 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuidelines for Applying RL and MARL in Cybersecurity Applications
Mar 06, 2025Reinforcement Learning (RL) and Multi-Agent Reinforcement Learning (MARL) have emerged as promising methodologies for addressing challenges in automated cyber defence (ACD). These techniques offer adaptive decision-making capabilities in high-dimensional, adversarial environments. This report provides a structured set of guidelines for cybersecurity professionals and researchers to assess the suitability of RL and MARL for specific use cases, considering factors such as explainability, exploration needs, and the complexity of multi-agent coordination. It also discusses key algorithmic approaches, implementation challenges, and real-world constraints, such as data scarcity and adversarial interference. The report further outlines open research questions, including policy optimality, agent cooperation levels, and the integration of MARL systems into operational cybersecurity frameworks. By bridging theoretical advancements and practical deployment, these guidelines aim to enhance the effectiveness of AI-driven cyber defence strategies.
An Empirical Game-Theoretic Analysis of Autonomous Cyber-Defence Agents
Jan 31, 2025The recent rise in increasingly sophisticated cyber-attacks raises the need for robust and resilient autonomous cyber-defence (ACD) agents. Given the variety of cyber-attack tactics, techniques and procedures (TTPs) employed, learning approaches that can return generalisable policies are desirable. Meanwhile, the assurance of ACD agents remains an open challenge. We address both challenges via an empirical game-theoretic analysis of deep reinforcement learning (DRL) approaches for ACD using the principled double oracle (DO) algorithm. This algorithm relies on adversaries iteratively learning (approximate) best responses against each others' policies; a computationally expensive endeavour for autonomous cyber operations agents. In this work we introduce and evaluate a theoretically-sound, potential-based reward shaping approach to expedite this process. In addition, given the increasing number of open-source ACD-DRL approaches, we extend the DO formulation to allow for multiple response oracles (MRO), providing a framework for a holistic evaluation of ACD approaches.
Machine Theory of Mind for Autonomous Cyber-Defence
Dec 05, 2024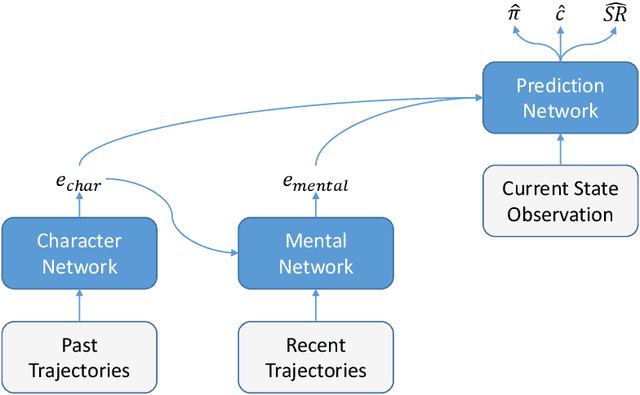
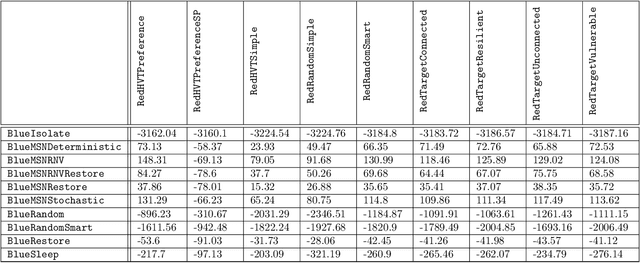
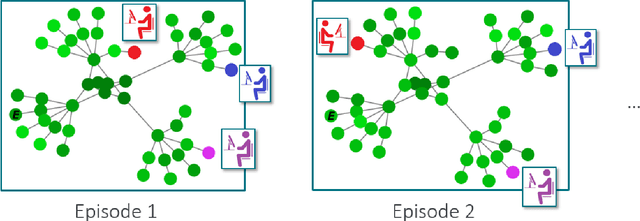
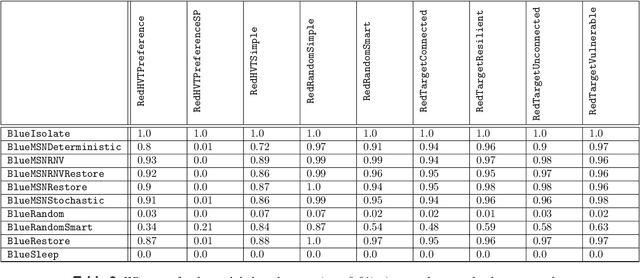
Intelligent autonomous agents hold much potential for the domain of cyber-security. However, due to many state-of-the-art approaches relying on uninterpretable black-box models, there is growing demand for methods that offer stakeholders clear and actionable insights into their latent beliefs and motivations. To address this, we evaluate Theory of Mind (ToM) approaches for Autonomous Cyber Operations. Upon learning a robust prior, ToM models can predict an agent's goals, behaviours, and contextual beliefs given only a handful of past behaviour observations. In this paper, we introduce a novel Graph Neural Network (GNN)-based ToM architecture tailored for cyber-defence, Graph-In, Graph-Out (GIGO)-ToM, which can accurately predict both the targets and attack trajectories of adversarial cyber agents over arbitrary computer network topologies. To evaluate the latter, we propose a novel extension of the Wasserstein distance for measuring the similarity of graph-based probability distributions. Whereas the standard Wasserstein distance lacks a fixed reference scale, we introduce a graph-theoretic normalization factor that enables a standardized comparison between networks of different sizes. We furnish this metric, which we term the Network Transport Distance (NTD), with a weighting function that emphasizes predictions according to custom node features, allowing network operators to explore arbitrary strategic considerations. Benchmarked against a Graph-In, Dense-Out (GIDO)-ToM architecture in an abstract cyber-defence environment, our empirical evaluations show that GIGO-ToM can accurately predict the goals and behaviours of various unseen cyber-attacking agents across a range of network topologies, as well as learn embeddings that can effectively characterize their policies.
Enhanced Federated Anomaly Detection Through Autoencoders Using Summary Statistics-Based Thresholding
Oct 11, 2024In Federated Learning (FL), anomaly detection (AD) is a challenging task due to the decentralized nature of data and the presence of non-IID data distributions. This study introduces a novel federated threshold calculation method that leverages summary statistics from both normal and anomalous data to improve the accuracy and robustness of anomaly detection using autoencoders (AE) in a federated setting. Our approach aggregates local summary statistics across clients to compute a global threshold that optimally separates anomalies from normal data while ensuring privacy preservation. We conducted extensive experiments using publicly available datasets, including Credit Card Fraud Detection, Shuttle, and Covertype, under various data distribution scenarios. The results demonstrate that our method consistently outperforms existing federated and local threshold calculation techniques, particularly in handling non-IID data distributions. This study also explores the impact of different data distribution scenarios and the number of clients on the performance of federated anomaly detection. Our findings highlight the potential of using summary statistics for threshold calculation in improving the scalability and accuracy of federated anomaly detection systems.
Deep Reinforcement Learning for Autonomous Cyber Operations: A Survey
Oct 11, 2023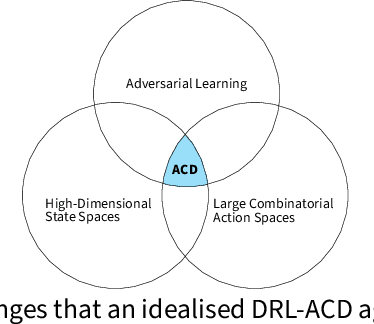
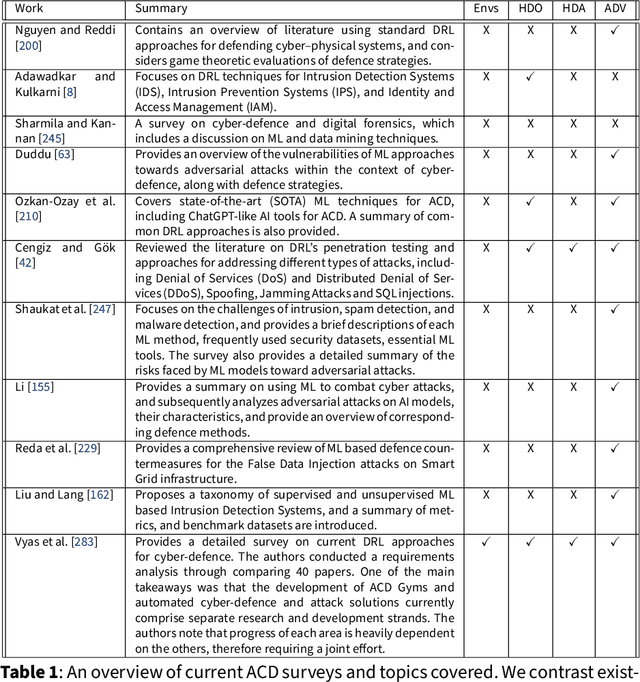
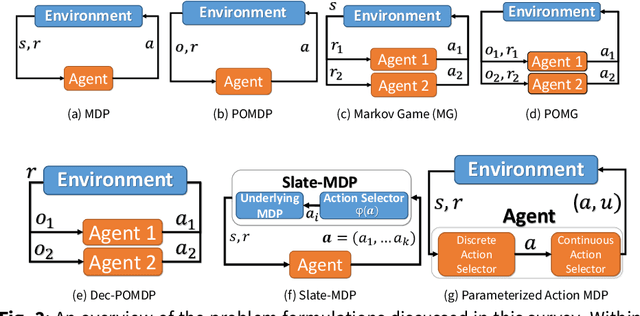
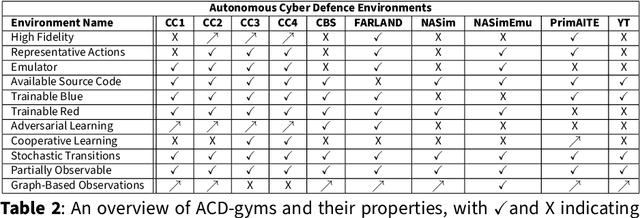
The rapid increase in the number of cyber-attacks in recent years raises the need for principled methods for defending networks against malicious actors. Deep reinforcement learning (DRL) has emerged as a promising approach for mitigating these attacks. However, while DRL has shown much potential for cyber-defence, numerous challenges must be overcome before DRL can be applied to autonomous cyber-operations (ACO) at scale. Principled methods are required for environments that confront learners with very high-dimensional state spaces, large multi-discrete action spaces, and adversarial learning. Recent works have reported success in solving these problems individually. There have also been impressive engineering efforts towards solving all three for real-time strategy games. However, applying DRL to the full ACO problem remains an open challenge. Here, we survey the relevant DRL literature and conceptualize an idealised ACO-DRL agent. We provide: i.) A summary of the domain properties that define the ACO problem; ii.) A comprehensive evaluation of the extent to which domains used for benchmarking DRL approaches are comparable to ACO; iii.) An overview of state-of-the-art approaches for scaling DRL to domains that confront learners with the curse of dimensionality, and; iv.) A survey and critique of current methods for limiting the exploitability of agents within adversarial settings from the perspective of ACO. We conclude with open research questions that we hope will motivate future directions for researchers and practitioners working on ACO.
Cutting Through the Noise: An Empirical Comparison of Psychoacoustic and Envelope-based Features for Machinery Fault Detection
Nov 03, 2022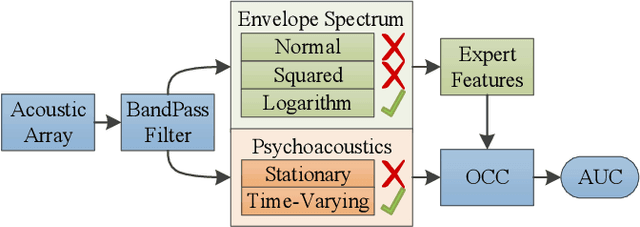

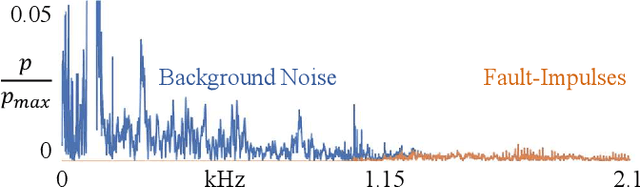
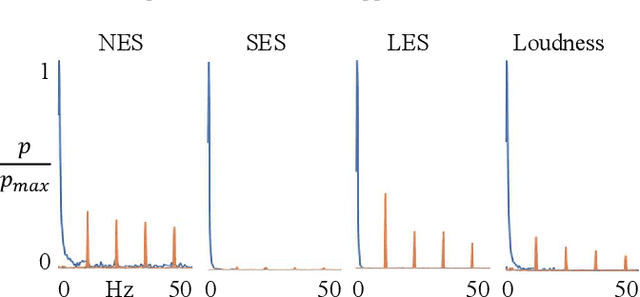
Acoustic-based fault detection has a high potential to monitor the health condition of mechanical parts. However, the background noise of an industrial environment may negatively influence the performance of fault detection. Limited attention has been paid to improving the robustness of fault detection against industrial environmental noise. Therefore, we present the Lenze production background-noise (LPBN) real-world dataset and an automated and noise-robust auditory inspection (ARAI) system for the end-of-line inspection of geared motors. An acoustic array is used to acquire data from motors with a minor fault, major fault, or which are healthy. A benchmark is provided to compare the psychoacoustic features with different types of envelope features based on expert knowledge of the gearbox. To the best of our knowledge, we are the first to apply time-varying psychoacoustic features for fault detection. We train a state-of-the-art one-class-classifier, on samples from healthy motors and separate the faulty ones for fault detection using a threshold. The best-performing approaches achieve an area under curve of 0.87 (logarithm envelope), 0.86 (time-varying psychoacoustics), and 0.91 (combination of both).
Developing an AI-enabled IIoT platform -- Lessons learned from early use case validation
Jul 10, 2022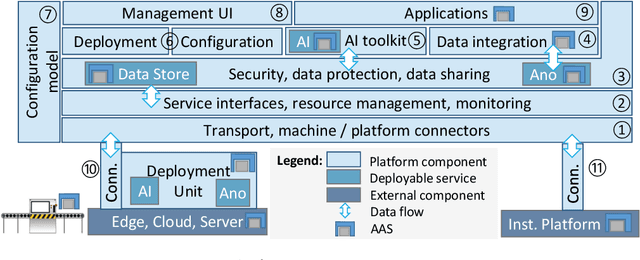
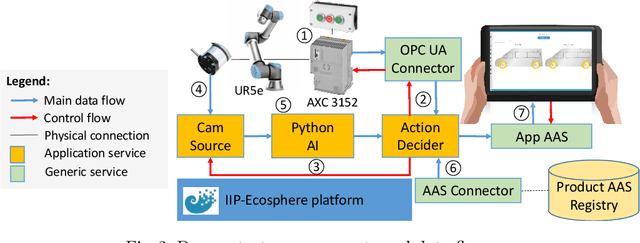


For a broader adoption of AI in industrial production, adequate infrastructure capabilities are crucial. This includes easing the integration of AI with industrial devices, support for distributed deployment, monitoring, and consistent system configuration. Existing IIoT platforms still lack required capabilities to flexibly integrate reusable AI services and relevant standards such as Asset Administration Shells or OPC UA in an open, ecosystem-based manner. This is exactly what our next level Intelligent Industrial Production Ecosphere (IIP-Ecosphere) platform addresses, employing a highly configurable low-code based approach. In this paper, we introduce the design of this platform and discuss an early evaluation in terms of a demonstrator for AI-enabled visual quality inspection. This is complemented by insights and lessons learned during this early evaluation activity.
Market Making with Scaled Beta Policies
Jul 09, 2022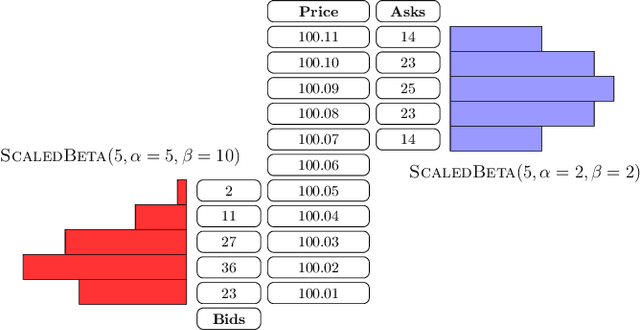
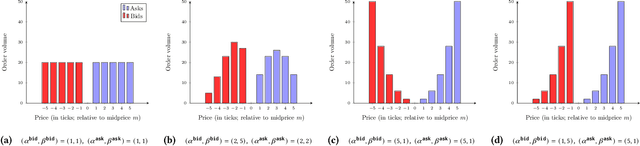
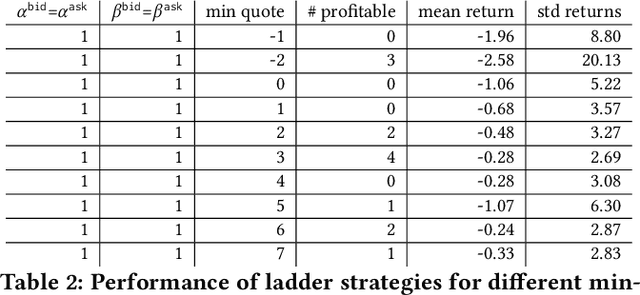
This paper introduces a new representation for the actions of a market maker in an order-driven market. This representation uses scaled beta distributions, and generalises three approaches taken in the artificial intelligence for market making literature: single price-level selection, ladder strategies and "market making at the touch". Ladder strategies place uniform volume across an interval of contiguous prices. Scaled beta distribution based policies generalise these, allowing volume to be skewed across the price interval. We demonstrate that this flexibility is useful for inventory management, one of the key challenges faced by a market maker. In this paper, we conduct three main experiments: first, we compare our more flexible beta-based actions with the special case of ladder strategies; then, we investigate the performance of simple fixed distributions; and finally, we devise and evaluate a simple and intuitive dynamic control policy that adjusts actions in a continuous manner depending on the signed inventory that the market maker has acquired. All empirical evaluations use a high-fidelity limit order book simulator based on historical data with 50 levels on each side.
Data Valuation for Offline Reinforcement Learning
May 19, 2022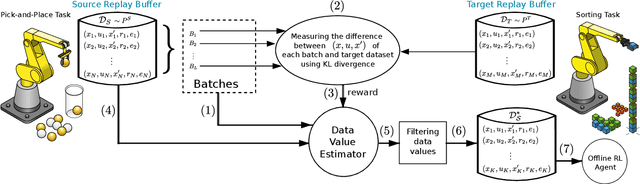
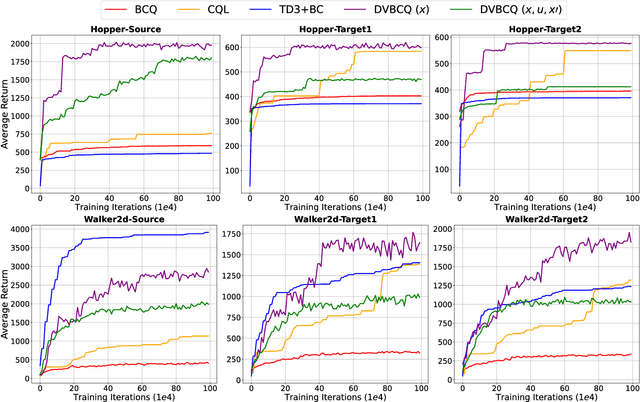
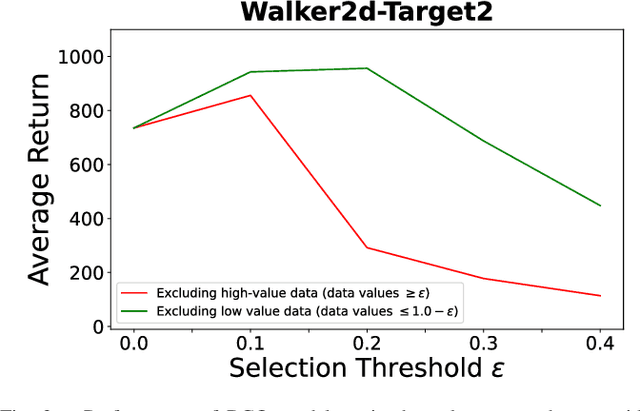
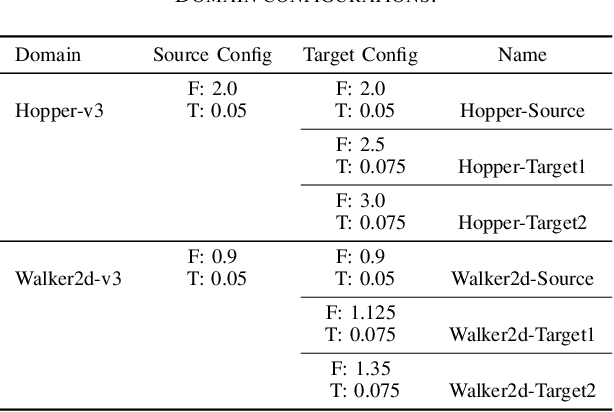
The success of deep reinforcement learning (DRL) hinges on the availability of training data, which is typically obtained via a large number of environment interactions. In many real-world scenarios, costs and risks are associated with gathering these data. The field of offline reinforcement learning addresses these issues through outsourcing the collection of data to a domain expert or a carefully monitored program and subsequently searching for a batch-constrained optimal policy. With the emergence of data markets, an alternative to constructing a dataset in-house is to purchase external data. However, while state-of-the-art offline reinforcement learning approaches have shown a lot of promise, they currently rely on carefully constructed datasets that are well aligned with the intended target domains. This raises questions regarding the transferability and robustness of an offline reinforcement learning agent trained on externally acquired data. In this paper, we empirically evaluate the ability of the current state-of-the-art offline reinforcement learning approaches to coping with the source-target domain mismatch within two MuJoCo environments, finding that current state-of-the-art offline reinforcement learning algorithms underperform in the target domain. To address this, we propose data valuation for offline reinforcement learning (DVORL), which allows us to identify relevant and high-quality transitions, improving the performance and transferability of policies learned by offline reinforcement learning algorithms. The results show that our method outperforms offline reinforcement learning baselines on two MuJoCo environments.
Identifying Cause-and-Effect Relationships of Manufacturing Errors using Sequence-to-Sequence Learning
May 05, 2022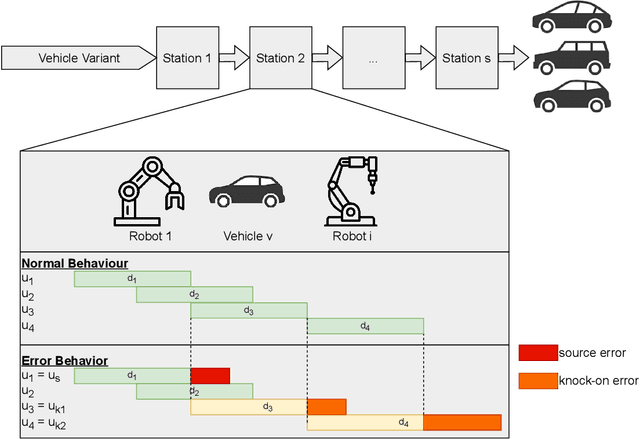
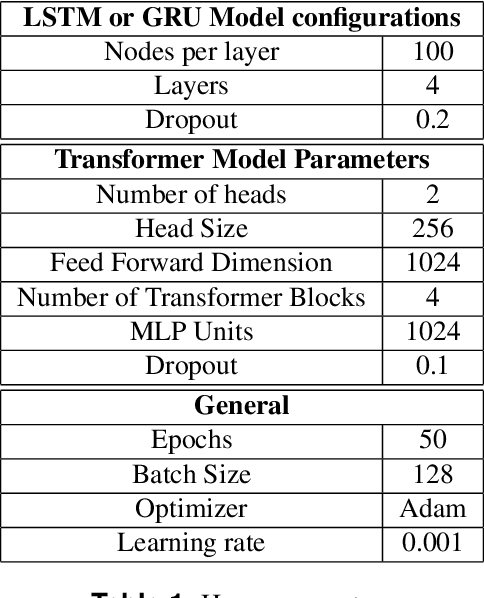
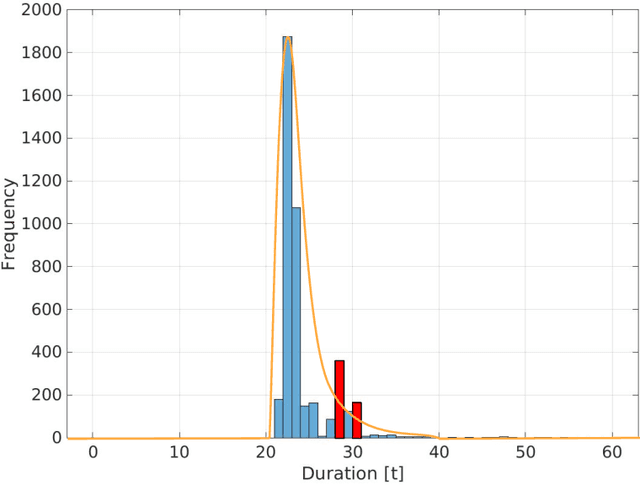
In car-body production the pre-formed sheet metal parts of the body are assembled on fully-automated production lines. The body passes through multiple stations in succession, and is processed according to the order requirements. The timely completion of orders depends on the individual station-based operations concluding within their scheduled cycle times. If an error occurs in one station, it can have a knock-on effect, resulting in delays on the downstream stations. To the best of our knowledge, there exist no methods for automatically distinguishing between source and knock-on errors in this setting, as well as establishing a causal relation between them. Utilizing real-time information about conditions collected by a production data acquisition system, we propose a novel vehicle manufacturing analysis system, which uses deep learning to establish a link between source and knock-on errors. We benchmark three sequence-to-sequence models, and introduce a novel composite time-weighted action metric for evaluating models in this context. We evaluate our framework on a real-world car production dataset recorded by Volkswagen Commercial Vehicles. Surprisingly we find that 71.68% of sequences contain either a source or knock-on error. With respect to seq2seq model training, we find that the Transformer demonstrates a better performance compared to LSTM and GRU in this domain, in particular when the prediction range with respect to the durations of future actions is increased.