 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentity, Cooperation and Framing Effects within Groups of Real and Simulated Humans
Jan 22, 2026Humans act via a nuanced process that depends both on rational deliberation and also on identity and contextual factors. In this work, we study how large language models (LLMs) can simulate human action in the context of social dilemma games. While prior work has focused on "steering" (weak binding) of chat models to simulate personas, we analyze here how deep binding of base models with extended backstories leads to more faithful replication of identity-based behaviors. Our study has these findings: simulation fidelity vs human studies is improved by conditioning base LMs with rich context of narrative identities and checking consistency using instruction-tuned models. We show that LLMs can also model contextual factors such as time (year that a study was performed), question framing, and participant pool effects. LLMs, therefore, allow us to explore the details that affect human studies but which are often omitted from experiment descriptions, and which hamper accurate replication.
Sleepless Nights, Sugary Days: Creating Synthetic Users with Health Conditions for Realistic Coaching Agent Interactions
Feb 18, 2025We present an end-to-end framework for generating synthetic users for evaluating interactive agents designed to encourage positive behavior changes, such as in health and lifestyle coaching. The synthetic users are grounded in health and lifestyle conditions, specifically sleep and diabetes management in this study, to ensure realistic interactions with the health coaching agent. Synthetic users are created in two stages: first, structured data are generated grounded in real-world health and lifestyle factors in addition to basic demographics and behavioral attributes; second, full profiles of the synthetic users are developed conditioned on the structured data. Interactions between synthetic users and the coaching agent are simulated using generative agent-based models such as Concordia, or directly by prompting a language model. Using two independently-developed agents for sleep and diabetes coaching as case studies, the validity of this framework is demonstrated by analyzing the coaching agent's understanding of the synthetic users' needs and challenges. Finally, through multiple blinded evaluations of user-coach interactions by human experts, we demonstrate that our synthetic users with health and behavioral attributes more accurately portray real human users with the same attributes, compared to generic synthetic users not grounded in such attributes. The proposed framework lays the foundation for efficient development of conversational agents through extensive, realistic, and grounded simulated interactions.
A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis
Jul 24, 2023



Pre-trained large language models (LLMs) have recently achieved better generalization and sample efficiency in autonomous web navigation. However, the performance on real-world websites has still suffered from (1) open domainness, (2) limited context length, and (3) lack of inductive bias on HTML. We introduce WebAgent, an LLM-driven agent that can complete the tasks on real websites following natural language instructions. WebAgent plans ahead by decomposing instructions into canonical sub-instructions, summarizes long HTML documents into task-relevant snippets, and acts on websites via generated Python programs from those. We design WebAgent with Flan-U-PaLM, for grounded code generation, and HTML-T5, new pre-trained LLMs for long HTML documents using local and global attention mechanisms and a mixture of long-span denoising objectives, for planning and summarization. We empirically demonstrate that our recipe improves the success on a real website by over 50%, and that HTML-T5 is the best model to solve HTML-based tasks; achieving 14.9% higher success rate than prior SoTA on the MiniWoB web navigation benchmark and better accuracy on offline task planning evaluation.
Personality Traits in Large Language Models
Jul 01, 2023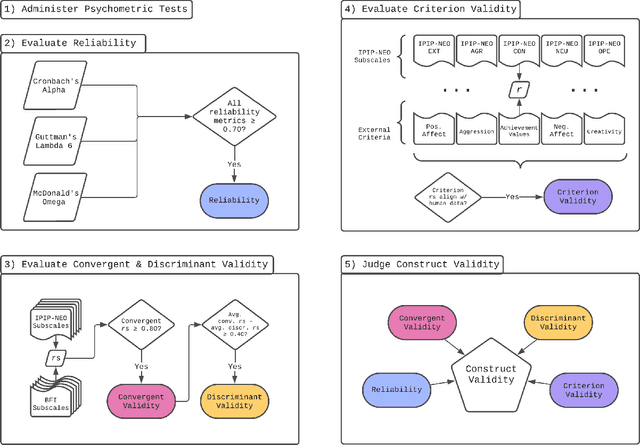

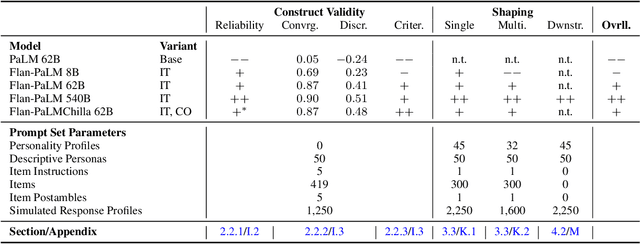
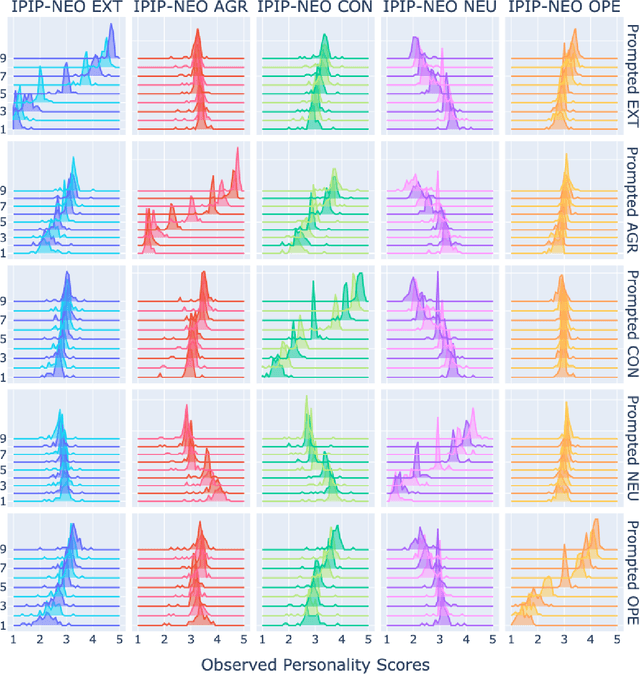
The advent of large language models (LLMs) has revolutionized natural language processing, enabling the generation of coherent and contextually relevant text. As LLMs increasingly power conversational agents, the synthesized personality embedded in these models by virtue of their training on large amounts of human-generated data draws attention. Since personality is an important factor determining the effectiveness of communication, we present a comprehensive method for administering validated psychometric tests and quantifying, analyzing, and shaping personality traits exhibited in text generated from widely-used LLMs. We find that: 1) personality simulated in the outputs of some LLMs (under specific prompting configurations) is reliable and valid; 2) evidence of reliability and validity of LLM-simulated personality is stronger for larger and instruction fine-tuned models; and 3) personality in LLM outputs can be shaped along desired dimensions to mimic specific personality profiles. We also discuss potential applications and ethical implications of our measurement and shaping framework, especially regarding responsible use of LLMs.
Understanding HTML with Large Language Models
Oct 08, 2022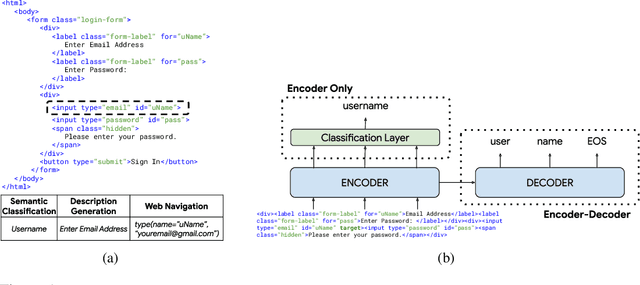

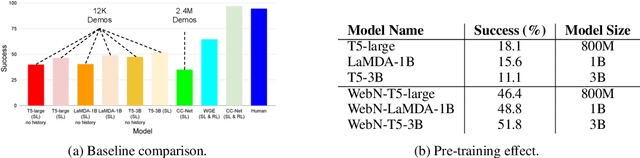
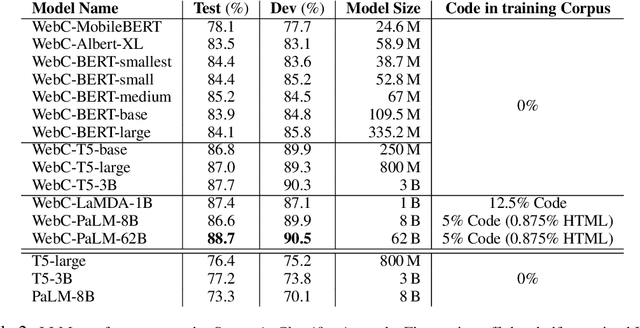
Large language models (LLMs) have shown exceptional performance on a variety of natural language tasks. Yet, their capabilities for HTML understanding -- i.e., parsing the raw HTML of a webpage, with applications to automation of web-based tasks, crawling, and browser-assisted retrieval -- have not been fully explored. We contribute HTML understanding models (fine-tuned LLMs) and an in-depth analysis of their capabilities under three tasks: (i) Semantic Classification of HTML elements, (ii) Description Generation for HTML inputs, and (iii) Autonomous Web Navigation of HTML pages. While previous work has developed dedicated architectures and training procedures for HTML understanding, we show that LLMs pretrained on standard natural language corpora transfer remarkably well to HTML understanding tasks. For instance, fine-tuned LLMs are 12% more accurate at semantic classification compared to models trained exclusively on the task dataset. Moreover, when fine-tuned on data from the MiniWoB benchmark, LLMs successfully complete 50% more tasks using 192x less data compared to the previous best supervised model. Out of the LLMs we evaluate, we show evidence that T5-based models are ideal due to their bidirectional encoder-decoder architecture. To promote further research on LLMs for HTML understanding, we create and open-source a large-scale HTML dataset distilled and auto-labeled from CommonCrawl.