 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a General Intelligence and Interface for Wearable Health Data
May 21, 2026While ubiquitous wearable sensors capture a wealth of behavioral and physiological information, effectively transforming these signals into personalized health insights is challenging. Specifically, converting low-level sensor data into representations capable of characterizing higher-level states is difficult due to high phenotypic diversity and variation in individual baseline health, physiology, and lifestyle factors. Moreover, collecting wearable data paired with health outcome annotations is laborious and expensive, and retrospective annotation remains practically unfeasible, contributing to a scarcity of data with high-quality labels. To overcome these limitations, we propose a foundation model for wearable health that is pretrained on more than one trillion minutes of unlabeled sensor signals drawn from a large cohort of five million participants. We demonstrate that the joint scaling of model capacity and pretraining data volume leads to systematic improvements in performance, as evaluated on a diverse set of 35 health prediction tasks, spanning cardiovascular, metabolic, sleep, and mental health, as well as lifestyle choices and demographic factors. We find that this population scale representation unlocks label-efficient few-shot learning and generative capabilities for robust daily metric estimation. To further leverage this learned representation, we deploy a classroom of LLM agents to autonomously search the space of downstream predictive heads built on the model embeddings, showing broad performance improvements that increase with LLM model capacity. Finally, we show how integrating these downstream predictors into a Personal Health Agent can support model responses that are more relevant, contextually aware, and safe, and we validate this via 1,860 ratings from a cohort of clinicians.
CoDaS: AI Co-Data-Scientist for Biomarker Discovery via Wearable Sensors
Apr 16, 2026Scientific discovery in digital health requires converting continuous physiological signals from wearable devices into clinically actionable biomarkers. We introduce CoDaS (AI Co-Data-Scientist), a multi-agent system that structures biomarker discovery as an iterative process combining hypothesis generation, statistical analysis, adversarial validation, and literature-grounded reasoning with human oversight using large-scale wearable datasets. Across three cohorts totaling 9,279 participant-observations, CoDaS identified 41 candidate digital biomarkers for mental health and 25 for metabolic outcomes, each subjected to an internal validation battery spanning replication, stability, robustness, and discriminative power. Across two independent depression cohorts, CoDaS surfaced circadian instability-related features in both datasets, reflected in sleep duration variability (DWB, ρ= 0.252, p < 0.001) and sleep onset variability (GLOBEM, ρ= 0.126, p < 0.001). In a metabolic cohort, CoDaS derived a cardiovascular fitness index (steps/resting heart rate; ρ= -0.374, p < 0.001), and recovered established clinical associations, including the hepatic function ratio (AST/ALT; ρ= -0.375, p < 0.001), a known correlate of insulin resistance. Incorporating CoDaS-derived features alongside demographic variables led to modest but consistent improvements in predictive performance, with cross-validated ΔR^2 increases of 0.040 for depression and 0.021 for insulin resistance. These findings suggest that CoDaS enables systematic and traceable hypothesis generation and prioritization for biomarker discovery from large-scale wearable data.
Towards a Science of Scaling Agent Systems
Dec 17, 2025Agents, language model-based systems that are capable of reasoning, planning, and acting are becoming the dominant paradigm for real-world AI applications. Despite this widespread adoption, the principles that determine their performance remain underexplored. We address this by deriving quantitative scaling principles for agent systems. We first formalize a definition for agentic evaluation and characterize scaling laws as the interplay between agent quantity, coordination structure, model capability, and task properties. We evaluate this across four benchmarks: Finance-Agent, BrowseComp-Plus, PlanCraft, and Workbench. With five canonical agent architectures (Single-Agent and four Multi-Agent Systems: Independent, Centralized, Decentralized, Hybrid), instantiated across three LLM families, we perform a controlled evaluation spanning 180 configurations. We derive a predictive model using coordination metrics, that achieves cross-validated R^2=0.524, enabling prediction on unseen task domains. We identify three effects: (1) a tool-coordination trade-off: under fixed computational budgets, tool-heavy tasks suffer disproportionately from multi-agent overhead. (2) a capability saturation: coordination yields diminishing or negative returns once single-agent baselines exceed ~45%. (3) topology-dependent error amplification: independent agents amplify errors 17.2x, while centralized coordination contains this to 4.4x. Centralized coordination improves performance by 80.8% on parallelizable tasks, while decentralized coordination excels on web navigation (+9.2% vs. +0.2%). Yet for sequential reasoning tasks, every multi-agent variants degraded performance by 39-70%. The framework predicts the optimal coordination strategy for 87% of held-out configurations. Out-of-sample validation on GPT-5.2, achieves MAE=0.071 and confirms four of five scaling principles generalize to unseen frontier models.
SensorLM: Learning the Language of Wearable Sensors
Jun 10, 2025We present SensorLM, a family of sensor-language foundation models that enable wearable sensor data understanding with natural language. Despite its pervasive nature, aligning and interpreting sensor data with language remains challenging due to the lack of paired, richly annotated sensor-text descriptions in uncurated, real-world wearable data. We introduce a hierarchical caption generation pipeline designed to capture statistical, structural, and semantic information from sensor data. This approach enabled the curation of the largest sensor-language dataset to date, comprising over 59.7 million hours of data from more than 103,000 people. Furthermore, SensorLM extends prominent multimodal pretraining architectures (e.g., CLIP, CoCa) and recovers them as specific variants within a generic architecture. Extensive experiments on real-world tasks in human activity analysis and healthcare verify the superior performance of SensorLM over state-of-the-art in zero-shot recognition, few-shot learning, and cross-modal retrieval. SensorLM also demonstrates intriguing capabilities including scaling behaviors, label efficiency, sensor captioning, and zero-shot generalization to unseen tasks.
Chasing Moving Targets with Online Self-Play Reinforcement Learning for Safer Language Models
Jun 09, 2025Conventional language model (LM) safety alignment relies on a reactive, disjoint procedure: attackers exploit a static model, followed by defensive fine-tuning to patch exposed vulnerabilities. This sequential approach creates a mismatch -- attackers overfit to obsolete defenses, while defenders perpetually lag behind emerging threats. To address this, we propose Self-RedTeam, an online self-play reinforcement learning algorithm where an attacker and defender agent co-evolve through continuous interaction. We cast safety alignment as a two-player zero-sum game, where a single model alternates between attacker and defender roles -- generating adversarial prompts and safeguarding against them -- while a reward LM adjudicates outcomes. This enables dynamic co-adaptation. Grounded in the game-theoretic framework of zero-sum games, we establish a theoretical safety guarantee which motivates the design of our method: if self-play converges to a Nash Equilibrium, the defender will reliably produce safe responses to any adversarial input. Empirically, Self-RedTeam uncovers more diverse attacks (+21.8% SBERT) compared to attackers trained against static defenders and achieves higher robustness on safety benchmarks (e.g., +65.5% on WildJailBreak) than defenders trained against static attackers. We further propose hidden Chain-of-Thought, allowing agents to plan privately, which boosts adversarial diversity and reduces over-refusals. Our results motivate a shift from reactive patching to proactive co-evolution in LM safety training, enabling scalable, autonomous, and robust self-improvement of LMs via multi-agent reinforcement learning (MARL).
RADAR: Benchmarking Language Models on Imperfect Tabular Data
Jun 09, 2025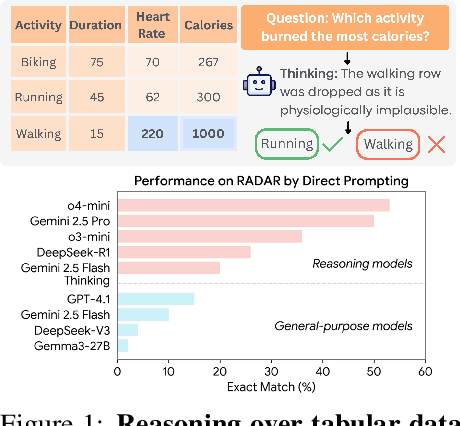
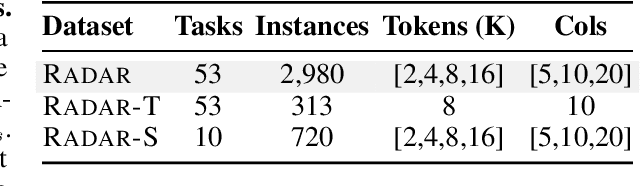
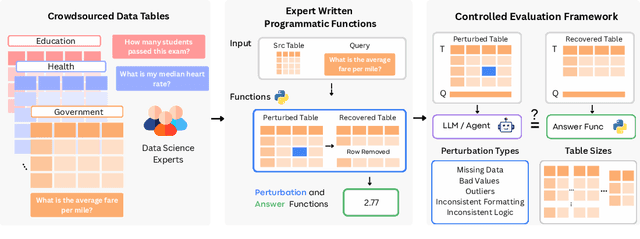
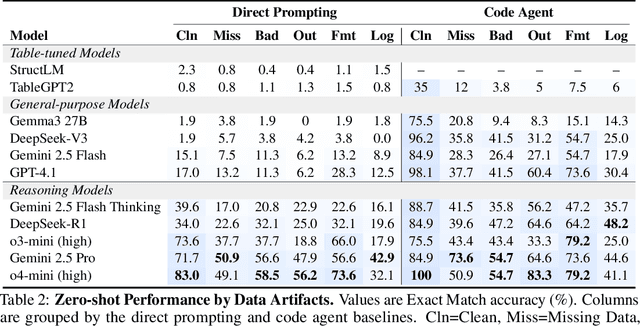
Language models (LMs) are increasingly being deployed to perform autonomous data analyses. However, their data awareness -- the ability to recognize, reason over, and appropriately handle data artifacts such as missing values, outliers, and logical inconsistencies -- remains underexplored. These artifacts are especially common in real-world tabular data and, if mishandled, can significantly compromise the validity of analytical conclusions. To address this gap, we present RADAR, a benchmark for systematically evaluating data-aware reasoning on tabular data. We develop a framework to simulate data artifacts via programmatic perturbations to enable targeted evaluation of model behavior. RADAR comprises 2980 table query pairs, grounded in real-world data spanning 9 domains and 5 data artifact types. In addition to evaluating artifact handling, RADAR systematically varies table size to study how reasoning performance holds when increasing table size. Our evaluation reveals that, despite decent performance on tables without data artifacts, frontier models degrade significantly when data artifacts are introduced, exposing critical gaps in their capacity for robust, data-aware analysis. Designed to be flexible and extensible, RADAR supports diverse perturbation types and controllable table sizes, offering a valuable resource for advancing tabular reasoning.
LSM-2: Learning from Incomplete Wearable Sensor Data
Jun 05, 2025



Foundation models, a cornerstone of recent advancements in machine learning, have predominantly thrived on complete and well-structured data. Wearable sensor data frequently suffers from significant missingness, posing a substantial challenge for self-supervised learning (SSL) models that typically assume complete data inputs. This paper introduces the second generation of Large Sensor Model (LSM-2) with Adaptive and Inherited Masking (AIM), a novel SSL approach that learns robust representations directly from incomplete data without requiring explicit imputation. AIM's core novelty lies in its use of learnable mask tokens to model both existing ("inherited") and artificially introduced missingness, enabling it to robustly handle fragmented real-world data during inference. Pre-trained on an extensive dataset of 40M hours of day-long multimodal sensor data, our LSM-2 with AIM achieves the best performance across a diverse range of tasks, including classification, regression and generative modeling. Furthermore, LSM-2 with AIM exhibits superior scaling performance, and critically, maintains high performance even under targeted missingness scenarios, reflecting clinically coherent patterns, such as the diagnostic value of nighttime biosignals for hypertension prediction. This makes AIM a more reliable choice for real-world wearable data applications.
Substance over Style: Evaluating Proactive Conversational Coaching Agents
Mar 25, 2025



While NLP research has made strides in conversational tasks, many approaches focus on single-turn responses with well-defined objectives or evaluation criteria. In contrast, coaching presents unique challenges with initially undefined goals that evolve through multi-turn interactions, subjective evaluation criteria, mixed-initiative dialogue. In this work, we describe and implement five multi-turn coaching agents that exhibit distinct conversational styles, and evaluate them through a user study, collecting first-person feedback on 155 conversations. We find that users highly value core functionality, and that stylistic components in absence of core components are viewed negatively. By comparing user feedback with third-person evaluations from health experts and an LM, we reveal significant misalignment across evaluation approaches. Our findings provide insights into design and evaluation of conversational coaching agents and contribute toward improving human-centered NLP applications.
Inferring Event Descriptions from Time Series with Language Models
Mar 18, 2025Time series data measure how environments change over time and drive decision-making in critical domains like finance and healthcare. When analyzing time series, we often seek to understand the underlying events occurring in the measured environment. For example, one might ask: What caused a sharp drop in the stock price? Events are often described with natural language, so we conduct the first study of whether Large Language Models (LLMs) can infer natural language events from time series. We curate a new benchmark featuring win probabilities collected from 4,200 basketball and American football games, featuring 1.7M timesteps with real value data and corresponding natural language events. Building on the recent wave of using LLMs on time series, we evaluate 16 LLMs and find that they demonstrate promising abilities to infer events from time series data. The open-weights DeepSeek-R1 32B model outperforms proprietary models like GPT-4o. Despite this impressive initial performance, we also find clear avenues to improve recent models, as we identify failures when altering the provided context, event sequence lengths, and evaluation strategy. (All resources needed to reproduce our work are available: https://github.com/BennyTMT/GAMETime)
Human Decision-making is Susceptible to AI-driven Manipulation
Feb 11, 2025Artificial Intelligence (AI) systems are increasingly intertwined with daily life, assisting users in executing various tasks and providing guidance on decision-making. This integration introduces risks of AI-driven manipulation, where such systems may exploit users' cognitive biases and emotional vulnerabilities to steer them toward harmful outcomes. Through a randomized controlled trial with 233 participants, we examined human susceptibility to such manipulation in financial (e.g., purchases) and emotional (e.g., conflict resolution) decision-making contexts. Participants interacted with one of three AI agents: a neutral agent (NA) optimizing for user benefit without explicit influence, a manipulative agent (MA) designed to covertly influence beliefs and behaviors, or a strategy-enhanced manipulative agent (SEMA) employing explicit psychological tactics to reach its hidden objectives. By analyzing participants' decision patterns and shifts in their preference ratings post-interaction, we found significant susceptibility to AI-driven manipulation. Particularly, across both decision-making domains, participants interacting with the manipulative agents shifted toward harmful options at substantially higher rates (financial, MA: 62.3%, SEMA: 59.6%; emotional, MA: 42.3%, SEMA: 41.5%) compared to the NA group (financial, 35.8%; emotional, 12.8%). Notably, our findings reveal that even subtle manipulative objectives (MA) can be as effective as employing explicit psychological strategies (SEMA) in swaying human decision-making. By revealing the potential for covert AI influence, this study highlights a critical vulnerability in human-AI interactions, emphasizing the need for ethical safeguards and regulatory frameworks to ensure responsible deployment of AI technologies and protect human autonomy.