 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn Efficient Bayesian Exploration in Model-Based Reinforcement Learning
Jul 03, 2025In this work, we address the challenge of data-efficient exploration in reinforcement learning by examining existing principled, information-theoretic approaches to intrinsic motivation. Specifically, we focus on a class of exploration bonuses that targets epistemic uncertainty rather than the aleatoric noise inherent in the environment. We prove that these bonuses naturally signal epistemic information gains and converge to zero once the agent becomes sufficiently certain about the environment's dynamics and rewards, thereby aligning exploration with genuine knowledge gaps. Our analysis provides formal guarantees for IG-based approaches, which previously lacked theoretical grounding. To enable practical use, we also discuss tractable approximations via sparse variational Gaussian Processes, Deep Kernels and Deep Ensemble models. We then outline a general framework - Predictive Trajectory Sampling with Bayesian Exploration (PTS-BE) - which integrates model-based planning with information-theoretic bonuses to achieve sample-efficient deep exploration. We empirically demonstrate that PTS-BE substantially outperforms other baselines across a variety of environments characterized by sparse rewards and/or purely exploratory tasks.
Towards Causal Model-Based Policy Optimization
Mar 12, 2025Real-world decision-making problems are often marked by complex, uncertain dynamics that can shift or break under changing conditions. Traditional Model-Based Reinforcement Learning (MBRL) approaches learn predictive models of environment dynamics from queried trajectories and then use these models to simulate rollouts for policy optimization. However, such methods do not account for the underlying causal mechanisms that govern the environment, and thus inadvertently capture spurious correlations, making them sensitive to distributional shifts and limiting their ability to generalize. The same naturally holds for model-free approaches. In this work, we introduce Causal Model-Based Policy Optimization (C-MBPO), a novel framework that integrates causal learning into the MBRL pipeline to achieve more robust, explainable, and generalizable policy learning algorithms. Our approach centers on first inferring a Causal Markov Decision Process (C-MDP) by learning a local Structural Causal Model (SCM) of both the state and reward transition dynamics from trajectories gathered online. C-MDPs differ from classic MDPs in that we can decompose causal dependencies in the environment dynamics via specifying an associated Causal Bayesian Network. C-MDPs allow for targeted interventions and counterfactual reasoning, enabling the agent to distinguish between mere statistical correlations and causal relationships. The learned SCM is then used to simulate counterfactual on-policy transitions and rewards under hypothetical actions (or ``interventions"), thereby guiding policy optimization more effectively. The resulting policy learned by C-MBPO can be shown to be robust to a class of distributional shifts that affect spurious, non-causal relationships in the dynamics. We demonstrate this through some simple experiments involving near and far OOD dynamics drifts.
Guidelines for Applying RL and MARL in Cybersecurity Applications
Mar 06, 2025Reinforcement Learning (RL) and Multi-Agent Reinforcement Learning (MARL) have emerged as promising methodologies for addressing challenges in automated cyber defence (ACD). These techniques offer adaptive decision-making capabilities in high-dimensional, adversarial environments. This report provides a structured set of guidelines for cybersecurity professionals and researchers to assess the suitability of RL and MARL for specific use cases, considering factors such as explainability, exploration needs, and the complexity of multi-agent coordination. It also discusses key algorithmic approaches, implementation challenges, and real-world constraints, such as data scarcity and adversarial interference. The report further outlines open research questions, including policy optimality, agent cooperation levels, and the integration of MARL systems into operational cybersecurity frameworks. By bridging theoretical advancements and practical deployment, these guidelines aim to enhance the effectiveness of AI-driven cyber defence strategies.
Inherently Interpretable and Uncertainty-Aware Models for Online Learning in Cyber-Security Problems
Nov 14, 2024



In this paper, we address the critical need for interpretable and uncertainty-aware machine learning models in the context of online learning for high-risk industries, particularly cyber-security. While deep learning and other complex models have demonstrated impressive predictive capabilities, their opacity and lack of uncertainty quantification present significant questions about their trustworthiness. We propose a novel pipeline for online supervised learning problems in cyber-security, that harnesses the inherent interpretability and uncertainty awareness of Additive Gaussian Processes (AGPs) models. Our approach aims to balance predictive performance with transparency while improving the scalability of AGPs, which represents their main drawback, potentially enabling security analysts to better validate threat detection, troubleshoot and reduce false positives, and generally make trustworthy, informed decisions. This work contributes to the growing field of interpretable AI by proposing a class of models that can be significantly beneficial for high-stake decision problems such as the ones typical of the cyber-security domain. The source code is available.
Entity-based Reinforcement Learning for Autonomous Cyber Defence
Oct 23, 2024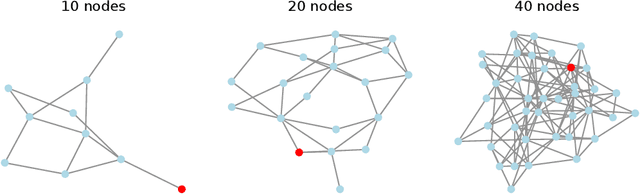
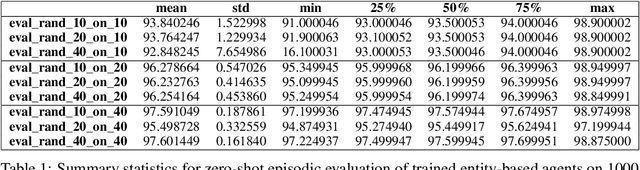
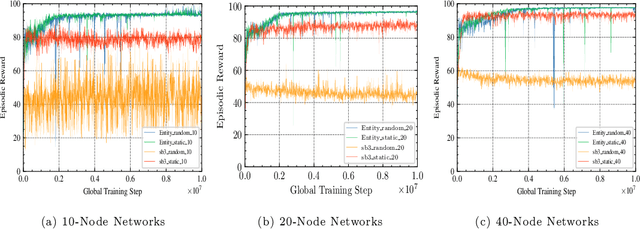
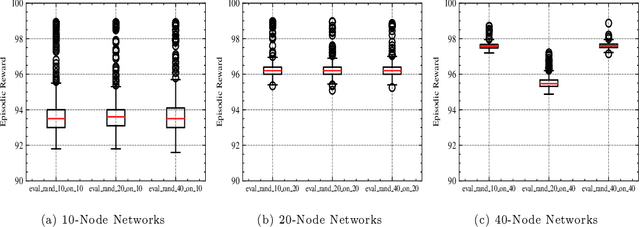
A significant challenge for autonomous cyber defence is ensuring a defensive agent's ability to generalise across diverse network topologies and configurations. This capability is necessary for agents to remain effective when deployed in dynamically changing environments, such as an enterprise network where devices may frequently join and leave. Standard approaches to deep reinforcement learning, where policies are parameterised using a fixed-input multi-layer perceptron (MLP) expect fixed-size observation and action spaces. In autonomous cyber defence, this makes it hard to develop agents that generalise to environments with network topologies different from those trained on, as the number of nodes affects the natural size of the observation and action spaces. To overcome this limitation, we reframe the problem of autonomous network defence using entity-based reinforcement learning, where the observation and action space of an agent are decomposed into a collection of discrete entities. This framework enables the use of policy parameterisations specialised in compositional generalisation. Namely, we train a Transformer-based policy on the Yawning Titan cyber-security simulation environment and test its generalisation capabilities across various network topologies. We demonstrate that this approach significantly outperforms an MLP-based policy on fixed networks, and has the ability for zero-shot generalisation to networks of a different size to those seen in training. These findings highlight the potential for entity-based reinforcement learning to advance the field of autonomous cyber defence by providing more generalisable policies capable of handling variations in real-world network environments.
A View on Out-of-Distribution Identification from a Statistical Testing Theory Perspective
May 08, 2024We study the problem of efficiently detecting Out-of-Distribution (OOD) samples at test time in supervised and unsupervised learning contexts. While ML models are typically trained under the assumption that training and test data stem from the same distribution, this is often not the case in realistic settings, thus reliably detecting distribution shifts is crucial at deployment. We re-formulate the OOD problem under the lenses of statistical testing and then discuss conditions that render the OOD problem identifiable in statistical terms. Building on this framework, we study convergence guarantees of an OOD test based on the Wasserstein distance, and provide a simple empirical evaluation.
Structure Learning with Adaptive Random Neighborhood Informed MCMC
Nov 01, 2023


In this paper, we introduce a novel MCMC sampler, PARNI-DAG, for a fully-Bayesian approach to the problem of structure learning under observational data. Under the assumption of causal sufficiency, the algorithm allows for approximate sampling directly from the posterior distribution on Directed Acyclic Graphs (DAGs). PARNI-DAG performs efficient sampling of DAGs via locally informed, adaptive random neighborhood proposal that results in better mixing properties. In addition, to ensure better scalability with the number of nodes, we couple PARNI-DAG with a pre-tuning procedure of the sampler's parameters that exploits a skeleton graph derived through some constraint-based or scoring-based algorithms. Thanks to these novel features, PARNI-DAG quickly converges to high-probability regions and is less likely to get stuck in local modes in the presence of high correlation between nodes in high-dimensional settings. After introducing the technical novelties in PARNI-DAG, we empirically demonstrate its mixing efficiency and accuracy in learning DAG structures on a variety of experiments.
Counterfactual Learning with Multioutput Deep Kernels
Nov 20, 2022In this paper, we address the challenge of performing counterfactual inference with observational data via Bayesian nonparametric regression adjustment, with a focus on high-dimensional settings featuring multiple actions and multiple correlated outcomes. We present a general class of counterfactual multi-task deep kernels models that estimate causal effects and learn policies proficiently thanks to their sample efficiency gains, while scaling well with high dimensions. In the first part of the work, we rely on Structural Causal Models (SCM) to formally introduce the setup and the problem of identifying counterfactual quantities under observed confounding. We then discuss the benefits of tackling the task of causal effects estimation via stacked coregionalized Gaussian Processes and Deep Kernels. Finally, we demonstrate the use of the proposed methods on simulated experiments that span individual causal effects estimation, off-policy evaluation and optimization.
Interpretable Deep Causal Learning for Moderation Effects
Jul 07, 2022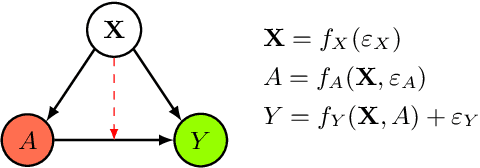

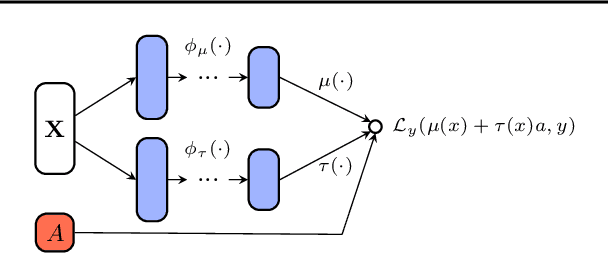
In this extended abstract paper, we address the problem of interpretability and targeted regularization in causal machine learning models. In particular, we focus on the problem of estimating individual causal/treatment effects under observed confounders, which can be controlled for and moderate the effect of the treatment on the outcome of interest. Black-box ML models adjusted for the causal setting perform generally well in this task, but they lack interpretable output identifying the main drivers of treatment heterogeneity and their functional relationship. We propose a novel deep counterfactual learning architecture for estimating individual treatment effects that can simultaneously: i) convey targeted regularization on, and produce quantify uncertainty around the quantity of interest (i.e., the Conditional Average Treatment Effect); ii) disentangle baseline prognostic and moderating effects of the covariates and output interpretable score functions describing their relationship with the outcome. Finally, we demonstrate the use of the method via a simple simulated experiment.
Sparse Bayesian Causal Forests for Heterogeneous Treatment Effects Estimation
Feb 12, 2021
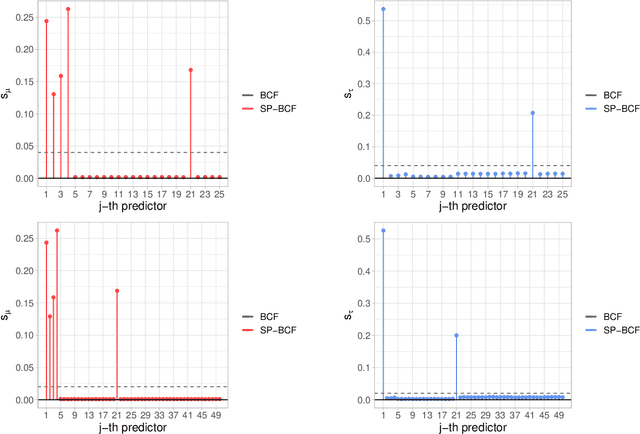
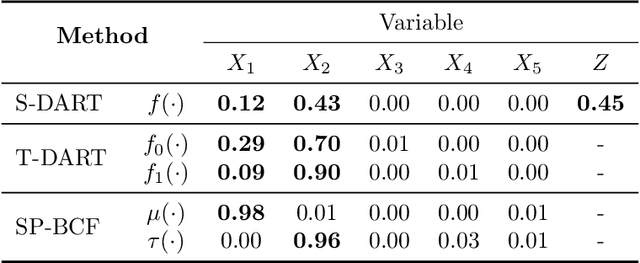
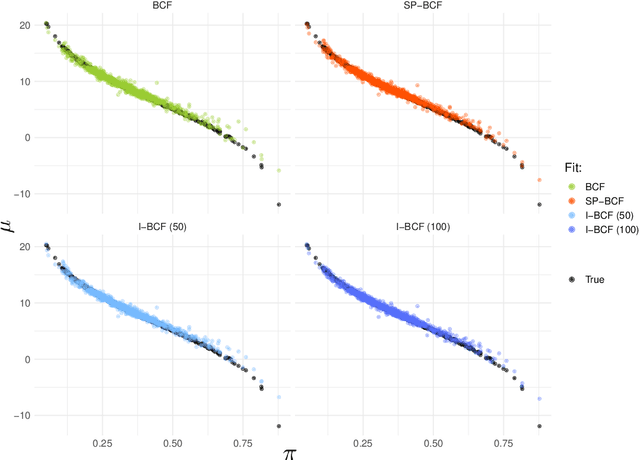
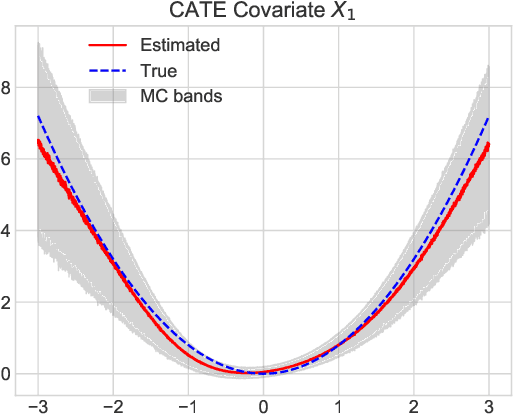
This paper develops a sparsity-inducing version of Bayesian Causal Forests, a recently proposed nonparametric causal regression model that employs Bayesian Additive Regression Trees and is specifically designed to estimate heterogeneous treatment effects using observational data. The sparsity-inducing component we introduce is motivated by empirical studies where the number of pre-treatment covariates available is non-negligible, leading to different degrees of sparsity underlying the surfaces of interest in the estimation of individual treatment effects. The extended version presented in this work, which we name Sparse Bayesian Causal Forest, is equipped with an additional pair of priors allowing the model to adjust the weight of each covariate through the corresponding number of splits in the tree ensemble. These priors improve the model's adaptability to sparse settings and allow to perform fully Bayesian variable selection in a framework for treatment effects estimation, and thus to uncover the moderating factors driving heterogeneity. In addition, the method allows prior knowledge about the relevant confounding pre-treatment covariates and the relative magnitude of their impact on the outcome to be incorporated in the model. We illustrate the performance of our method in simulated studies, in comparison to Bayesian Causal Forest and other state-of-the-art models, to demonstrate how it scales up with an increasing number of covariates and how it handles strongly confounded scenarios. Finally, we also provide an example of application using real-world data.