 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearn to Match: Two-Sided Matching with Temporally Extended Feedback
Jun 04, 2026Two-sided matching markets often involve information that unfolds over time through interviews, repeated interaction, learning, and separation. Existing matching models typically reduce this process to immediate sub-Gaussian feedback about fixed preferences, missing settings where payoff-relevant information is revealed gradually and changes future matching decisions. We introduce a framework with temporally extended feedback, that formulates two-sided matching as a partially observable Markov game with costly pre-match screening, noisy post-match observations, evolving latent profiles, and endogenous continuation or dissolution. We instantiate this framework in Learn2Match, a multi-agent reinforcement-learning benchmark for dynamic matching markets. Learn2Match supports decentralized decision making over whom to interview, whom to match with, and when to dissolve a match, while evaluating policies using regret, social welfare, and an information-friction loss that measures the welfare gap caused by incomplete revelation of latent preferences. We find that independent PPO achieves higher cumulative social welfare and lower cumulative regret than the bandit-style CA-ETC baseline under temporally extended feedback, demonstrating the promise of MARL for dynamic matching markets. However, PPO still incurs higher information-friction loss, revealing that end-to-end MARL does not yet provide the coordinated exploration structure of matching-bandit methods. These results position Learn2Match as a benchmark for developing the next generation of matching-market algorithms: methods that are adaptive like RL agents, statistically disciplined like bandit algorithms, and structurally aware like stable-matching mechanisms.
Solipsistic Superintelligence is Unlikely to be Cooperative
Jun 02, 2026AI's central challenge is shifting from capability to coexistence. The dominant paradigm in AI research focuses on developing powerful agents that treat the world as an exogenous and stationary source of feedback. We contend that superintelligence, an extremely capable task solver, born out of such a solipsistic approach to AI design, is unlikely to be cooperative. Deploying AI systems induces endogenous non-stationarity, resulting in a train-test-deploy gap where historical distributions diverge from the deployment context. We refer to this as the self-undermining property of unilateral optimization. Closing this gap requires AI that participates in cooperation: the equilibrium-selection process through which multiple actors navigate their interdependence. We call for a non-solipsistic research paradigm that treats this interdependence as a core design principle rather than approaching cooperation as a task to solve. This entails building dynamic evaluation testbeds involving adaptive counterparties, treating institutions as design primitives, and preserving human agency as a structural feature of the systems we build.
Beyond Cooperative Simulators: Generating Realistic User Personas for Robust Evaluation of LLM Agents
May 13, 2026Large Language Model (LLM) agents are increasingly deployed in settings where they interact with a wide variety of people, including users who are unclear, impatient, or reluctant to share information. However, collecting real interaction data at scale remains expensive. The field has turned to LLM-based user simulators as stand-ins, but these simulators inherit the behavior of their underlying models: cooperative and homogeneous. As a result, agents that appear strong in simulation often fail under the unseen, diverse communication patterns of real users. To narrow this gap, we introduce Persona Policies (PPol), a plug-and-play control layer that induces realistic behavioral variation in user simulators while preserving the original task goals. Rather than hand-crafting personas, we cast persona generation as an LLM-driven evolutionary program search that optimizes a Python generator to discover behaviors and translate them into task-preserving roleplay policies. Candidate generators are guided by a multi-objective fitness score combining human-likeness with broad coverage of human behavioral patterns. Once optimized, the generator produces a diverse population of human-like personas for any task in the domain. Across tau^2-bench retail and airline domains, evolved PPol programs yield 33-62% absolute gains in fitness score over the baseline simulator. In a blinded evaluation, annotators rated PPol-conditioned users as human 80.4% of the time, close to real human traces and nearly twice as frequently as baseline simulators. Agents trained with PPol are more robust to challenging, out-of-distribution behaviors, improving task success by +17% relative to training only on existing simulated interactions. This offers a novel approach to strengthen simulator-based evaluation and training without changing tasks or rewards.
LongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning
Apr 15, 2026As language models are increasingly deployed for complex autonomous tasks, their ability to reason accurately over longer horizons becomes critical. An essential component of this ability is planning and managing a long, complex chain-of-thought (CoT). We introduce LongCoT, a scalable benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic to isolate and directly measure the long-horizon CoT reasoning capabilities of frontier models. Problems consist of a short input with a verifiable answer; solving them requires navigating a graph of interdependent steps that span tens to hundreds of thousands of reasoning tokens. Each local step is individually tractable for frontier models, so failures reflect long-horizon reasoning limitations. At release, the best models achieve <10% accuracy (GPT 5.2: 9.8%; Gemini 3 Pro: 6.1%) on LongCoT, revealing a substantial gap in current capabilities. Overall, LongCoT provides a rigorous measure of long-horizon reasoning, tracking the ability of frontier models to reason reliably over extended periods.
How LLMs Distort Our Written Language
Mar 18, 2026Large language models (LLMs) are used by over a billion people globally, most often to assist with writing. In this work, we demonstrate that LLMs not only alter the voice and tone of human writing, but also consistently alter the intended meaning. First, we conduct a human user study to understand how people actually interact with LLMs when using them for writing. Our findings reveal that extensive LLM use led to a nearly 70% increase in essays that remained neutral in answering the topic question. Significantly more heavy LLM users reported that the writing was less creative and not in their voice. Next, using a dataset of human-written essays that was collected in 2021 before the widespread release of LLMs, we study how asking an LLM to revise the essay based on the human-written feedback in the dataset induces large changes in the resulting content and meaning. We find that even when LLMs are prompted with expert feedback and asked to only make grammar edits, they still change the text in a way that significantly alters its semantic meaning. We then examine LLM-generated text in the wild, specifically focusing on the 21% of AI-generated scientific peer reviews at a recent top AI conference. We find that LLM-generated reviews place significantly less weight on clarity and significance of the research, and assign scores that, on average, are a full point higher.These findings highlight a misalignment between the perceived benefit of AI use and an implicit, consistent effect on the semantics of human writing, motivating future work on how widespread AI writing will affect our cultural and scientific institutions.
Improving Interactive In-Context Learning from Natural Language Feedback
Feb 17, 2026Adapting one's thought process based on corrective feedback is an essential ability in human learning, particularly in collaborative settings. In contrast, the current large language model training paradigm relies heavily on modeling vast, static corpora. While effective for knowledge acquisition, it overlooks the interactive feedback loops essential for models to adapt dynamically to their context. In this work, we propose a framework that treats this interactive in-context learning ability not as an emergent property, but as a distinct, trainable skill. We introduce a scalable method that transforms single-turn verifiable tasks into multi-turn didactic interactions driven by information asymmetry. We first show that current flagship models struggle to integrate corrective feedback on hard reasoning tasks. We then demonstrate that models trained with our approach dramatically improve the ability to interactively learn from language feedback. More specifically, the multi-turn performance of a smaller model nearly reaches that of a model an order of magnitude larger. We also observe robust out-of-distribution generalization: interactive training on math problems transfers to diverse domains like coding, puzzles and maze navigation. Our qualitative analysis suggests that this improvement is due to an enhanced in-context plasticity. Finally, we show that this paradigm offers a unified path to self-improvement. By training the model to predict the teacher's critiques, effectively modeling the feedback environment, we convert this external signal into an internal capability, allowing the model to self-correct even without a teacher.
Are Language Models Sensitive to Morally Irrelevant Distractors?
Feb 10, 2026With the rapid development and uptake of large language models (LLMs) across high-stakes settings, it is increasingly important to ensure that LLMs behave in ways that align with human values. Existing moral benchmarks prompt LLMs with value statements, moral scenarios, or psychological questionnaires, with the implicit underlying assumption that LLMs report somewhat stable moral preferences. However, moral psychology research has shown that human moral judgements are sensitive to morally irrelevant situational factors, such as smelling cinnamon rolls or the level of ambient noise, thereby challenging moral theories that assume the stability of human moral judgements. Here, we draw inspiration from this "situationist" view of moral psychology to evaluate whether LLMs exhibit similar cognitive moral biases to humans. We curate a novel multimodal dataset of 60 "moral distractors" from existing psychological datasets of emotionally-valenced images and narratives which have no moral relevance to the situation presented. After injecting these distractors into existing moral benchmarks to measure their effects on LLM responses, we find that moral distractors can shift the moral judgements of LLMs by over 30% even in low-ambiguity scenarios, highlighting the need for more contextual moral evaluations and more nuanced cognitive moral modeling of LLMs.
AgenticRed: Optimizing Agentic Systems for Automated Red-teaming
Jan 20, 2026While recent automated red-teaming methods show promise for systematically exposing model vulnerabilities, most existing approaches rely on human-specified workflows. This dependence on manually designed workflows suffers from human biases and makes exploring the broader design space expensive. We introduce AgenticRed, an automated pipeline that leverages LLMs' in-context learning to iteratively design and refine red-teaming systems without human intervention. Rather than optimizing attacker policies within predefined structures, AgenticRed treats red-teaming as a system design problem. Inspired by methods like Meta Agent Search, we develop a novel procedure for evolving agentic systems using evolutionary selection, and apply it to the problem of automatic red-teaming. Red-teaming systems designed by AgenticRed consistently outperform state-of-the-art approaches, achieving 96% attack success rate (ASR) on Llama-2-7B (36% improvement) and 98% on Llama-3-8B on HarmBench. Our approach exhibits strong transferability to proprietary models, achieving 100% ASR on GPT-3.5-Turbo and GPT-4o-mini, and 60% on Claude-Sonnet-3.5 (24% improvement). This work highlights automated system design as a powerful paradigm for AI safety evaluation that can keep pace with rapidly evolving models.
RLVE: Scaling Up Reinforcement Learning for Language Models with Adaptive Verifiable Environments
Nov 10, 2025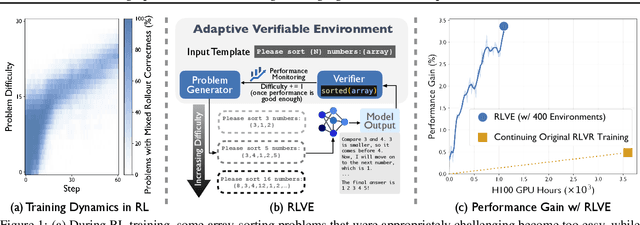

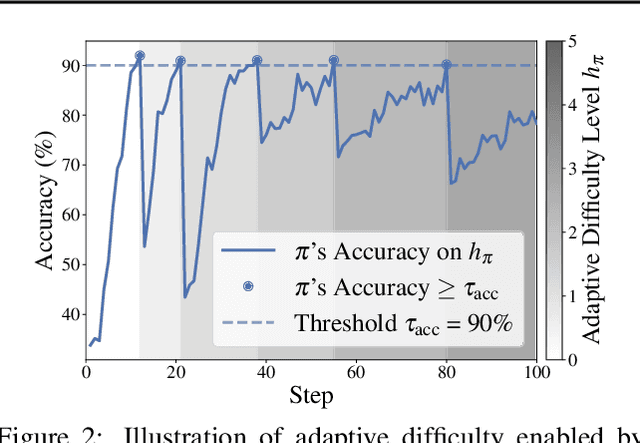
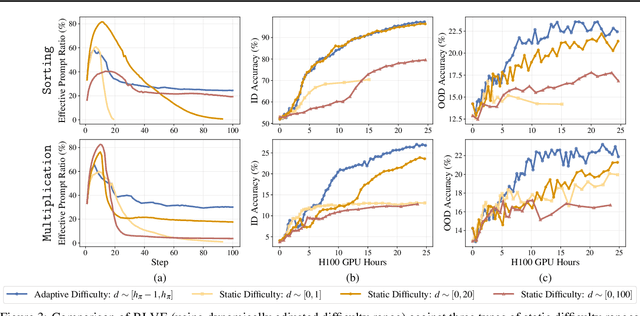
We introduce Reinforcement Learning (RL) with Adaptive Verifiable Environments (RLVE), an approach using verifiable environments that procedurally generate problems and provide algorithmically verifiable rewards, to scale up RL for language models (LMs). RLVE enables each verifiable environment to dynamically adapt its problem difficulty distribution to the policy model's capabilities as training progresses. In contrast, static data distributions often lead to vanishing learning signals when problems are either too easy or too hard for the policy. To implement RLVE, we create RLVE-Gym, a large-scale suite of 400 verifiable environments carefully developed through manual environment engineering. Using RLVE-Gym, we show that environment scaling, i.e., expanding the collection of training environments, consistently improves generalizable reasoning capabilities. RLVE with joint training across all 400 environments in RLVE-Gym yields a 3.37% absolute average improvement across six reasoning benchmarks, starting from one of the strongest 1.5B reasoning LMs. By comparison, continuing this LM's original RL training yields only a 0.49% average absolute gain despite using over 3x more compute. We release our code publicly.
Evaluating & Reducing Deceptive Dialogue From Language Models with Multi-turn RL
Oct 16, 2025Large Language Models (LLMs) interact with millions of people worldwide in applications such as customer support, education and healthcare. However, their ability to produce deceptive outputs, whether intentionally or inadvertently, poses significant safety concerns. The unpredictable nature of LLM behavior, combined with insufficient safeguards against hallucination, misinformation, and user manipulation, makes their misuse a serious, real-world risk. In this paper, we investigate the extent to which LLMs engage in deception within dialogue, and propose the belief misalignment metric to quantify deception. We evaluate deception across four distinct dialogue scenarios, using five established deception detection metrics and our proposed metric. Our findings reveal this novel deception measure correlates more closely with human judgments than any existing metrics we test. Additionally, our benchmarking of eight state-of-the-art models indicates that LLMs naturally exhibit deceptive behavior in approximately 26% of dialogue turns, even when prompted with seemingly benign objectives. When prompted to deceive, LLMs are capable of increasing deceptiveness by as much as 31% relative to baselines. Unexpectedly, models trained with RLHF, the predominant approach for ensuring the safety of widely-deployed LLMs, still exhibit deception at a rate of 43% on average. Given that deception in dialogue is a behavior that develops over an interaction history, its effective evaluation and mitigation necessitates moving beyond single-utterance analyses. We introduce a multi-turn reinforcement learning methodology to fine-tune LLMs to reduce deceptive behaviors, leading to a 77.6% reduction compared to other instruction-tuned models.