 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInferring Event Descriptions from Time Series with Language Models
Mar 18, 2025Time series data measure how environments change over time and drive decision-making in critical domains like finance and healthcare. When analyzing time series, we often seek to understand the underlying events occurring in the measured environment. For example, one might ask: What caused a sharp drop in the stock price? Events are often described with natural language, so we conduct the first study of whether Large Language Models (LLMs) can infer natural language events from time series. We curate a new benchmark featuring win probabilities collected from 4,200 basketball and American football games, featuring 1.7M timesteps with real value data and corresponding natural language events. Building on the recent wave of using LLMs on time series, we evaluate 16 LLMs and find that they demonstrate promising abilities to infer events from time series data. The open-weights DeepSeek-R1 32B model outperforms proprietary models like GPT-4o. Despite this impressive initial performance, we also find clear avenues to improve recent models, as we identify failures when altering the provided context, event sequence lengths, and evaluation strategy. (All resources needed to reproduce our work are available: https://github.com/BennyTMT/GAMETime)
Are Language Models Actually Useful for Time Series Forecasting?
Jun 22, 2024Large language models (LLMs) are being applied to time series tasks, particularly time series forecasting. However, are language models actually useful for time series? After a series of ablation studies on three recent and popular LLM-based time series forecasting methods, we find that removing the LLM component or replacing it with a basic attention layer does not degrade the forecasting results -- in most cases the results even improved. We also find that despite their significant computational cost, pretrained LLMs do no better than models trained from scratch, do not represent the sequential dependencies in time series, and do not assist in few-shot settings. Additionally, we explore time series encoders and reveal that patching and attention structures perform similarly to state-of-the-art LLM-based forecasters.
Language Models Still Struggle to Zero-shot Reason about Time Series
Apr 17, 2024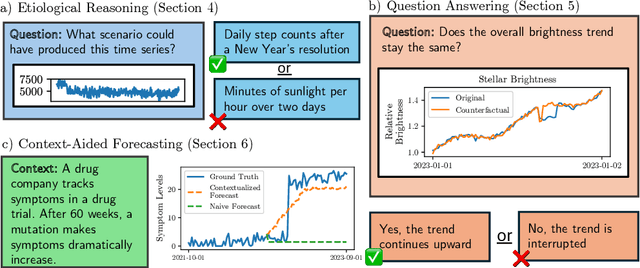
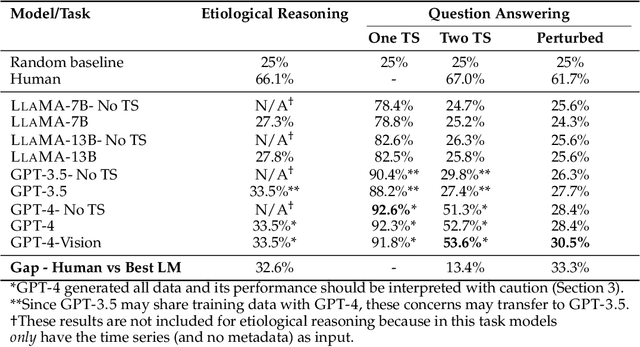

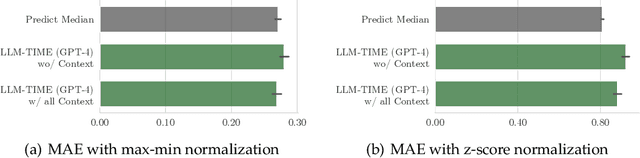
Time series are critical for decision-making in fields like finance and healthcare. Their importance has driven a recent influx of works passing time series into language models, leading to non-trivial forecasting on some datasets. But it remains unknown whether non-trivial forecasting implies that language models can reason about time series. To address this gap, we generate a first-of-its-kind evaluation framework for time series reasoning, including formal tasks and a corresponding dataset of multi-scale time series paired with text captions across ten domains. Using these data, we probe whether language models achieve three forms of reasoning: (1) Etiological Reasoning - given an input time series, can the language model identify the scenario that most likely created it? (2) Question Answering - can a language model answer factual questions about time series? (3) Context-Aided Forecasting - does highly relevant textual context improve a language model's time series forecasts? We find that otherwise highly-capable language models demonstrate surprisingly limited time series reasoning: they score marginally above random on etiological and question answering tasks (up to 30 percentage points worse than humans) and show modest success in using context to improve forecasting. These weakness showcase that time series reasoning is an impactful, yet deeply underdeveloped direction for language model research. We also make our datasets and code public at to support further research in this direction at https://github.com/behavioral-data/TSandLanguage
A Somewhat Robust Image Watermark against Diffusion-based Editing Models
Dec 07, 2023



Recently, diffusion models (DMs) have become the state-of-the-art method for image synthesis. Editing models based on DMs, known for their high fidelity and precision, have inadvertently introduced new challenges related to image copyright infringement and malicious editing. Our work is the first to formalize and address this issue. After assessing and attempting to enhance traditional image watermarking techniques, we recognize their limitations in this emerging context. In response, we develop a novel technique, RIW (Robust Invisible Watermarking), to embed invisible watermarks leveraging adversarial example techniques. Our technique ensures a high extraction accuracy of $96\%$ for the invisible watermark after editing, compared to the $0\%$ offered by conventional methods. We provide access to our code at https://github.com/BennyTMT/RIW.