 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStructure Learning with Adaptive Random Neighborhood Informed MCMC
Nov 01, 2023


In this paper, we introduce a novel MCMC sampler, PARNI-DAG, for a fully-Bayesian approach to the problem of structure learning under observational data. Under the assumption of causal sufficiency, the algorithm allows for approximate sampling directly from the posterior distribution on Directed Acyclic Graphs (DAGs). PARNI-DAG performs efficient sampling of DAGs via locally informed, adaptive random neighborhood proposal that results in better mixing properties. In addition, to ensure better scalability with the number of nodes, we couple PARNI-DAG with a pre-tuning procedure of the sampler's parameters that exploits a skeleton graph derived through some constraint-based or scoring-based algorithms. Thanks to these novel features, PARNI-DAG quickly converges to high-probability regions and is less likely to get stuck in local modes in the presence of high correlation between nodes in high-dimensional settings. After introducing the technical novelties in PARNI-DAG, we empirically demonstrate its mixing efficiency and accuracy in learning DAG structures on a variety of experiments.
Optimal design of the Barker proposal and other locally-balanced Metropolis-Hastings algorithms
Jan 04, 2022

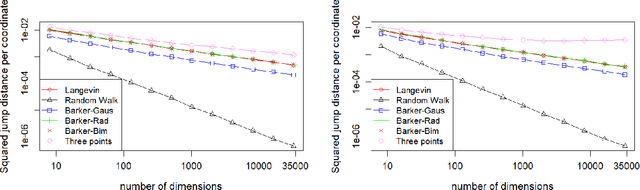

We study the class of first-order locally-balanced Metropolis--Hastings algorithms introduced in Livingstone & Zanella (2021). To choose a specific algorithm within the class the user must select a balancing function $g:\mathbb{R} \to \mathbb{R}$ satisfying $g(t) = tg(1/t)$, and a noise distribution for the proposal increment. Popular choices within the class are the Metropolis-adjusted Langevin algorithm and the recently introduced Barker proposal. We first establish a universal limiting optimal acceptance rate of 57% and scaling of $n^{-1/3}$ as the dimension $n$ tends to infinity among all members of the class under mild smoothness assumptions on $g$ and when the target distribution for the algorithm is of the product form. In particular we obtain an explicit expression for the asymptotic efficiency of an arbitrary algorithm in the class, as measured by expected squared jumping distance. We then consider how to optimise this expression under various constraints. We derive an optimal choice of noise distribution for the Barker proposal, optimal choice of balancing function under a Gaussian noise distribution, and optimal choice of first-order locally-balanced algorithm among the entire class, which turns out to depend on the specific target distribution. Numerical simulations confirm our theoretical findings and in particular show that a bi-modal choice of noise distribution in the Barker proposal gives rise to a practical algorithm that is consistently more efficient than the original Gaussian version.
On the Geometric Ergodicity of Hamiltonian Monte Carlo
Apr 13, 2018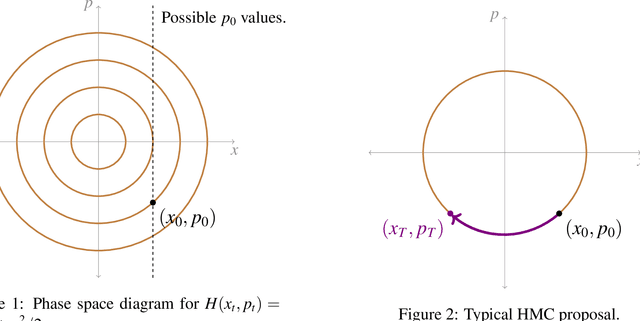
We establish general conditions under which Markov chains produced by the Hamiltonian Monte Carlo method will and will not be geometrically ergodic. We consider implementations with both position-independent and position-dependent integration times. In the former case we find that the conditions for geometric ergodicity are essentially a non-vanishing gradient of the log-density which asymptotically points towards the centre of the space and does not grow faster than linearly. In an idealised scenario in which the integration time is allowed to change in different regions of the space, we show that geometric ergodicity can be recovered for a much broader class of tail behaviours, leading to some guidelines for the choice of this free parameter in practice.
Gradient-free Hamiltonian Monte Carlo with Efficient Kernel Exponential Families
Nov 24, 2015



We propose Kernel Hamiltonian Monte Carlo (KMC), a gradient-free adaptive MCMC algorithm based on Hamiltonian Monte Carlo (HMC). On target densities where classical HMC is not an option due to intractable gradients, KMC adaptively learns the target's gradient structure by fitting an exponential family model in a Reproducing Kernel Hilbert Space. Computational costs are reduced by two novel efficient approximations to this gradient. While being asymptotically exact, KMC mimics HMC in terms of sampling efficiency, and offers substantial mixing improvements over state-of-the-art gradient free samplers. We support our claims with experimental studies on both toy and real-world applications, including Approximate Bayesian Computation and exact-approximate MCMC.
* 20 pages, 7 figures