 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBuilding Better Environments for Autonomous Cyber Defence
Apr 09, 2026In November 2025, the authors ran a workshop on the topic of what makes a good reinforcement learning (RL) environment for autonomous cyber defence (ACD). This paper details the knowledge shared by participants both during the workshop and shortly afterwards by contributing herein. The workshop participants come from academia, industry, and government, and have extensive hands-on experience designing and working with RL and cyber environments. While there is now a sizeable body of literature describing work in RL for ACD, there is nevertheless a great deal of tradecraft, domain knowledge, and common hazards which are not detailed comprehensively in a single resource. With a specific focus on building better environments to train and evaluate autonomous RL agents in network defence scenarios, including government and critical infrastructure networks, the contributions of this work are twofold: (1) a framework for decomposing the interface between RL cyber environments and real systems, and (2) guidelines on current best practice for RL-based ACD environment development and agent evaluation, based on the key findings from our workshop.
An Attentive Graph Agent for Topology-Adaptive Cyber Defence
Jan 24, 2025As cyber threats grow increasingly sophisticated, reinforcement learning is emerging as a promising technique to create intelligent, self-improving defensive systems. However, most existing autonomous defensive agents have overlooked the inherent graph structure of computer networks subject to cyber attacks, potentially missing critical information. To address this gap, we developed a custom version of the Cyber Operations Research Gym (CybORG) environment that encodes the observable network state as a directed graph, utilizing realistic and interpretable low-level features. %, like number of open ports and unexpected detected connections. We leverage a Graph Attention Network (GAT) architecture to process node, edge, and global features, and modify its output to be compatible with policy gradient methods in reinforcement learning. GAT policies offer several advantages over standard approaches based on simplistic flattened state observations. They can handle the changes in network topology that occur at runtime when dynamic connections between hosts appear. Policies can be deployed to networks that differ in size to the ones seen during training, enabling a degree of generalisation inaccessible with alternative approaches. Furthermore, the graph neural network policies outputs are explainable in terms of tangible network properties, providing enhanced interpretability of defensive actions. We verify that our low-level graph observations are meaningful enough to train GAT defensive policies that are able to adapt to changing topologies. We evaluate how our trained policies perform when deployed on networks of varying sizes with the same subnetwork structure, comparing them against policies specifically trained for each network configuration. Our study contributes to the development of robust cyber defence systems that can better adapt to real-world network security challenges.
Entity-based Reinforcement Learning for Autonomous Cyber Defence
Oct 23, 2024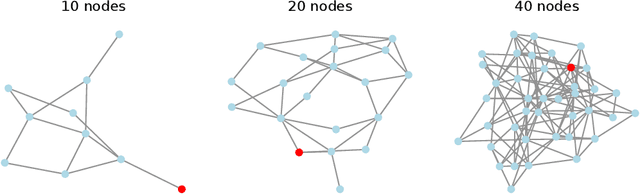
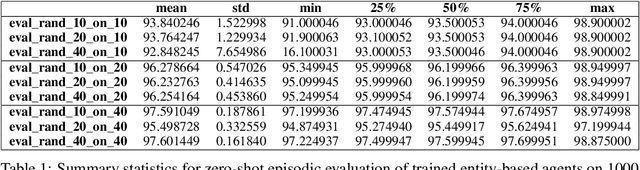
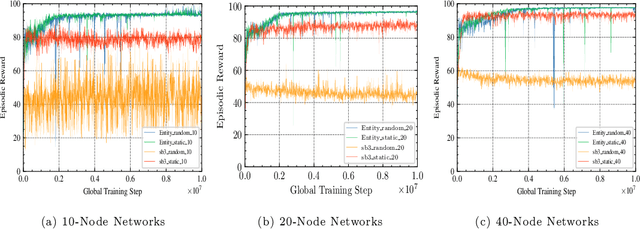
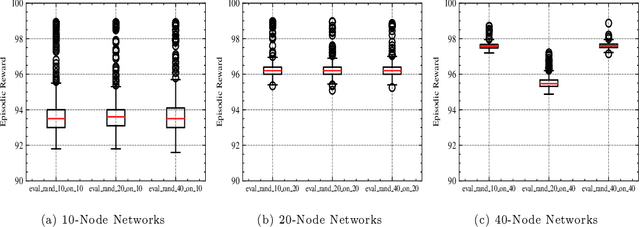
A significant challenge for autonomous cyber defence is ensuring a defensive agent's ability to generalise across diverse network topologies and configurations. This capability is necessary for agents to remain effective when deployed in dynamically changing environments, such as an enterprise network where devices may frequently join and leave. Standard approaches to deep reinforcement learning, where policies are parameterised using a fixed-input multi-layer perceptron (MLP) expect fixed-size observation and action spaces. In autonomous cyber defence, this makes it hard to develop agents that generalise to environments with network topologies different from those trained on, as the number of nodes affects the natural size of the observation and action spaces. To overcome this limitation, we reframe the problem of autonomous network defence using entity-based reinforcement learning, where the observation and action space of an agent are decomposed into a collection of discrete entities. This framework enables the use of policy parameterisations specialised in compositional generalisation. Namely, we train a Transformer-based policy on the Yawning Titan cyber-security simulation environment and test its generalisation capabilities across various network topologies. We demonstrate that this approach significantly outperforms an MLP-based policy on fixed networks, and has the ability for zero-shot generalisation to networks of a different size to those seen in training. These findings highlight the potential for entity-based reinforcement learning to advance the field of autonomous cyber defence by providing more generalisable policies capable of handling variations in real-world network environments.