benefiting from the proposed architecture and interpretable design.
Tokenization Disparities as Infrastructure Bias: How Subword Systems Create Inequities in LLM Access and Efficiency
Oct 14, 2025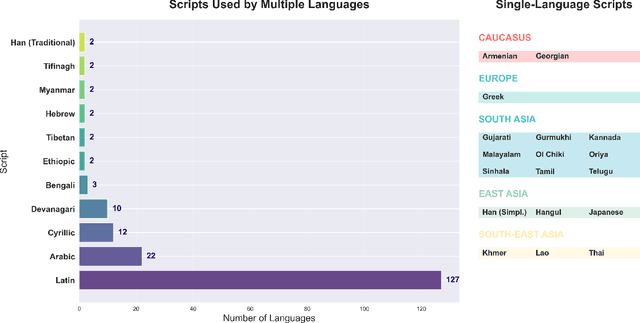
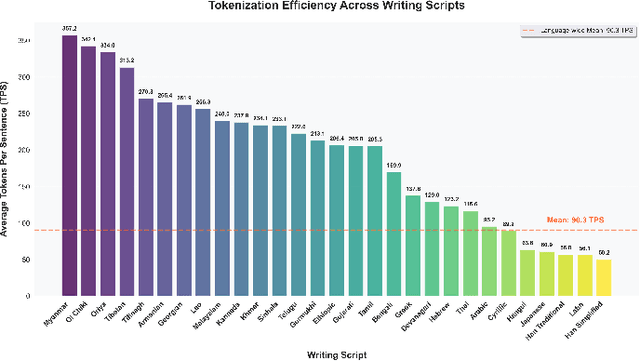
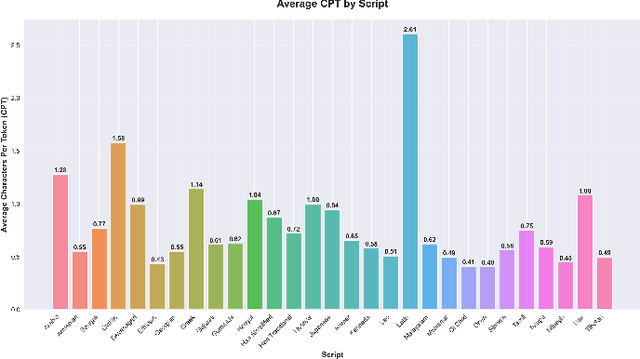
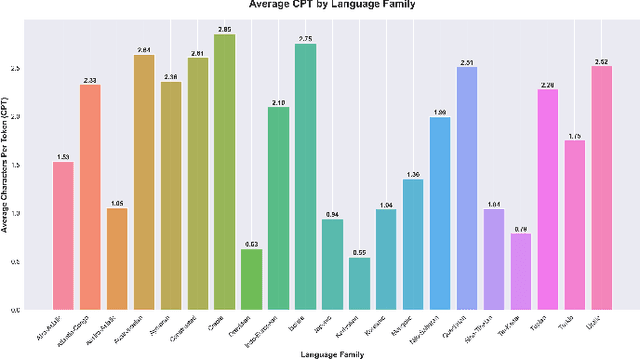
Tokenization disparities pose a significant barrier to achieving equitable access to artificial intelligence across linguistically diverse populations. This study conducts a large-scale cross-linguistic evaluation of tokenization efficiency in over 200 languages to systematically quantify computational inequities in large language models (LLMs). Using a standardized experimental framework, we applied consistent preprocessing and normalization protocols, followed by uniform tokenization through the tiktoken library across all language samples. Comprehensive tokenization statistics were collected using established evaluation metrics, including Tokens Per Sentence (TPS) and Relative Tokenization Cost (RTC), benchmarked against English baselines. Our cross-linguistic analysis reveals substantial and systematic disparities: Latin-script languages consistently exhibit higher tokenization efficiency, while non-Latin and morphologically complex languages incur significantly greater token inflation, often 3-5 times higher RTC ratios. These inefficiencies translate into increased computational costs and reduced effective context utilization for underrepresented languages. Overall, the findings highlight structural inequities in current AI systems, where speakers of low-resource and non-Latin languages face disproportionate computational disadvantages. Future research should prioritize the development of linguistically informed tokenization strategies and adaptive vocabulary construction methods that incorporate typological diversity, ensuring more inclusive and computationally equitable multilingual AI systems.
MoVoC: Morphology-Aware Subword Construction for Geez Script Languages
Sep 10, 2025



Subword-based tokenization methods often fail to preserve morphological boundaries, a limitation especially pronounced in low-resource, morphologically complex languages such as those written in the Geez script. To address this, we present MoVoC (Morpheme-aware Subword Vocabulary Construction) and train MoVoC-Tok, a tokenizer that integrates supervised morphological analysis into the subword vocabulary. This hybrid segmentation approach combines morpheme-based and Byte Pair Encoding (BPE) tokens to preserve morphological integrity while maintaining lexical meaning. To tackle resource scarcity, we curate and release manually annotated morpheme data for four Geez script languages and a morpheme-aware vocabulary for two of them. While the proposed tokenization method does not lead to significant gains in automatic translation quality, we observe consistent improvements in intrinsic metrics, MorphoScore, and Boundary Precision, highlighting the value of morphology-aware segmentation in enhancing linguistic fidelity and token efficiency. Our morpheme-annotated datasets and tokenizer will be publicly available to support further research in low-resource, morphologically rich languages. Our code and data are available on GitHub: https://github.com/hailaykidu/MoVoC
"Where does it hurt?" -- Dataset and Study on Physician Intent Trajectories in Doctor Patient Dialogues
Aug 26, 2025



In a doctor-patient dialogue, the primary objective of physicians is to diagnose patients and propose a treatment plan. Medical doctors guide these conversations through targeted questioning to efficiently gather the information required to provide the best possible outcomes for patients. To the best of our knowledge, this is the first work that studies physician intent trajectories in doctor-patient dialogues. We use the `Ambient Clinical Intelligence Benchmark' (Aci-bench) dataset for our study. We collaborate with medical professionals to develop a fine-grained taxonomy of physician intents based on the SOAP framework (Subjective, Objective, Assessment, and Plan). We then conduct a large-scale annotation effort to label over 5000 doctor-patient turns with the help of a large number of medical experts recruited using Prolific, a popular crowd-sourcing platform. This large labeled dataset is an important resource contribution that we use for benchmarking the state-of-the-art generative and encoder models for medical intent classification tasks. Our findings show that our models understand the general structure of medical dialogues with high accuracy, but often fail to identify transitions between SOAP categories. We also report for the first time common trajectories in medical dialogue structures that provide valuable insights for designing `differential diagnosis' systems. Finally, we extensively study the impact of intent filtering for medical dialogue summarization and observe a significant boost in performance. We make the codes and data, including annotation guidelines, publicly available at https://github.com/DATEXIS/medical-intent-classification.