 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeeking Universal Shot Language Understanding Solutions
Mar 19, 2026Shot language understanding (SLU) is crucial for cinematic analysis but remains challenging due to its diverse cinematographic dimensions and subjective expert judgment. While vision-language models (VLMs) have shown strong ability in general visual understanding, recent studies reveal judgment discrepancies between VLMs and film experts on SLU tasks. To address this gap, we introduce SLU-SUITE, a comprehensive training and evaluation suite containing 490K human-annotated QA pairs across 33 tasks spanning six film-grounded dimensions. Using SLU-SUITE, we originally observe two insights into VLM-based SLU from: the model side, which diagnoses key bottlenecks of modules; the data side, which quantifies cross-dimensional influences among tasks. These findings motivate our universal SLU solutions from two complementary paradigms: UniShot, a balanced one-for-all generalist trained via dynamic-balanced data mixing, and AgentShots, a prompt-routed expert cluster that maximizes peak dimension performance. Extensive experiments show that our models outperform task-specific ensembles on in-domain tasks and surpass leading commercial VLMs by 22% on out-of-domain tasks.
In-context Pre-trained Time-Series Foundation Models adapt to Unseen Tasks
Feb 23, 2026Time-series foundation models (TSFMs) have demonstrated strong generalization capabilities across diverse datasets and tasks. However, existing foundation models are typically pre-trained to enhance performance on specific tasks and often struggle to generalize to unseen tasks without fine-tuning. To address this limitation, we propose augmenting TSFMs with In-Context Learning (ICL) capabilities, enabling them to perform test-time inference by dynamically adapting to input-output relationships provided within the context. Our framework, In-Context Time-series Pre-training (ICTP), restructures the original pre-training data to equip the backbone TSFM with ICL capabilities, enabling adaptation to unseen tasks. Experiments demonstrate that ICT improves the performance of state-of-the-art TSFMs by approximately 11.4% on unseen tasks without requiring fine-tuning.
FutureX-Pro: Extending Future Prediction to High-Value Vertical Domains
Jan 18, 2026Building upon FutureX, which established a live benchmark for general-purpose future prediction, this report introduces FutureX-Pro, including FutureX-Finance, FutureX-Retail, FutureX-PublicHealth, FutureX-NaturalDisaster, and FutureX-Search. These together form a specialized framework extending agentic future prediction to high-value vertical domains. While generalist agents demonstrate proficiency in open-domain search, their reliability in capital-intensive and safety-critical sectors remains under-explored. FutureX-Pro targets four economically and socially pivotal verticals: Finance, Retail, Public Health, and Natural Disaster. We benchmark agentic Large Language Models (LLMs) on entry-level yet foundational prediction tasks -- ranging from forecasting market indicators and supply chain demands to tracking epidemic trends and natural disasters. By adapting the contamination-free, live-evaluation pipeline of FutureX, we assess whether current State-of-the-Art (SOTA) agentic LLMs possess the domain grounding necessary for industrial deployment. Our findings reveal the performance gap between generalist reasoning and the precision required for high-value vertical applications.
Modular Deep-Learning-Based Early Warning System for Deadly Heatwave Prediction
Dec 09, 2025Severe heatwaves in urban areas significantly threaten public health, calling for establishing early warning strategies. Despite predicting occurrence of heatwaves and attributing historical mortality, predicting an incoming deadly heatwave remains a challenge due to the difficulty in defining and estimating heat-related mortality. Furthermore, establishing an early warning system imposes additional requirements, including data availability, spatial and temporal robustness, and decision costs. To address these challenges, we propose DeepTherm, a modular early warning system for deadly heatwave prediction without requiring heat-related mortality history. By highlighting the flexibility of deep learning, DeepTherm employs a dual-prediction pipeline, disentangling baseline mortality in the absence of heatwaves and other irregular events from all-cause mortality. We evaluated DeepTherm on real-world data across Spain. Results demonstrate consistent, robust, and accurate performance across diverse regions, time periods, and population groups while allowing trade-off between missed alarms and false alarms.
TimeRecipe: A Time-Series Forecasting Recipe via Benchmarking Module Level Effectiveness
Jun 06, 2025Time-series forecasting is an essential task with wide real-world applications across domains. While recent advances in deep learning have enabled time-series forecasting models with accurate predictions, there remains considerable debate over which architectures and design components, such as series decomposition or normalization, are most effective under varying conditions. Existing benchmarks primarily evaluate models at a high level, offering limited insight into why certain designs work better. To mitigate this gap, we propose TimeRecipe, a unified benchmarking framework that systematically evaluates time-series forecasting methods at the module level. TimeRecipe conducts over 10,000 experiments to assess the effectiveness of individual components across a diverse range of datasets, forecasting horizons, and task settings. Our results reveal that exhaustive exploration of the design space can yield models that outperform existing state-of-the-art methods and uncover meaningful intuitions linking specific design choices to forecasting scenarios. Furthermore, we release a practical toolkit within TimeRecipe that recommends suitable model architectures based on these empirical insights. The benchmark is available at: https://github.com/AdityaLab/TimeRecipe.
How Can Time Series Analysis Benefit From Multiple Modalities? A Survey and Outlook
Mar 14, 2025Time series analysis (TSA) is a longstanding research topic in the data mining community and has wide real-world significance. Compared to "richer" modalities such as language and vision, which have recently experienced explosive development and are densely connected, the time-series modality remains relatively underexplored and isolated. We notice that many recent TSA works have formed a new research field, i.e., Multiple Modalities for TSA (MM4TSA). In general, these MM4TSA works follow a common motivation: how TSA can benefit from multiple modalities. This survey is the first to offer a comprehensive review and a detailed outlook for this emerging field. Specifically, we systematically discuss three benefits: (1) reusing foundation models of other modalities for efficient TSA, (2) multimodal extension for enhanced TSA, and (3) cross-modality interaction for advanced TSA. We further group the works by the introduced modality type, including text, images, audio, tables, and others, within each perspective. Finally, we identify the gaps with future opportunities, including the reused modalities selections, heterogeneous modality combinations, and unseen tasks generalizations, corresponding to the three benefits. We release an up-to-date GitHub repository that includes key papers and resources.
A Picture is Worth A Thousand Numbers: Enabling LLMs Reason about Time Series via Visualization
Nov 09, 2024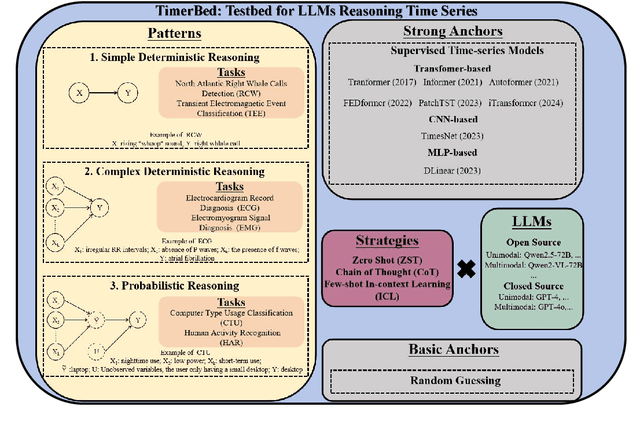
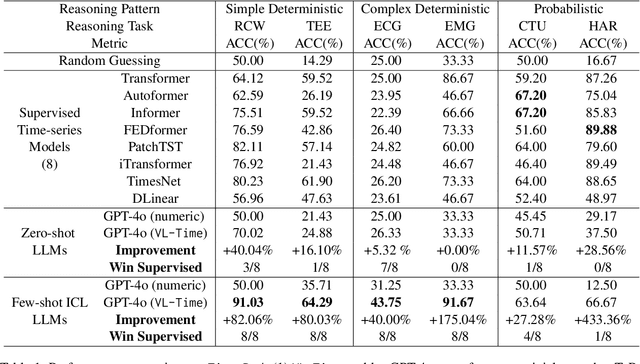
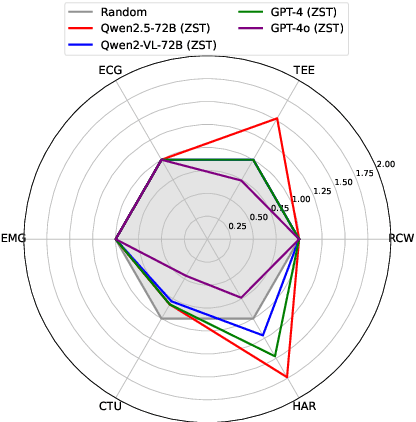

Large language models (LLMs), with demonstrated reasoning abilities across multiple domains, are largely underexplored for time-series reasoning (TsR), which is ubiquitous in the real world. In this work, we propose TimerBed, the first comprehensive testbed for evaluating LLMs' TsR performance. Specifically, TimerBed includes stratified reasoning patterns with real-world tasks, comprehensive combinations of LLMs and reasoning strategies, and various supervised models as comparison anchors. We perform extensive experiments with TimerBed, test multiple current beliefs, and verify the initial failures of LLMs in TsR, evidenced by the ineffectiveness of zero shot (ZST) and performance degradation of few shot in-context learning (ICL). Further, we identify one possible root cause: the numerical modeling of data. To address this, we propose a prompt-based solution VL-Time, using visualization-modeled data and language-guided reasoning. Experimental results demonstrate that Vl-Time enables multimodal LLMs to be non-trivial ZST and powerful ICL reasoners for time series, achieving about 140% average performance improvement and 99% average token costs reduction.
Large Scale Hierarchical Industrial Demand Time-Series Forecasting incorporating Sparsity
Jul 02, 2024Hierarchical time-series forecasting (HTSF) is an important problem for many real-world business applications where the goal is to simultaneously forecast multiple time-series that are related to each other via a hierarchical relation. Recent works, however, do not address two important challenges that are typically observed in many demand forecasting applications at large companies. First, many time-series at lower levels of the hierarchy have high sparsity i.e., they have a significant number of zeros. Most HTSF methods do not address this varying sparsity across the hierarchy. Further, they do not scale well to the large size of the real-world hierarchy typically unseen in benchmarks used in literature. We resolve both these challenges by proposing HAILS, a novel probabilistic hierarchical model that enables accurate and calibrated probabilistic forecasts across the hierarchy by adaptively modeling sparse and dense time-series with different distributional assumptions and reconciling them to adhere to hierarchical constraints. We show the scalability and effectiveness of our methods by evaluating them against real-world demand forecasting datasets. We deploy HAILS at a large chemical manufacturing company for a product demand forecasting application with over ten thousand products and observe a significant 8.5\% improvement in forecast accuracy and 23% better improvement for sparse time-series. The enhanced accuracy and scalability make HAILS a valuable tool for improved business planning and customer experience.
TSI-Bench: Benchmarking Time Series Imputation
Jun 18, 2024Effective imputation is a crucial preprocessing step for time series analysis. Despite the development of numerous deep learning algorithms for time series imputation, the community lacks standardized and comprehensive benchmark platforms to effectively evaluate imputation performance across different settings. Moreover, although many deep learning forecasting algorithms have demonstrated excellent performance, whether their modeling achievements can be transferred to time series imputation tasks remains unexplored. To bridge these gaps, we develop TSI-Bench, the first (to our knowledge) comprehensive benchmark suite for time series imputation utilizing deep learning techniques. The TSI-Bench pipeline standardizes experimental settings to enable fair evaluation of imputation algorithms and identification of meaningful insights into the influence of domain-appropriate missingness ratios and patterns on model performance. Furthermore, TSI-Bench innovatively provides a systematic paradigm to tailor time series forecasting algorithms for imputation purposes. Our extensive study across 34,804 experiments, 28 algorithms, and 8 datasets with diverse missingness scenarios demonstrates TSI-Bench's effectiveness in diverse downstream tasks and potential to unlock future directions in time series imputation research and analysis. The source code and experiment logs are available at https://github.com/WenjieDu/AwesomeImputation.
Time-Series Forecasting for Out-of-Distribution Generalization Using Invariant Learning
Jun 13, 2024Time-series forecasting (TSF) finds broad applications in real-world scenarios. Due to the dynamic nature of time-series data, it is crucial to equip TSF models with out-of-distribution (OOD) generalization abilities, as historical training data and future test data can have different distributions. In this paper, we aim to alleviate the inherent OOD problem in TSF via invariant learning. We identify fundamental challenges of invariant learning for TSF. First, the target variables in TSF may not be sufficiently determined by the input due to unobserved core variables in TSF, breaking the conventional assumption of invariant learning. Second, time-series datasets lack adequate environment labels, while existing environmental inference methods are not suitable for TSF. To address these challenges, we propose FOIL, a model-agnostic framework that enables timeseries Forecasting for Out-of-distribution generalization via Invariant Learning. FOIL employs a novel surrogate loss to mitigate the impact of unobserved variables. Further, FOIL implements a joint optimization by alternately inferring environments effectively with a multi-head network while preserving the temporal adjacency structure, and learning invariant representations across inferred environments for OOD generalized TSF. We demonstrate that the proposed FOIL significantly improves the performance of various TSF models, achieving gains of up to 85%.