 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBEDTime: A Unified Benchmark for Automatically Describing Time Series
Sep 05, 2025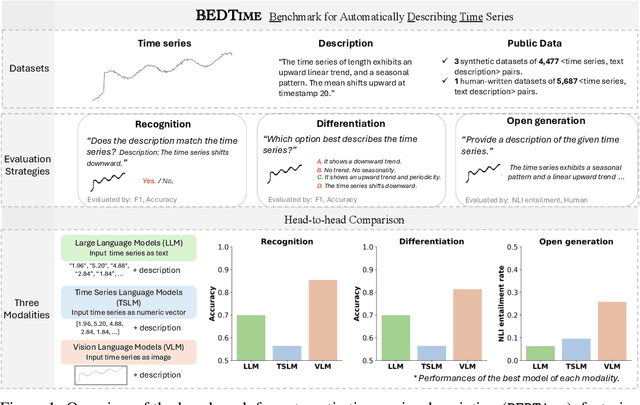

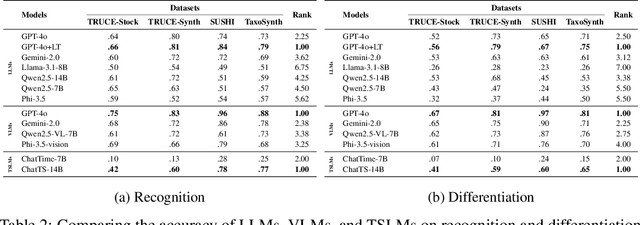
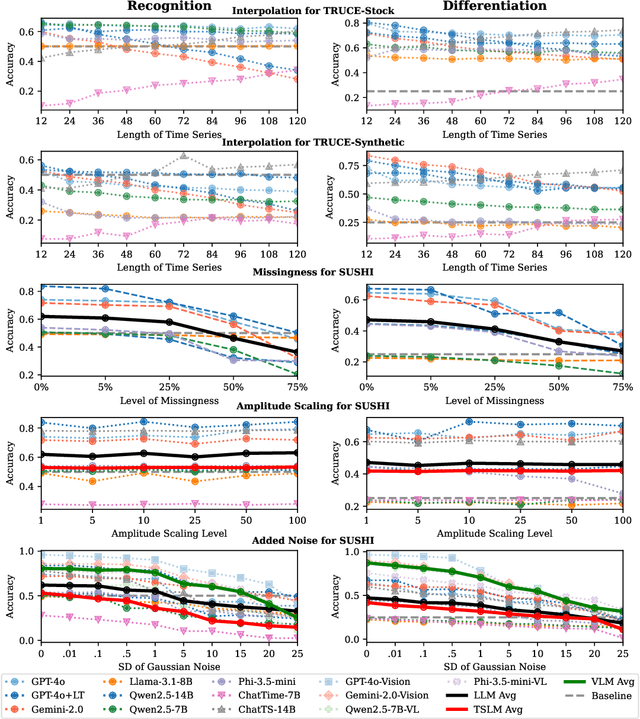
Many recent studies have proposed general-purpose foundation models designed for a variety of time series analysis tasks. While several established datasets already exist for evaluating these models, previous works frequently introduce their models in conjunction with new datasets, limiting opportunities for direct, independent comparisons and obscuring insights into the relative strengths of different methods. Additionally, prior evaluations often cover numerous tasks simultaneously, assessing a broad range of model abilities without clearly pinpointing which capabilities contribute to overall performance. To address these gaps, we formalize and evaluate 3 tasks that test a model's ability to describe time series using generic natural language: (1) recognition (True/False question-answering), (2) differentiation (multiple choice question-answering), and (3) generation (open-ended natural language description). We then unify 4 recent datasets to enable head-to-head model comparisons on each task. Experimentally, in evaluating 13 state-of-the-art language, vision--language, and time series--language models, we find that (1) popular language-only methods largely underperform, indicating a need for time series-specific architectures, (2) VLMs are quite successful, as expected, identifying the value of vision models for these tasks and (3) pretrained multimodal time series--language models successfully outperform LLMs, but still have significant room for improvement. We also find that all approaches exhibit clear fragility in a range of robustness tests. Overall, our benchmark provides a standardized evaluation on a task necessary for time series reasoning systems.
Inferring Event Descriptions from Time Series with Language Models
Mar 18, 2025Time series data measure how environments change over time and drive decision-making in critical domains like finance and healthcare. When analyzing time series, we often seek to understand the underlying events occurring in the measured environment. For example, one might ask: What caused a sharp drop in the stock price? Events are often described with natural language, so we conduct the first study of whether Large Language Models (LLMs) can infer natural language events from time series. We curate a new benchmark featuring win probabilities collected from 4,200 basketball and American football games, featuring 1.7M timesteps with real value data and corresponding natural language events. Building on the recent wave of using LLMs on time series, we evaluate 16 LLMs and find that they demonstrate promising abilities to infer events from time series data. The open-weights DeepSeek-R1 32B model outperforms proprietary models like GPT-4o. Despite this impressive initial performance, we also find clear avenues to improve recent models, as we identify failures when altering the provided context, event sequence lengths, and evaluation strategy. (All resources needed to reproduce our work are available: https://github.com/BennyTMT/GAMETime)
How Can Time Series Analysis Benefit From Multiple Modalities? A Survey and Outlook
Mar 14, 2025Time series analysis (TSA) is a longstanding research topic in the data mining community and has wide real-world significance. Compared to "richer" modalities such as language and vision, which have recently experienced explosive development and are densely connected, the time-series modality remains relatively underexplored and isolated. We notice that many recent TSA works have formed a new research field, i.e., Multiple Modalities for TSA (MM4TSA). In general, these MM4TSA works follow a common motivation: how TSA can benefit from multiple modalities. This survey is the first to offer a comprehensive review and a detailed outlook for this emerging field. Specifically, we systematically discuss three benefits: (1) reusing foundation models of other modalities for efficient TSA, (2) multimodal extension for enhanced TSA, and (3) cross-modality interaction for advanced TSA. We further group the works by the introduced modality type, including text, images, audio, tables, and others, within each perspective. Finally, we identify the gaps with future opportunities, including the reused modalities selections, heterogeneous modality combinations, and unseen tasks generalizations, corresponding to the three benefits. We release an up-to-date GitHub repository that includes key papers and resources.
Understanding the Limits of Lifelong Knowledge Editing in LLMs
Mar 07, 2025Keeping large language models factually up-to-date is crucial for deployment, yet costly retraining remains a challenge. Knowledge editing offers a promising alternative, but methods are only tested on small-scale or synthetic edit benchmarks. In this work, we aim to bridge research into lifelong knowledge editing to real-world edits at practically relevant scale. We first introduce WikiBigEdit; a large-scale benchmark of real-world Wikidata edits, built to automatically extend lifelong for future-proof benchmarking. In its first instance, it includes over 500K question-answer pairs for knowledge editing alongside a comprehensive evaluation pipeline. Finally, we use WikiBigEdit to study existing knowledge editing techniques' ability to incorporate large volumes of real-world facts and contrast their capabilities to generic modification techniques such as retrieval augmentation and continual finetuning to acquire a complete picture of the practical extent of current lifelong knowledge editing.
SDoH-GPT: Using Large Language Models to Extract Social Determinants of Health (SDoH)
Jul 24, 2024



Extracting social determinants of health (SDoH) from unstructured medical notes depends heavily on labor-intensive annotations, which are typically task-specific, hampering reusability and limiting sharing. In this study we introduced SDoH-GPT, a simple and effective few-shot Large Language Model (LLM) method leveraging contrastive examples and concise instructions to extract SDoH without relying on extensive medical annotations or costly human intervention. It achieved tenfold and twentyfold reductions in time and cost respectively, and superior consistency with human annotators measured by Cohen's kappa of up to 0.92. The innovative combination of SDoH-GPT and XGBoost leverages the strengths of both, ensuring high accuracy and computational efficiency while consistently maintaining 0.90+ AUROC scores. Testing across three distinct datasets has confirmed its robustness and accuracy. This study highlights the potential of leveraging LLMs to revolutionize medical note classification, demonstrating their capability to achieve highly accurate classifications with significantly reduced time and cost.
Language Models Still Struggle to Zero-shot Reason about Time Series
Apr 17, 2024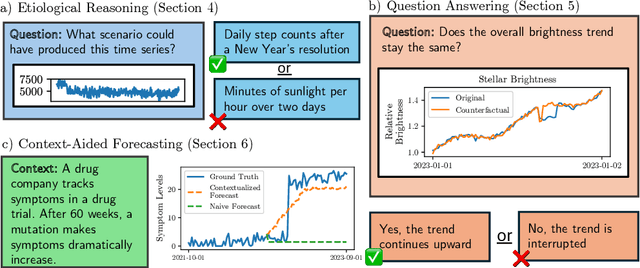
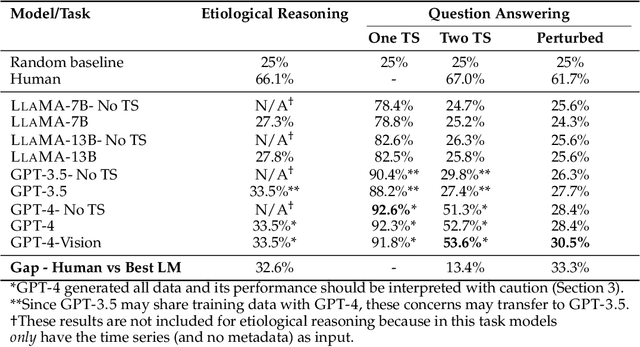

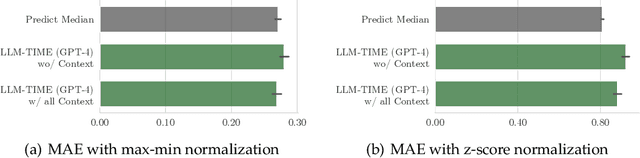
Time series are critical for decision-making in fields like finance and healthcare. Their importance has driven a recent influx of works passing time series into language models, leading to non-trivial forecasting on some datasets. But it remains unknown whether non-trivial forecasting implies that language models can reason about time series. To address this gap, we generate a first-of-its-kind evaluation framework for time series reasoning, including formal tasks and a corresponding dataset of multi-scale time series paired with text captions across ten domains. Using these data, we probe whether language models achieve three forms of reasoning: (1) Etiological Reasoning - given an input time series, can the language model identify the scenario that most likely created it? (2) Question Answering - can a language model answer factual questions about time series? (3) Context-Aided Forecasting - does highly relevant textual context improve a language model's time series forecasts? We find that otherwise highly-capable language models demonstrate surprisingly limited time series reasoning: they score marginally above random on etiological and question answering tasks (up to 30 percentage points worse than humans) and show modest success in using context to improve forecasting. These weakness showcase that time series reasoning is an impactful, yet deeply underdeveloped direction for language model research. We also make our datasets and code public at to support further research in this direction at https://github.com/behavioral-data/TSandLanguage
Recent Advances, Applications, and Open Challenges in Machine Learning for Health: Reflections from Research Roundtables at ML4H 2023 Symposium
Mar 03, 2024The third ML4H symposium was held in person on December 10, 2023, in New Orleans, Louisiana, USA. The symposium included research roundtable sessions to foster discussions between participants and senior researchers on timely and relevant topics for the \ac{ML4H} community. Encouraged by the successful virtual roundtables in the previous year, we organized eleven in-person roundtables and four virtual roundtables at ML4H 2022. The organization of the research roundtables at the conference involved 17 Senior Chairs and 19 Junior Chairs across 11 tables. Each roundtable session included invited senior chairs (with substantial experience in the field), junior chairs (responsible for facilitating the discussion), and attendees from diverse backgrounds with interest in the session's topic. Herein we detail the organization process and compile takeaways from these roundtable discussions, including recent advances, applications, and open challenges for each topic. We conclude with a summary and lessons learned across all roundtables. This document serves as a comprehensive review paper, summarizing the recent advancements in machine learning for healthcare as contributed by foremost researchers in the field.