 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEfficient Inference after Directionally Stable Adaptive Experiments
Feb 25, 2026We study inference on scalar-valued pathwise differentiable targets after adaptive data collection, such as a bandit algorithm. We introduce a novel target-specific condition, directional stability, which is strictly weaker than previously imposed target-agnostic stability conditions. Under directional stability, we show that estimators that would have been efficient under i.i.d. data remain asymptotically normal and semiparametrically efficient when computed from adaptively collected trajectories. The canonical gradient has a martingale form, and directional stability guarantees stabilization of its predictable quadratic variation, enabling high-dimensional asymptotic normality. We characterize efficiency using a convolution theorem for the adaptive-data setting, and give a condition under which the one-step estimator attains the efficiency bound. We verify directional stability for LinUCB, yielding the first semiparametric efficiency guarantee for a regular scalar target under LinUCB sampling.
Regularized $f$-Divergence Kernel Tests
Jan 27, 2026We propose a framework to construct practical kernel-based two-sample tests from the family of $f$-divergences. The test statistic is computed from the witness function of a regularized variational representation of the divergence, which we estimate using kernel methods. The proposed test is adaptive over hyperparameters such as the kernel bandwidth and the regularization parameter. We provide theoretical guarantees for statistical test power across our family of $f$-divergence estimates. While our test covers a variety of $f$-divergences, we bring particular focus to the Hockey-Stick divergence, motivated by its applications to differential privacy auditing and machine unlearning evaluation. For two-sample testing, experiments demonstrate that different $f$-divergences are sensitive to different localized differences, illustrating the importance of leveraging diverse statistics. For machine unlearning, we propose a relative test that distinguishes true unlearning failures from safe distributional variations.
On the Hardness of Conditional Independence Testing In Practice
Dec 16, 2025Tests of conditional independence (CI) underpin a number of important problems in machine learning and statistics, from causal discovery to evaluation of predictor fairness and out-of-distribution robustness. Shah and Peters (2020) showed that, contrary to the unconditional case, no universally finite-sample valid test can ever achieve nontrivial power. While informative, this result (based on "hiding" dependence) does not seem to explain the frequent practical failures observed with popular CI tests. We investigate the Kernel-based Conditional Independence (KCI) test - of which we show the Generalized Covariance Measure underlying many recent tests is nearly a special case - and identify the major factors underlying its practical behavior. We highlight the key role of errors in the conditional mean embedding estimate for the Type-I error, while pointing out the importance of selecting an appropriate conditioning kernel (not recognized in previous work) as being necessary for good test power but also tending to inflate Type-I error.
Towards a Unified Analysis of Neural Networks in Nonparametric Instrumental Variable Regression: Optimization and Generalization
Nov 18, 2025We establish the first global convergence result of neural networks for two stage least squares (2SLS) approach in nonparametric instrumental variable regression (NPIV). This is achieved by adopting a lifted perspective through mean-field Langevin dynamics (MFLD), unlike standard MFLD, however, our setting of 2SLS entails a \emph{bilevel} optimization problem in the space of probability measures. To address this challenge, we leverage the penalty gradient approach recently developed for bilevel optimization which formulates bilevel optimization as a Lagrangian problem. This leads to a novel fully first-order algorithm, termed \texttt{F$^2$BMLD}. Apart from the convergence bound, we further provide a generalization bound, revealing an inherent trade-off in the choice of the Lagrange multiplier between optimization and statistical guarantees. Finally, we empirically validate the effectiveness of the proposed method on an offline reinforcement learning benchmark.
Closed-Form Last Layer Optimization
Oct 06, 2025Neural networks are typically optimized with variants of stochastic gradient descent. Under a squared loss, however, the optimal solution to the linear last layer weights is known in closed-form. We propose to leverage this during optimization, treating the last layer as a function of the backbone parameters, and optimizing solely for these parameters. We show this is equivalent to alternating between gradient descent steps on the backbone and closed-form updates on the last layer. We adapt the method for the setting of stochastic gradient descent, by trading off the loss on the current batch against the accumulated information from previous batches. Further, we prove that, in the Neural Tangent Kernel regime, convergence of this method to an optimal solution is guaranteed. Finally, we demonstrate the effectiveness of our approach compared with standard SGD on a squared loss in several supervised tasks -- both regression and classification -- including Fourier Neural Operators and Instrumental Variable Regression.
Learn to Guide Your Diffusion Model
Oct 01, 2025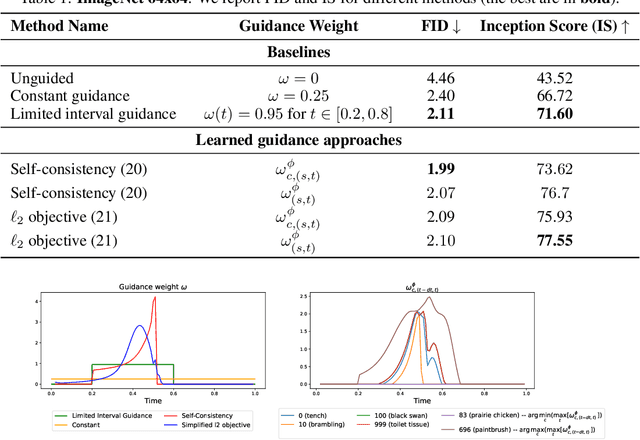
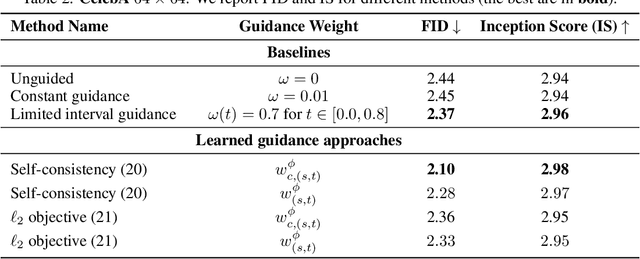
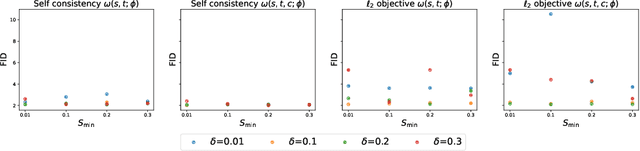

Classifier-free guidance (CFG) is a widely used technique for improving the perceptual quality of samples from conditional diffusion models. It operates by linearly combining conditional and unconditional score estimates using a guidance weight $\omega$. While a large, static weight can markedly improve visual results, this often comes at the cost of poorer distributional alignment. In order to better approximate the target conditional distribution, we instead learn guidance weights $\omega_{c,(s,t)}$, which are continuous functions of the conditioning $c$, the time $t$ from which we denoise, and the time $s$ towards which we denoise. We achieve this by minimizing the distributional mismatch between noised samples from the true conditional distribution and samples from the guided diffusion process. We extend our framework to reward guided sampling, enabling the model to target distributions tilted by a reward function $R(x_0,c)$, defined on clean data and a conditioning $c$. We demonstrate the effectiveness of our methodology on low-dimensional toy examples and high-dimensional image settings, where we observe improvements in Fr\'echet inception distance (FID) for image generation. In text-to-image applications, we observe that employing a reward function given by the CLIP score leads to guidance weights that improve image-prompt alignment.
Demystifying Spectral Feature Learning for Instrumental Variable Regression
Jun 12, 2025We address the problem of causal effect estimation in the presence of hidden confounders, using nonparametric instrumental variable (IV) regression. A leading strategy employs spectral features - that is, learned features spanning the top eigensubspaces of the operator linking treatments to instruments. We derive a generalization error bound for a two-stage least squares estimator based on spectral features, and gain insights into the method's performance and failure modes. We show that performance depends on two key factors, leading to a clear taxonomy of outcomes. In a good scenario, the approach is optimal. This occurs with strong spectral alignment, meaning the structural function is well-represented by the top eigenfunctions of the conditional operator, coupled with this operator's slow eigenvalue decay, indicating a strong instrument. Performance degrades in a bad scenario: spectral alignment remains strong, but rapid eigenvalue decay (indicating a weaker instrument) demands significantly more samples for effective feature learning. Finally, in the ugly scenario, weak spectral alignment causes the method to fail, regardless of the eigenvalues' characteristics. Our synthetic experiments empirically validate this taxonomy.
Density Ratio-Free Doubly Robust Proxy Causal Learning
May 26, 2025We study the problem of causal function estimation in the Proxy Causal Learning (PCL) framework, where confounders are not observed but proxies for the confounders are available. Two main approaches have been proposed: outcome bridge-based and treatment bridge-based methods. In this work, we propose two kernel-based doubly robust estimators that combine the strengths of both approaches, and naturally handle continuous and high-dimensional variables. Our identification strategy builds on a recent density ratio-free method for treatment bridge-based PCL; furthermore, in contrast to previous approaches, it does not require indicator functions or kernel smoothing over the treatment variable. These properties make it especially well-suited for continuous or high-dimensional treatments. By using kernel mean embeddings, we have closed-form solutions and strong consistency guarantees. Our estimators outperform existing methods on PCL benchmarks, including a prior doubly robust method that requires both kernel smoothing and density ratio estimation.
Regularized least squares learning with heavy-tailed noise is minimax optimal
May 20, 2025
This paper examines the performance of ridge regression in reproducing kernel Hilbert spaces in the presence of noise that exhibits a finite number of higher moments. We establish excess risk bounds consisting of subgaussian and polynomial terms based on the well known integral operator framework. The dominant subgaussian component allows to achieve convergence rates that have previously only been derived under subexponential noise - a prevalent assumption in related work from the last two decades. These rates are optimal under standard eigenvalue decay conditions, demonstrating the asymptotic robustness of regularized least squares against heavy-tailed noise. Our derivations are based on a Fuk-Nagaev inequality for Hilbert-space valued random variables.
Density Ratio-based Proxy Causal Learning Without Density Ratios
Mar 11, 2025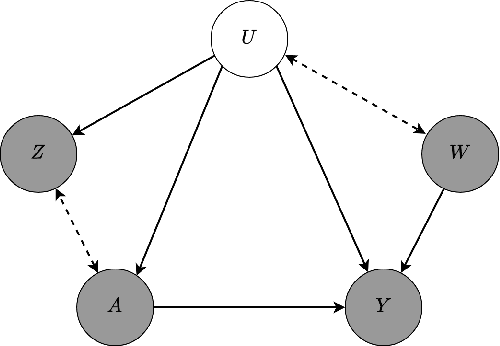
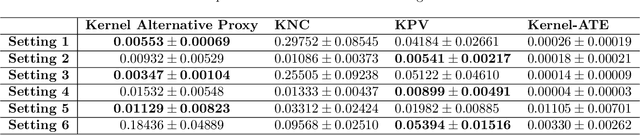
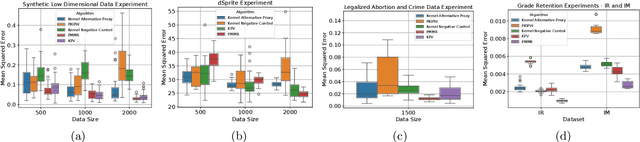
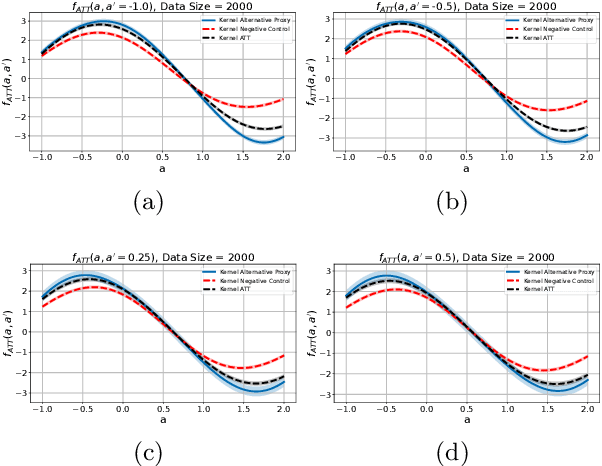
We address the setting of Proxy Causal Learning (PCL), which has the goal of estimating causal effects from observed data in the presence of hidden confounding. Proxy methods accomplish this task using two proxy variables related to the latent confounder: a treatment proxy (related to the treatment) and an outcome proxy (related to the outcome). Two approaches have been proposed to perform causal effect estimation given proxy variables; however only one of these has found mainstream acceptance, since the other was understood to require density ratio estimation - a challenging task in high dimensions. In the present work, we propose a practical and effective implementation of the second approach, which bypasses explicit density ratio estimation and is suitable for continuous and high-dimensional treatments. We employ kernel ridge regression to derive estimators, resulting in simple closed-form solutions for dose-response and conditional dose-response curves, along with consistency guarantees. Our methods empirically demonstrate superior or comparable performance to existing frameworks on synthetic and real-world datasets.