 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoVoC: Morphology-Aware Subword Construction for Geez Script Languages
Sep 10, 2025



Subword-based tokenization methods often fail to preserve morphological boundaries, a limitation especially pronounced in low-resource, morphologically complex languages such as those written in the Geez script. To address this, we present MoVoC (Morpheme-aware Subword Vocabulary Construction) and train MoVoC-Tok, a tokenizer that integrates supervised morphological analysis into the subword vocabulary. This hybrid segmentation approach combines morpheme-based and Byte Pair Encoding (BPE) tokens to preserve morphological integrity while maintaining lexical meaning. To tackle resource scarcity, we curate and release manually annotated morpheme data for four Geez script languages and a morpheme-aware vocabulary for two of them. While the proposed tokenization method does not lead to significant gains in automatic translation quality, we observe consistent improvements in intrinsic metrics, MorphoScore, and Boundary Precision, highlighting the value of morphology-aware segmentation in enhancing linguistic fidelity and token efficiency. Our morpheme-annotated datasets and tokenizer will be publicly available to support further research in low-resource, morphologically rich languages. Our code and data are available on GitHub: https://github.com/hailaykidu/MoVoC
SCOOTER: A Human Evaluation Framework for Unrestricted Adversarial Examples
Jul 10, 2025Unrestricted adversarial attacks aim to fool computer vision models without being constrained by $\ell_p$-norm bounds to remain imperceptible to humans, for example, by changing an object's color. This allows attackers to circumvent traditional, norm-bounded defense strategies such as adversarial training or certified defense strategies. However, due to their unrestricted nature, there are also no guarantees of norm-based imperceptibility, necessitating human evaluations to verify just how authentic these adversarial examples look. While some related work assesses this vital quality of adversarial attacks, none provide statistically significant insights. This issue necessitates a unified framework that supports and streamlines such an assessment for evaluating and comparing unrestricted attacks. To close this gap, we introduce SCOOTER - an open-source, statistically powered framework for evaluating unrestricted adversarial examples. Our contributions are: $(i)$ best-practice guidelines for crowd-study power, compensation, and Likert equivalence bounds to measure imperceptibility; $(ii)$ the first large-scale human vs. model comparison across 346 human participants showing that three color-space attacks and three diffusion-based attacks fail to produce imperceptible images. Furthermore, we found that GPT-4o can serve as a preliminary test for imperceptibility, but it only consistently detects adversarial examples for four out of six tested attacks; $(iii)$ open-source software tools, including a browser-based task template to collect annotations and analysis scripts in Python and R; $(iv)$ an ImageNet-derived benchmark dataset containing 3K real images, 7K adversarial examples, and over 34K human ratings. Our findings demonstrate that automated vision systems do not align with human perception, reinforcing the need for a ground-truth SCOOTER benchmark.
TIGQA:An Expert Annotated Question Answering Dataset in Tigrinya
Apr 26, 2024The absence of explicitly tailored, accessible annotated datasets for educational purposes presents a notable obstacle for NLP tasks in languages with limited resources.This study initially explores the feasibility of using machine translation (MT) to convert an existing dataset into a Tigrinya dataset in SQuAD format. As a result, we present TIGQA, an expert annotated educational dataset consisting of 2.68K question-answer pairs covering 122 diverse topics such as climate, water, and traffic. These pairs are from 537 context paragraphs in publicly accessible Tigrinya and Biology books. Through comprehensive analyses, we demonstrate that the TIGQA dataset requires skills beyond simple word matching, requiring both single-sentence and multiple-sentence inference abilities. We conduct experiments using state-of-the art MRC methods, marking the first exploration of such models on TIGQA. Additionally, we estimate human performance on the dataset and juxtapose it with the results obtained from pretrained models.The notable disparities between human performance and best model performance underscore the potential for further enhancements to TIGQA through continued research. Our dataset is freely accessible via the provided link to encourage the research community to address the challenges in the Tigrinya MRC.
* 9 pages,3 figures, 7 tables,2 listings
How Real Is Real? A Human Evaluation Framework for Unrestricted Adversarial Examples
Apr 19, 2024


With an ever-increasing reliance on machine learning (ML) models in the real world, adversarial examples threaten the safety of AI-based systems such as autonomous vehicles. In the image domain, they represent maliciously perturbed data points that look benign to humans (i.e., the image modification is not noticeable) but greatly mislead state-of-the-art ML models. Previously, researchers ensured the imperceptibility of their altered data points by restricting perturbations via $\ell_p$ norms. However, recent publications claim that creating natural-looking adversarial examples without such restrictions is also possible. With much more freedom to instill malicious information into data, these unrestricted adversarial examples can potentially overcome traditional defense strategies as they are not constrained by the limitations or patterns these defenses typically recognize and mitigate. This allows attackers to operate outside of expected threat models. However, surveying existing image-based methods, we noticed a need for more human evaluations of the proposed image modifications. Based on existing human-assessment frameworks for image generation quality, we propose SCOOTER - an evaluation framework for unrestricted image-based attacks. It provides researchers with guidelines for conducting statistically significant human experiments, standardized questions, and a ready-to-use implementation. We propose a framework that allows researchers to analyze how imperceptible their unrestricted attacks truly are.
A Review of the Role of Causality in Developing Trustworthy AI Systems
Feb 14, 2023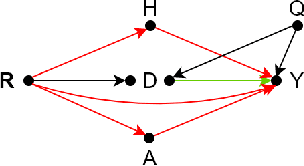
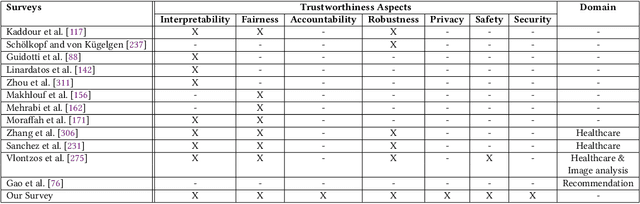
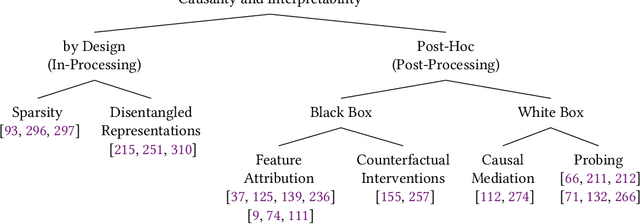
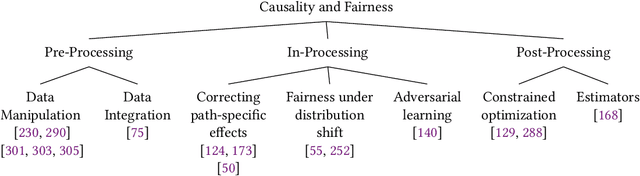
State-of-the-art AI models largely lack an understanding of the cause-effect relationship that governs human understanding of the real world. Consequently, these models do not generalize to unseen data, often produce unfair results, and are difficult to interpret. This has led to efforts to improve the trustworthiness aspects of AI models. Recently, causal modeling and inference methods have emerged as powerful tools. This review aims to provide the reader with an overview of causal methods that have been developed to improve the trustworthiness of AI models. We hope that our contribution will motivate future research on causality-based solutions for trustworthy AI.