 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLive Music Models
Aug 06, 2025We introduce a new class of generative models for music called live music models that produce a continuous stream of music in real-time with synchronized user control. We release Magenta RealTime, an open-weights live music model that can be steered using text or audio prompts to control acoustic style. On automatic metrics of music quality, Magenta RealTime outperforms other open-weights music generation models, despite using fewer parameters and offering first-of-its-kind live generation capabilities. We also release Lyria RealTime, an API-based model with extended controls, offering access to our most powerful model with wide prompt coverage. These models demonstrate a new paradigm for AI-assisted music creation that emphasizes human-in-the-loop interaction for live music performance.
Imagen 3
Aug 13, 2024We introduce Imagen 3, a latent diffusion model that generates high quality images from text prompts. We describe our quality and responsibility evaluations. Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation. In addition, we discuss issues around safety and representation, as well as methods we used to minimize the potential harm of our models.
Gemma: Open Models Based on Gemini Research and Technology
Mar 13, 2024



This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
A Real-World WebAgent with Planning, Long Context Understanding, and Program Synthesis
Jul 24, 2023



Pre-trained large language models (LLMs) have recently achieved better generalization and sample efficiency in autonomous web navigation. However, the performance on real-world websites has still suffered from (1) open domainness, (2) limited context length, and (3) lack of inductive bias on HTML. We introduce WebAgent, an LLM-driven agent that can complete the tasks on real websites following natural language instructions. WebAgent plans ahead by decomposing instructions into canonical sub-instructions, summarizes long HTML documents into task-relevant snippets, and acts on websites via generated Python programs from those. We design WebAgent with Flan-U-PaLM, for grounded code generation, and HTML-T5, new pre-trained LLMs for long HTML documents using local and global attention mechanisms and a mixture of long-span denoising objectives, for planning and summarization. We empirically demonstrate that our recipe improves the success on a real website by over 50%, and that HTML-T5 is the best model to solve HTML-based tasks; achieving 14.9% higher success rate than prior SoTA on the MiniWoB web navigation benchmark and better accuracy on offline task planning evaluation.
PaLM: Scaling Language Modeling with Pathways
Apr 19, 2022



Large language models have been shown to achieve remarkable performance across a variety of natural language tasks using few-shot learning, which drastically reduces the number of task-specific training examples needed to adapt the model to a particular application. To further our understanding of the impact of scale on few-shot learning, we trained a 540-billion parameter, densely activated, Transformer language model, which we call Pathways Language Model PaLM. We trained PaLM on 6144 TPU v4 chips using Pathways, a new ML system which enables highly efficient training across multiple TPU Pods. We demonstrate continued benefits of scaling by achieving state-of-the-art few-shot learning results on hundreds of language understanding and generation benchmarks. On a number of these tasks, PaLM 540B achieves breakthrough performance, outperforming the finetuned state-of-the-art on a suite of multi-step reasoning tasks, and outperforming average human performance on the recently released BIG-bench benchmark. A significant number of BIG-bench tasks showed discontinuous improvements from model scale, meaning that performance steeply increased as we scaled to our largest model. PaLM also has strong capabilities in multilingual tasks and source code generation, which we demonstrate on a wide array of benchmarks. We additionally provide a comprehensive analysis on bias and toxicity, and study the extent of training data memorization with respect to model scale. Finally, we discuss the ethical considerations related to large language models and discuss potential mitigation strategies.
Deduplicating Training Data Makes Language Models Better
Jul 14, 2021
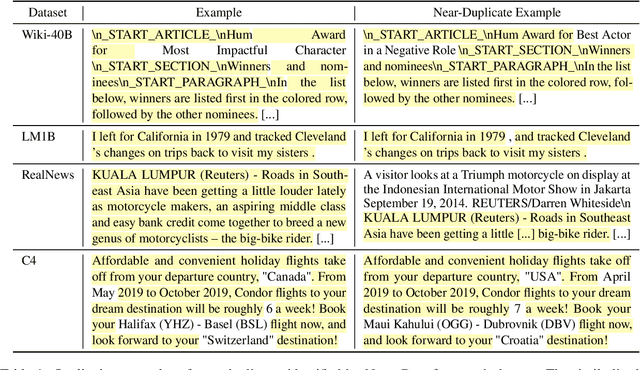
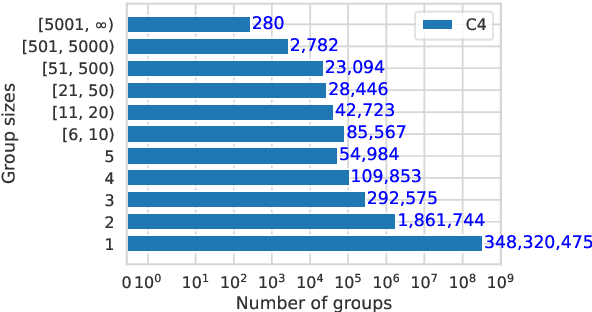
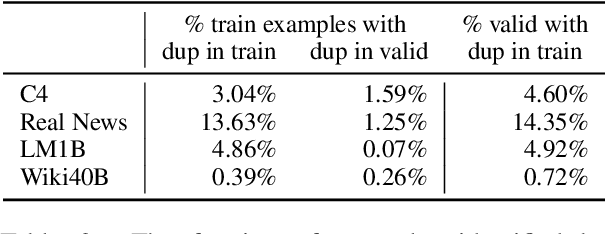
We find that existing language modeling datasets contain many near-duplicate examples and long repetitive substrings. As a result, over 1% of the unprompted output of language models trained on these datasets is copied verbatim from the training data. We develop two tools that allow us to deduplicate training datasets -- for example removing from C4 a single 61 word English sentence that is repeated over 60,000 times. Deduplication allows us to train models that emit memorized text ten times less frequently and require fewer train steps to achieve the same or better accuracy. We can also reduce train-test overlap, which affects over 4% of the validation set of standard datasets, thus allowing for more accurate evaluation. We release code for reproducing our work and performing dataset deduplication at https://github.com/google-research/deduplicate-text-datasets.
Joint Attention for Multi-Agent Coordination and Social Learning
Apr 15, 2021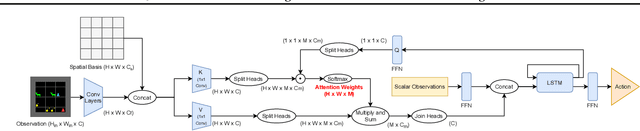
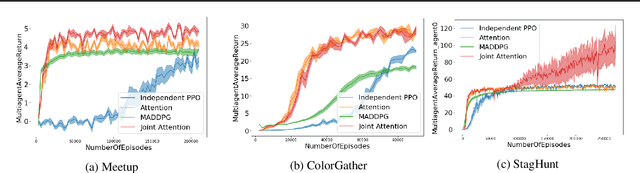
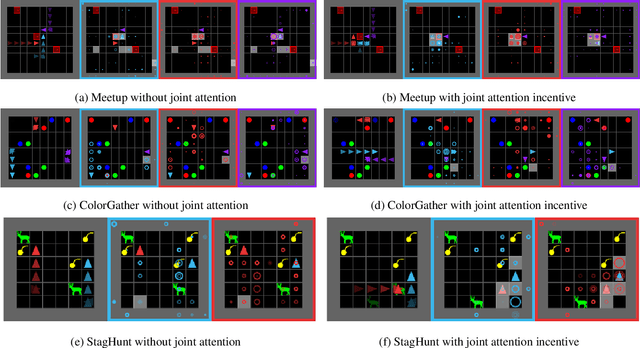
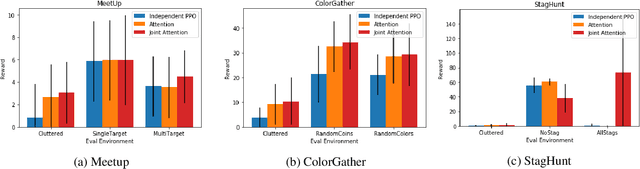
Joint attention - the ability to purposefully coordinate attention with another agent, and mutually attend to the same thing -- is a critical component of human social cognition. In this paper, we ask whether joint attention can be useful as a mechanism for improving multi-agent coordination and social learning. We first develop deep reinforcement learning (RL) agents with a recurrent visual attention architecture. We then train agents to minimize the difference between the attention weights that they apply to the environment at each timestep, and the attention of other agents. Our results show that this joint attention incentive improves agents' ability to solve difficult coordination tasks, by reducing the exponential cost of exploring the joint multi-agent action space. Joint attention leads to higher performance than a competitive centralized critic baseline across multiple environments. Further, we show that joint attention enhances agents' ability to learn from experts present in their environment, even when completing hard exploration tasks that do not require coordination. Taken together, these findings suggest that joint attention may be a useful inductive bias for multi-agent learning.
Multi-agent Social Reinforcement Learning Improves Generalization
Oct 01, 2020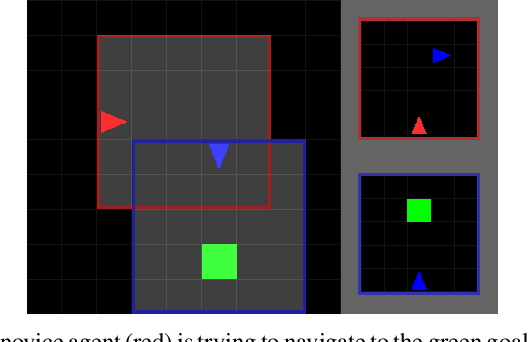
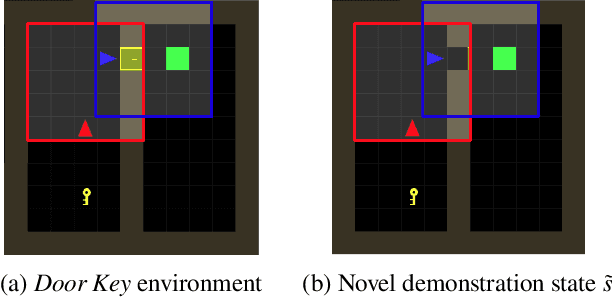
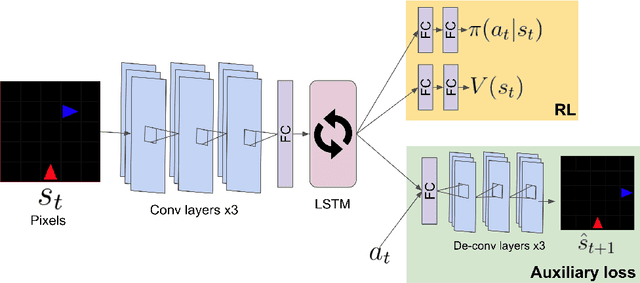
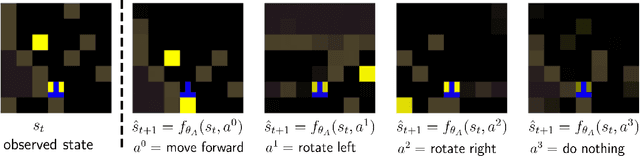
Social learning is a key component of human and animal intelligence. By taking cues from the behavior of experts in their environment, social learners can acquire sophisticated behavior and rapidly adapt to new circumstances. This paper investigates whether independent reinforcement learning (RL) agents in a multi-agent environment can use social learning to improve their performance using cues from other agents. We find that in most circumstances, vanilla model-free RL agents do not use social learning, even in environments in which individual exploration is expensive. We analyze the reasons for this deficiency, and show that by introducing a model-based auxiliary loss we are able to train agents to lever-age cues from experts to solve hard exploration tasks. The generalized social learning policy learned by these agents allows them to not only outperform the experts with which they trained, but also achieve better zero-shot transfer performance than solo learners when deployed to novel environments with experts. In contrast, agents that have not learned to rely on social learning generalize poorly and do not succeed in the transfer task. Further,we find that by mixing multi-agent and solo training, we can obtain agents that use social learning to out-perform agents trained alone, even when experts are not avail-able. This demonstrates that social learning has helped improve agents' representation of the task itself. Our results indicate that social learning can enable RL agents to not only improve performance on the task at hand, but improve generalization to novel environments.
Toward Better Storylines with Sentence-Level Language Models
May 11, 2020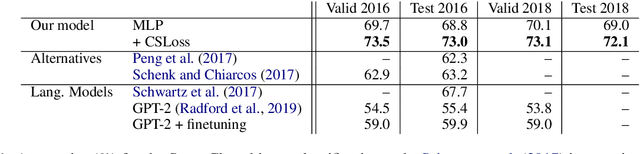
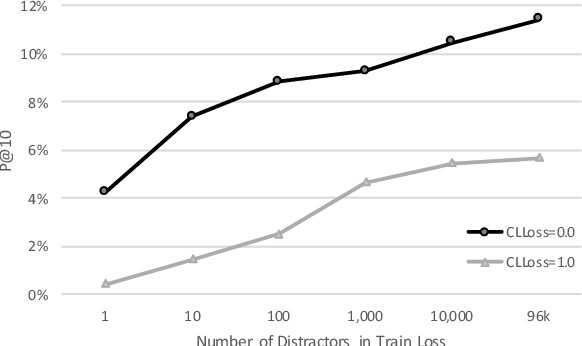
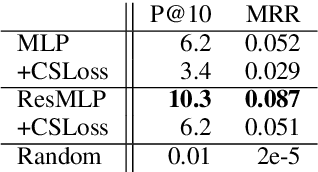
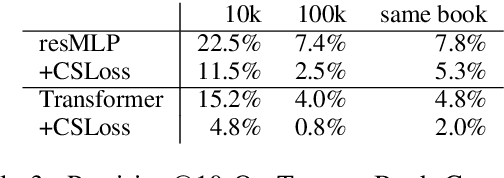
We propose a sentence-level language model which selects the next sentence in a story from a finite set of fluent alternatives. Since it does not need to model fluency, the sentence-level language model can focus on longer range dependencies, which are crucial for multi-sentence coherence. Rather than dealing with individual words, our method treats the story so far as a list of pre-trained sentence embeddings and predicts an embedding for the next sentence, which is more efficient than predicting word embeddings. Notably this allows us to consider a large number of candidates for the next sentence during training. We demonstrate the effectiveness of our approach with state-of-the-art accuracy on the unsupervised Story Cloze task and with promising results on larger-scale next sentence prediction tasks.
Human and Automatic Detection of Generated Text
Nov 02, 2019


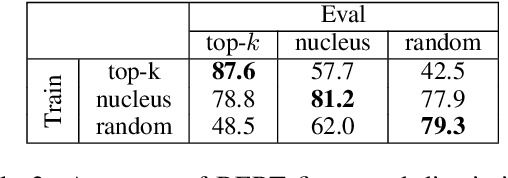
With the advent of generative models with a billion parameters or more, it is now possible to automatically generate vast amounts of human-sounding text. This raises questions into just how human-like is the machine-generated text, and how long does a text excerpt need to be for both humans and automatic discriminators to be able reliably detect that it was machine-generated. In this paper, we conduct a thorough investigation of how choices such as sampling strategy and text excerpt length can impact the performance of automatic detection methods as well as human raters. We find that the sampling strategies which result in more human-like text according to human raters create distributional differences from human-written text that make detection easy for automatic discriminators.