 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSCOOTER: A Human Evaluation Framework for Unrestricted Adversarial Examples
Jul 10, 2025Unrestricted adversarial attacks aim to fool computer vision models without being constrained by $\ell_p$-norm bounds to remain imperceptible to humans, for example, by changing an object's color. This allows attackers to circumvent traditional, norm-bounded defense strategies such as adversarial training or certified defense strategies. However, due to their unrestricted nature, there are also no guarantees of norm-based imperceptibility, necessitating human evaluations to verify just how authentic these adversarial examples look. While some related work assesses this vital quality of adversarial attacks, none provide statistically significant insights. This issue necessitates a unified framework that supports and streamlines such an assessment for evaluating and comparing unrestricted attacks. To close this gap, we introduce SCOOTER - an open-source, statistically powered framework for evaluating unrestricted adversarial examples. Our contributions are: $(i)$ best-practice guidelines for crowd-study power, compensation, and Likert equivalence bounds to measure imperceptibility; $(ii)$ the first large-scale human vs. model comparison across 346 human participants showing that three color-space attacks and three diffusion-based attacks fail to produce imperceptible images. Furthermore, we found that GPT-4o can serve as a preliminary test for imperceptibility, but it only consistently detects adversarial examples for four out of six tested attacks; $(iii)$ open-source software tools, including a browser-based task template to collect annotations and analysis scripts in Python and R; $(iv)$ an ImageNet-derived benchmark dataset containing 3K real images, 7K adversarial examples, and over 34K human ratings. Our findings demonstrate that automated vision systems do not align with human perception, reinforcing the need for a ground-truth SCOOTER benchmark.
Improving the Effectiveness of Potential-Based Reward Shaping in Reinforcement Learning
Feb 03, 2025



Potential-based reward shaping is commonly used to incorporate prior knowledge of how to solve the task into reinforcement learning because it can formally guarantee policy invariance. As such, the optimal policy and the ordering of policies by their returns are not altered by potential-based reward shaping. In this work, we highlight the dependence of effective potential-based reward shaping on the initial Q-values and external rewards, which determine the agent's ability to exploit the shaping rewards to guide its exploration and achieve increased sample efficiency. We formally derive how a simple linear shift of the potential function can be used to improve the effectiveness of reward shaping without changing the encoded preferences in the potential function, and without having to adjust the initial Q-values, which can be challenging and undesirable in deep reinforcement learning. We show the theoretical limitations of continuous potential functions for correctly assigning positive and negative reward shaping values. We verify our theoretical findings empirically on Gridworld domains with sparse and uninformative reward functions, as well as on the Cart Pole and Mountain Car environments, where we demonstrate the application of our results in deep reinforcement learning.
Sustainable broadcasting in Blockchain Network with Reinforcement Learning
Jul 22, 2024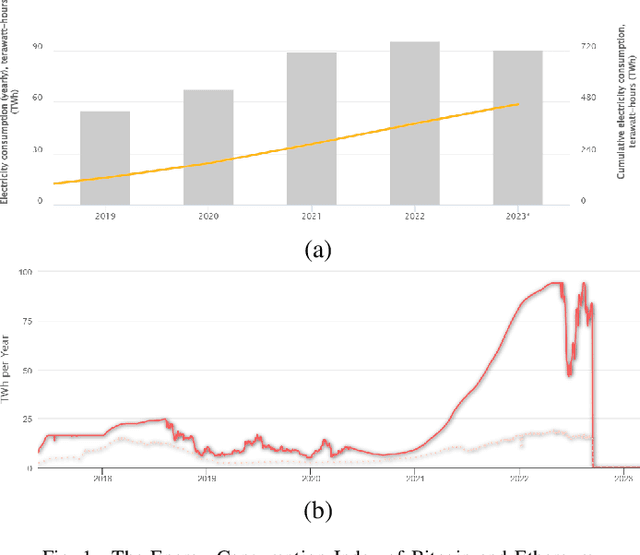
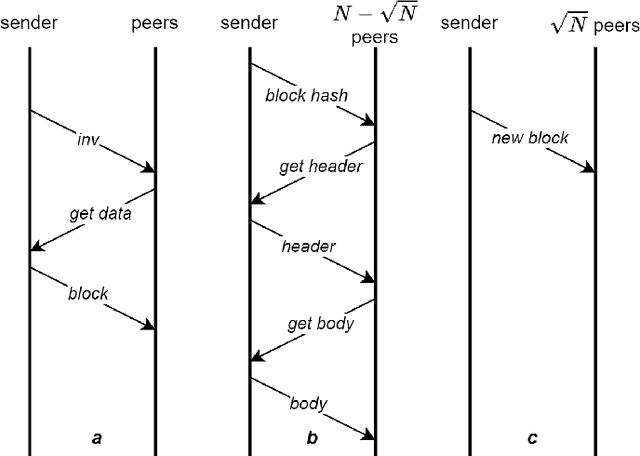
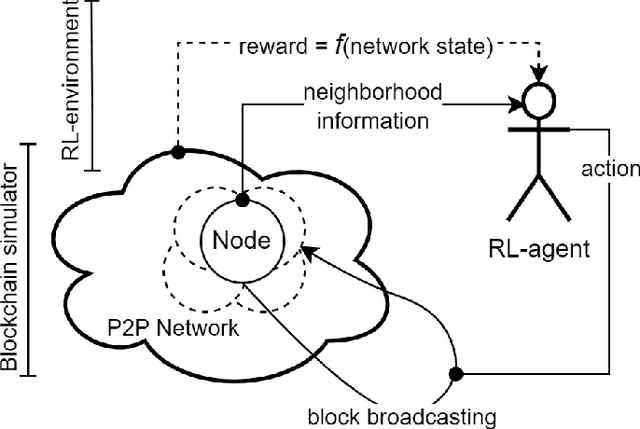
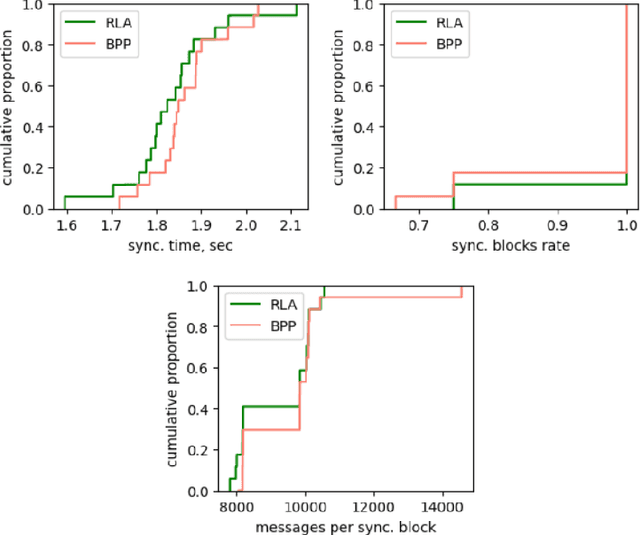
Recent estimates put the carbon footprint of Bitcoin and Ethereum at an average of 64 and 26 million tonnes of CO2 per year, respectively. To address this growing problem, several possible approaches have been proposed in the literature: creating alternative blockchain consensus mechanisms, applying redundancy reduction techniques, utilizing renewable energy sources, and employing energy-efficient devices, etc. In this paper, we follow the second avenue and propose an efficient approach based on reinforcement learning that improves the block broadcasting scheme in blockchain networks. The analysis and experimental results confirmed that the proposed improvement of the block propagation scheme could cleverly handle network dynamics and achieve better results than the default approach. Additionally, our technical integration of the simulator and developed RL environment can be used as a complete solution for further study of new schemes and protocols that use RL or other ML techniques.
How Real Is Real? A Human Evaluation Framework for Unrestricted Adversarial Examples
Apr 19, 2024


With an ever-increasing reliance on machine learning (ML) models in the real world, adversarial examples threaten the safety of AI-based systems such as autonomous vehicles. In the image domain, they represent maliciously perturbed data points that look benign to humans (i.e., the image modification is not noticeable) but greatly mislead state-of-the-art ML models. Previously, researchers ensured the imperceptibility of their altered data points by restricting perturbations via $\ell_p$ norms. However, recent publications claim that creating natural-looking adversarial examples without such restrictions is also possible. With much more freedom to instill malicious information into data, these unrestricted adversarial examples can potentially overcome traditional defense strategies as they are not constrained by the limitations or patterns these defenses typically recognize and mitigate. This allows attackers to operate outside of expected threat models. However, surveying existing image-based methods, we noticed a need for more human evaluations of the proposed image modifications. Based on existing human-assessment frameworks for image generation quality, we propose SCOOTER - an evaluation framework for unrestricted image-based attacks. It provides researchers with guidelines for conducting statistically significant human experiments, standardized questions, and a ready-to-use implementation. We propose a framework that allows researchers to analyze how imperceptible their unrestricted attacks truly are.
Data Valuation for Offline Reinforcement Learning
May 19, 2022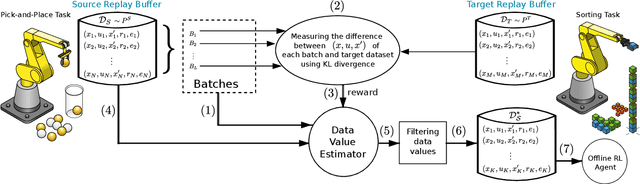
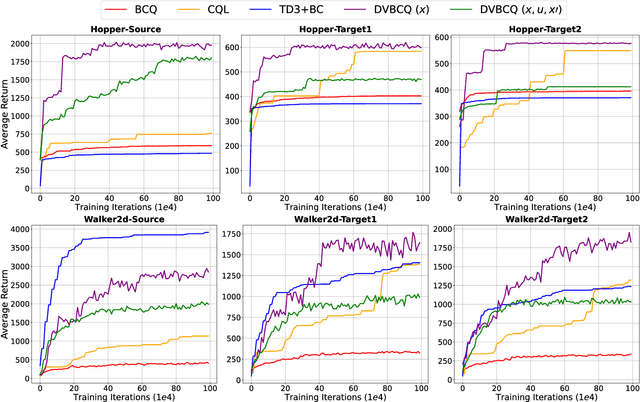
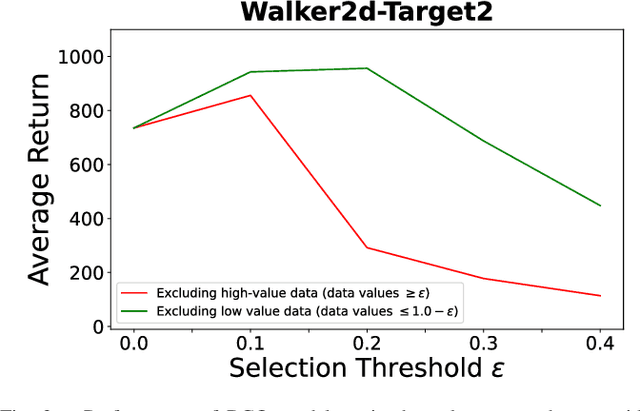
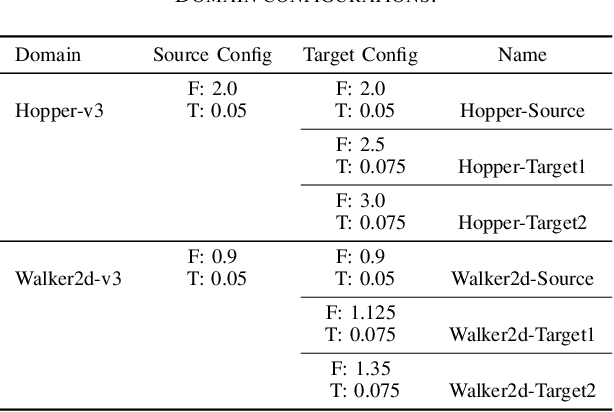
The success of deep reinforcement learning (DRL) hinges on the availability of training data, which is typically obtained via a large number of environment interactions. In many real-world scenarios, costs and risks are associated with gathering these data. The field of offline reinforcement learning addresses these issues through outsourcing the collection of data to a domain expert or a carefully monitored program and subsequently searching for a batch-constrained optimal policy. With the emergence of data markets, an alternative to constructing a dataset in-house is to purchase external data. However, while state-of-the-art offline reinforcement learning approaches have shown a lot of promise, they currently rely on carefully constructed datasets that are well aligned with the intended target domains. This raises questions regarding the transferability and robustness of an offline reinforcement learning agent trained on externally acquired data. In this paper, we empirically evaluate the ability of the current state-of-the-art offline reinforcement learning approaches to coping with the source-target domain mismatch within two MuJoCo environments, finding that current state-of-the-art offline reinforcement learning algorithms underperform in the target domain. To address this, we propose data valuation for offline reinforcement learning (DVORL), which allows us to identify relevant and high-quality transitions, improving the performance and transferability of policies learned by offline reinforcement learning algorithms. The results show that our method outperforms offline reinforcement learning baselines on two MuJoCo environments.
MAGNet: Multi-agent Graph Network for Deep Multi-agent Reinforcement Learning
Dec 17, 2020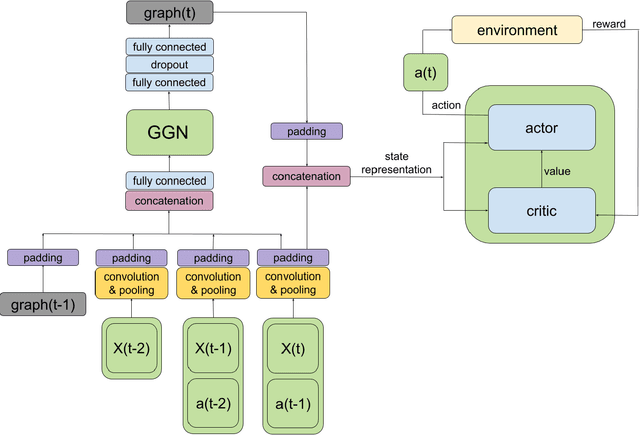
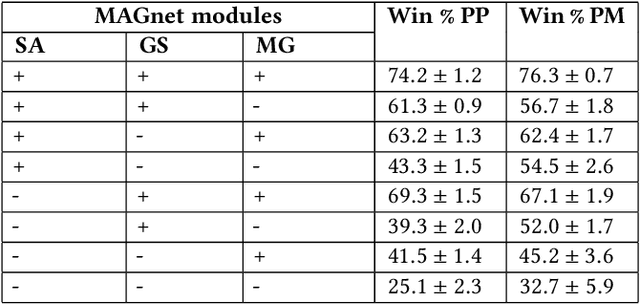

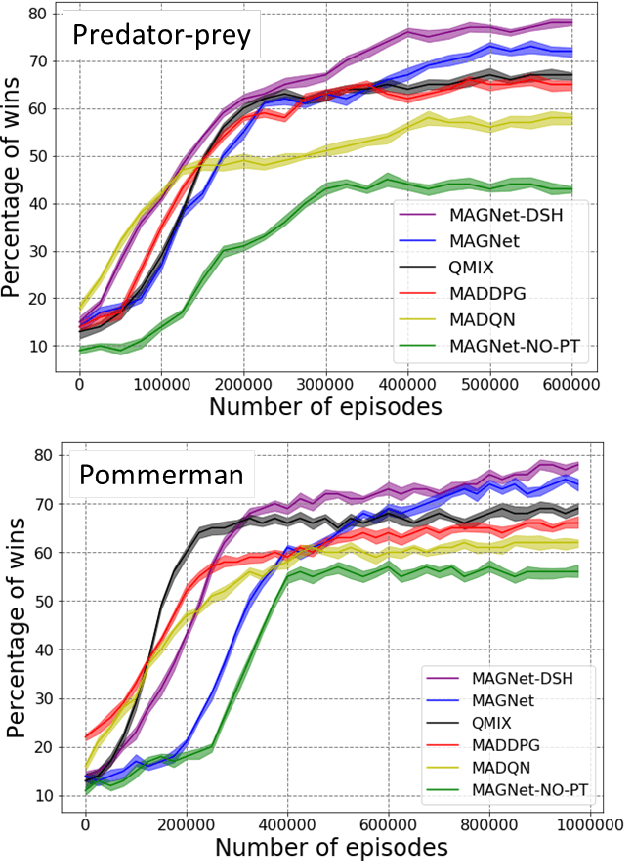
Over recent years, deep reinforcement learning has shown strong successes in complex single-agent tasks, and more recently this approach has also been applied to multi-agent domains. In this paper, we propose a novel approach, called MAGNet, to multi-agent reinforcement learning that utilizes a relevance graph representation of the environment obtained by a self-attention mechanism, and a message-generation technique. We applied our MAGnet approach to the synthetic predator-prey multi-agent environment and the Pommerman game and the results show that it significantly outperforms state-of-the-art MARL solutions, including Multi-agent Deep Q-Networks (MADQN), Multi-agent Deep Deterministic Policy Gradient (MADDPG), and QMIX
Learning to Run with Potential-Based Reward Shaping and Demonstrations from Video Data
Dec 16, 2020

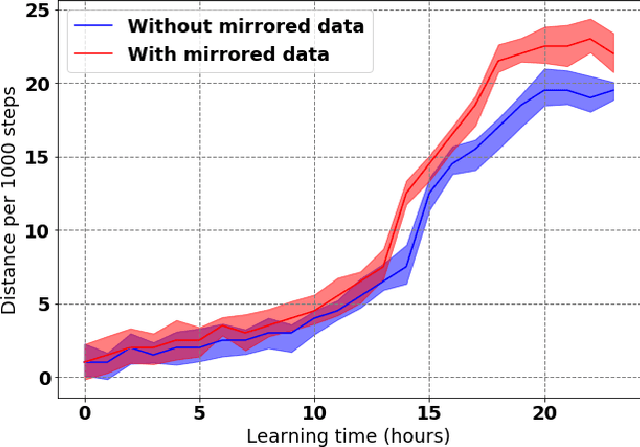
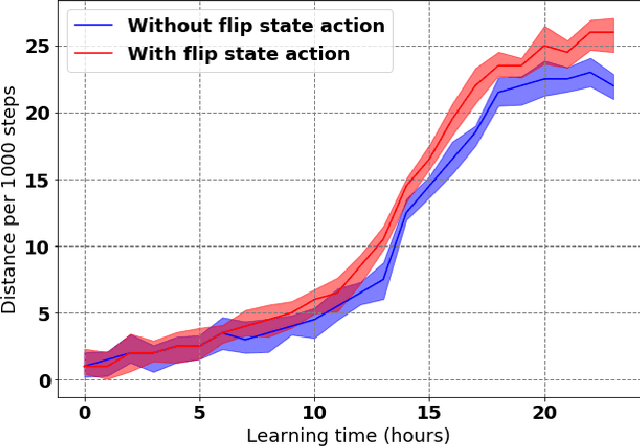
Learning to produce efficient movement behaviour for humanoid robots from scratch is a hard problem, as has been illustrated by the "Learning to run" competition at NIPS 2017. The goal of this competition was to train a two-legged model of a humanoid body to run in a simulated race course with maximum speed. All submissions took a tabula rasa approach to reinforcement learning (RL) and were able to produce relatively fast, but not optimal running behaviour. In this paper, we demonstrate how data from videos of human running (e.g. taken from YouTube) can be used to shape the reward of the humanoid learning agent to speed up the learning and produce a better result. Specifically, we are using the positions of key body parts at regular time intervals to define a potential function for potential-based reward shaping (PBRS). Since PBRS does not change the optimal policy, this approach allows the RL agent to overcome sub-optimalities in the human movements that are shown in the videos. We present experiments in which we combine selected techniques from the top ten approaches from the NIPS competition with further optimizations to create an high-performing agent as a baseline. We then demonstrate how video-based reward shaping improves the performance further, resulting in an RL agent that runs twice as fast as the baseline in 12 hours of training. We furthermore show that our approach can overcome sub-optimal running behaviour in videos, with the learned policy significantly outperforming that of the running agent from the video.
A comparative evaluation of machine learning methods for robot navigation through human crowds
Dec 16, 2020

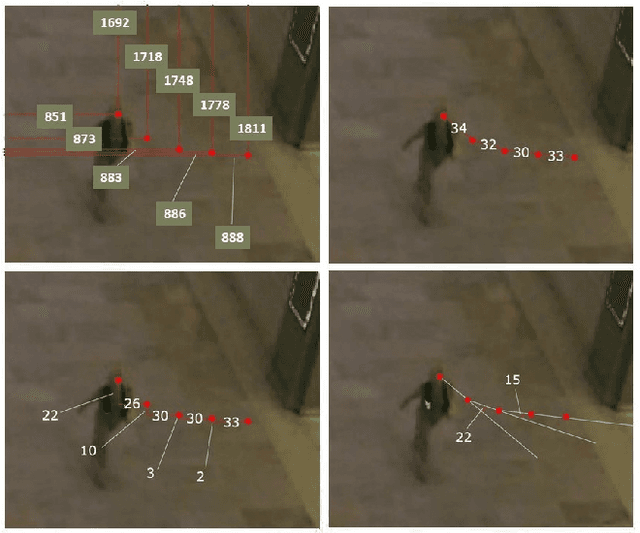
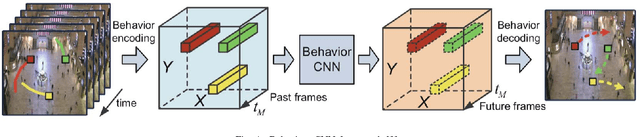
Robot navigation through crowds poses a difficult challenge to AI systems, since the methods should result in fast and efficient movement but at the same time are not allowed to compromise safety. Most approaches to date were focused on the combination of pathfinding algorithms with machine learning for pedestrian walking prediction. More recently, reinforcement learning techniques have been proposed in the research literature. In this paper, we perform a comparative evaluation of pathfinding/prediction and reinforcement learning approaches on a crowd movement dataset collected from surveillance videos taken at Grand Central Station in New York. The results demonstrate the strong superiority of state-of-the-art reinforcement learning approaches over pathfinding with state-of-the-art behaviour prediction techniques.
Deep Learning of Cell Classification using Microscope Images of Intracellular Microtubule Networks
Dec 16, 2020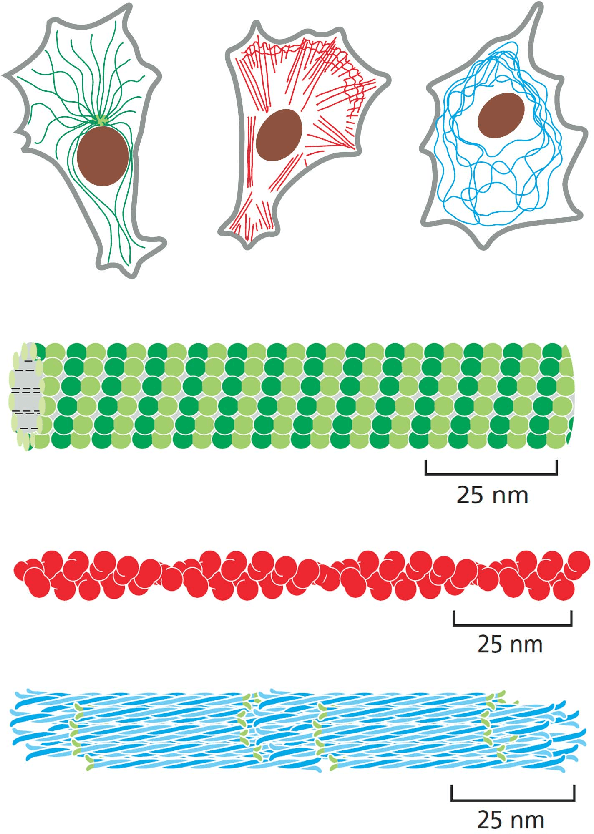
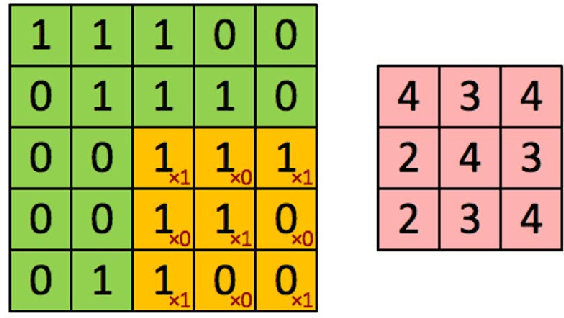
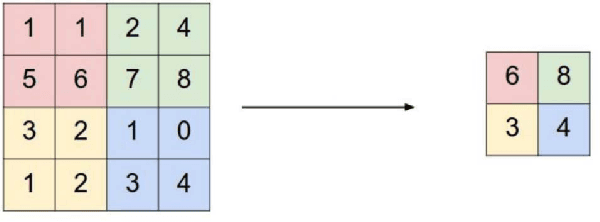
Microtubule networks (MTs) are a component of a cell that may indicate the presence of various chemical compounds and can be used to recognize properties such as treatment resistance. Therefore, the classification of MT images is of great relevance for cell diagnostics. Human experts find it particularly difficult to recognize the levels of chemical compound exposure of a cell. Improving the accuracy with automated techniques would have a significant impact on cell therapy. In this paper we present the application of Deep Learning to MT image classification and evaluate it on a large MT image dataset of animal cells with three degrees of exposure to a chemical agent. The results demonstrate that the learned deep network performs on par or better at the corresponding cell classification task than human experts. Specifically, we show that the task of recognizing different levels of chemical agent exposure can be handled significantly better by the neural network than by human experts.
Continuous Gesture Recognition from sEMG Sensor Data with Recurrent Neural Networks and Adversarial Domain Adaptation
Dec 16, 2020
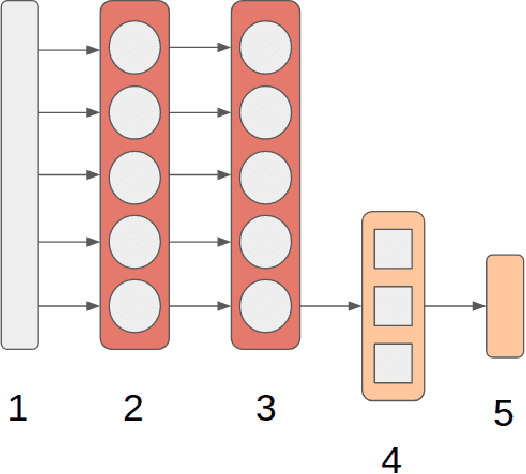
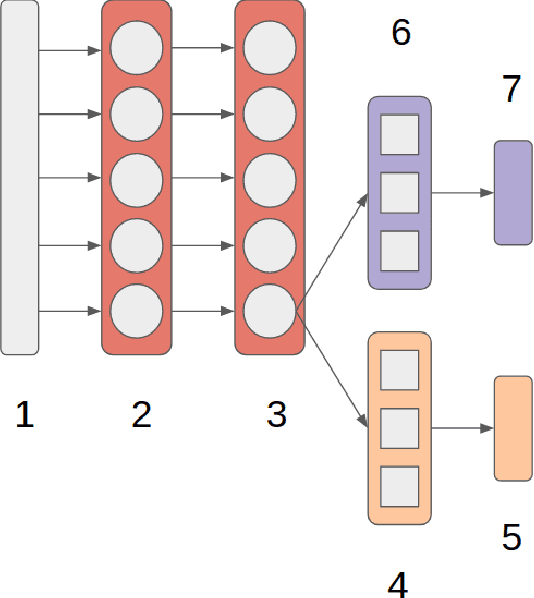
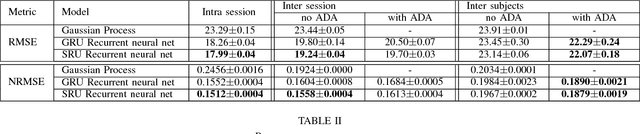
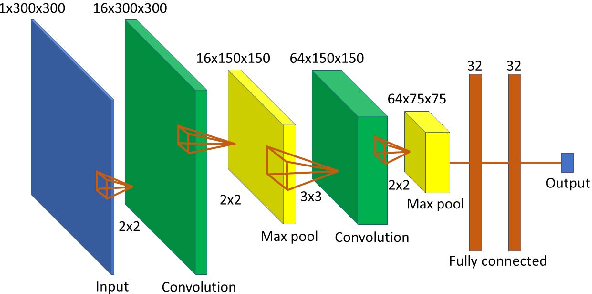
Movement control of artificial limbs has made big advances in recent years. New sensor and control technology enhanced the functionality and usefulness of artificial limbs to the point that complex movements, such as grasping, can be performed to a limited extent. To date, the most successful results were achieved by applying recurrent neural networks (RNNs). However, in the domain of artificial hands, experiments so far were limited to non-mobile wrists, which significantly reduces the functionality of such prostheses. In this paper, for the first time, we present empirical results on gesture recognition with both mobile and non-mobile wrists. Furthermore, we demonstrate that recurrent neural networks with simple recurrent units (SRU) outperform regular RNNs in both cases in terms of gesture recognition accuracy, on data acquired by an arm band sensing electromagnetic signals from arm muscles (via surface electromyography or sEMG). Finally, we show that adding domain adaptation techniques to continuous gesture recognition with RNN improves the transfer ability between subjects, where a limb controller trained on data from one person is used for another person.