 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Control Architecture for Training-Free Memory Use
Apr 20, 2026Prompt-injected memory can improve reasoning without updating model weights, but it also creates a control problem: retrieved content helps only when it is applied in the right state. We study this problem in a strict training-free setting and formulate it as applicability control: when to trigger a memory-assisted second pass, when to trust it, and how to maintain the memory bank over time. Our method combines uncertainty-based routing, confidence-based selective acceptance, bank selection across rule and exemplar memory, and evidence-based governance of the memory bank over time. Under a locked training-free protocol with compute-matched controls, it improves two core arithmetic benchmarks by +7.0 points on SVAMP and +7.67 points on ASDiv over baseline. The same architecture also transfers to QA and agent benchmarks with smaller positive effects and shows the same positive direction on a second checkpoint for the main arithmetic tasks. On arithmetic, the main empirical pattern is that the control architecture, rather than raw memory exposure, drives the improvements on SVAMP and ASDiv. Mechanistically, confidence separates helpful from harmful rule-bank interventions, and under fixed retrieval the repair-versus-corrupt difference localizes to rows whose retrieved set actually contains the edited entries.
State Transfer Reveals Reuse in Controlled Routing
Apr 20, 2026Prompt-based interventions can change model behavior, but trained success alone does not identify where the behaviorally relevant state is represented. We study this question in controlled routing tasks using interfaces chosen on support data, held-out query evaluation, and matched necessity, sufficiency, and wrong-interface controls. On GPT-2 triop, an early interface supports exact transfer under these tests. On GPT-2 add/sub, zero-retrain compiled transfer at the fixed interface recovers most of donor routing accuracy, while trainable prompt slots can relearn the same behavior at several other positions only after additional support examples and optimization. These results distinguish fixed-interface reuse from prompt relocation in a setting where the two can be tested directly. Qwen routing provides a cross-architecture consistency check for the same matched-interface pattern at the operator token, although donor-specific identity on the local V-path remains unresolved. Generation and reasoning branches are used to map scope: they show broader transport or weaker controller identifiability once control depends on longer trajectories or harder selection. In controlled routing, fixed-interface transfer is therefore stronger evidence of reuse than trained prompt success alone.
Taming Sampling Perturbations with Variance Expansion Loss for Latent Diffusion Models
Mar 22, 2026Latent diffusion models have emerged as the dominant framework for high-fidelity and efficient image generation, owing to their ability to learn diffusion processes in compact latent spaces. However, while previous research has focused primarily on reconstruction accuracy and semantic alignment of the latent space, we observe that another critical factor, robustness to sampling perturbations, also plays a crucial role in determining generation quality. Through empirical and theoretical analyses, we show that the commonly used $β$-VAE-based tokenizers in latent diffusion models, tend to produce overly compact latent manifolds that are highly sensitive to stochastic perturbations during diffusion sampling, leading to visual degradation. To address this issue, we propose a simple yet effective solution that constructs a latent space robust to sampling perturbations while maintaining strong reconstruction fidelity. This is achieved by introducing a Variance Expansion loss that counteracts variance collapse and leverages the adversarial interplay between reconstruction and variance expansion to achieve an adaptive balance that preserves reconstruction accuracy while improving robustness to stochastic sampling. Extensive experiments demonstrate that our approach consistently enhances generation quality across different latent diffusion architectures, confirming that robustness in latent space is a key missing ingredient for stable and faithful diffusion sampling.
Improving Channel Estimation via Multimodal Diffusion Models with Flow Matching
Mar 13, 2026Deep generative models offer a powerful alternative to conventional channel estimation by learning complex channel distributions. By integrating the rich environmental information available in modern sensing-aided networks, this paper proposes MultiCE-Flow, a multimodal channel estimation framework based on flow matching and diffusion transformer (DiT). We design a specialized multimodal perception module that fuses LiDAR, camera, and location data into a semantic condition, while treating sparse pilots as a structural condition. These conditions guide a DiT backbone to reconstruct high-fidelity channels. Unlike standard diffusion models, we employ flow matching to learn a linear trajectory from noise to data, enabling efficient one-step sampling. By leveraging environmental semantics, our method mitigates the ill-posed nature of estimation with sparse pilots. Extensive experiments demonstrate that MultiCE-Flow consistently outperforms traditional baselines and existing generative models. Notably, it exhibits superior robustness to out-of-distribution scenarios and varying pilot densities, making it suitable for environment-aware communication systems.
ATD: Improved Transformer with Adaptive Token Dictionary for Image Restoration
Mar 03, 2026Recently, Transformers have gained significant popularity in image restoration tasks such as image super-resolution and denoising, owing to their superior performance. However, balancing performance and computational burden remains a long-standing problem for transformer-based architectures. Due to the quadratic complexity of self-attention, existing methods often restrict attention to local windows, resulting in limited receptive field and suboptimal performance. To address this issue, we propose Adaptive Token Dictionary (ATD), a novel transformer-based architecture for image restoration that enables global dependency modeling with linear complexity relative to image size. The ATD model incorporates a learnable token dictionary, which summarizes external image priors (i.e., typical image structures) during the training process. To utilize this information, we introduce a token dictionary cross-attention (TDCA) mechanism that enhances the input features via interaction with the learned dictionary. Furthermore, we exploit the category information embedded in the TDCA attention maps to group input features into multiple categories, each representing a cluster of similar features across the image and serving as an attention group. We also integrate the learned category information into the feed-forward network to further improve feature fusion. ATD and its lightweight version ATD-light, achieve state-of-the-art performance on multiple image super-resolution benchmarks. Moreover, we develop ATD-U, a multi-scale variant of ATD, to address other image restoration tasks, including image denoising and JPEG compression artifacts removal. Extensive experiments demonstrate the superiority of out proposed models, both quantitatively and qualitatively.
Guiding a Diffusion Transformer with the Internal Dynamics of Itself
Dec 30, 2025The diffusion model presents a powerful ability to capture the entire (conditional) data distribution. However, due to the lack of sufficient training and data to learn to cover low-probability areas, the model will be penalized for failing to generate high-quality images corresponding to these areas. To achieve better generation quality, guidance strategies such as classifier free guidance (CFG) can guide the samples to the high-probability areas during the sampling stage. However, the standard CFG often leads to over-simplified or distorted samples. On the other hand, the alternative line of guiding diffusion model with its bad version is limited by carefully designed degradation strategies, extra training and additional sampling steps. In this paper, we proposed a simple yet effective strategy Internal Guidance (IG), which introduces an auxiliary supervision on the intermediate layer during training process and extrapolates the intermediate and deep layer's outputs to obtain generative results during sampling process. This simple strategy yields significant improvements in both training efficiency and generation quality on various baselines. On ImageNet 256x256, SiT-XL/2+IG achieves FID=5.31 and FID=1.75 at 80 and 800 epochs. More impressively, LightningDiT-XL/1+IG achieves FID=1.34 which achieves a large margin between all of these methods. Combined with CFG, LightningDiT-XL/1+IG achieves the current state-of-the-art FID of 1.19.
Improved Bounds for Private and Robust Alignment
Dec 29, 2025In this paper, we study the private and robust alignment of language models from a theoretical perspective by establishing upper bounds on the suboptimality gap in both offline and online settings. We consider preference labels subject to privacy constraints and/or adversarial corruption, and analyze two distinct interplays between them: privacy-first and corruption-first. For the privacy-only setting, we show that log loss with an MLE-style algorithm achieves near-optimal rates, in contrast to conventional wisdom. For the joint privacy-and-corruption setting, we first demonstrate that existing offline algorithms in fact provide stronger guarantees -- simultaneously in terms of corruption level and privacy parameters -- than previously known, which further yields improved bounds in the corruption-only regime. In addition, we also present the first set of results for private and robust online alignment. Our results are enabled by new uniform convergence guarantees for log loss and square loss under privacy and corruption, which we believe have broad applicability across learning theory and statistics.
Reducing Pilots in Channel Estimation With Predictive Foundation Models
Dec 17, 2025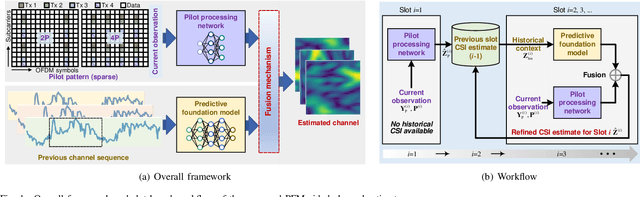
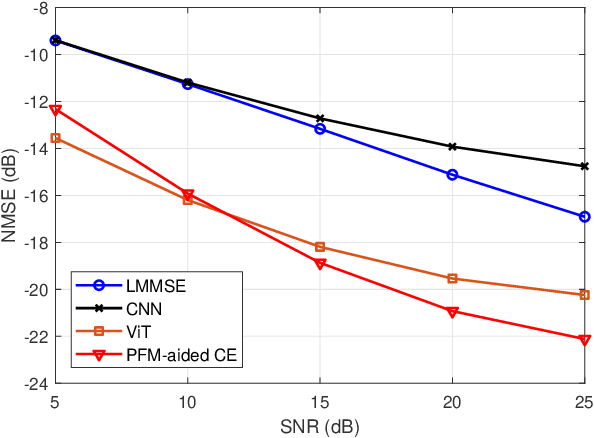
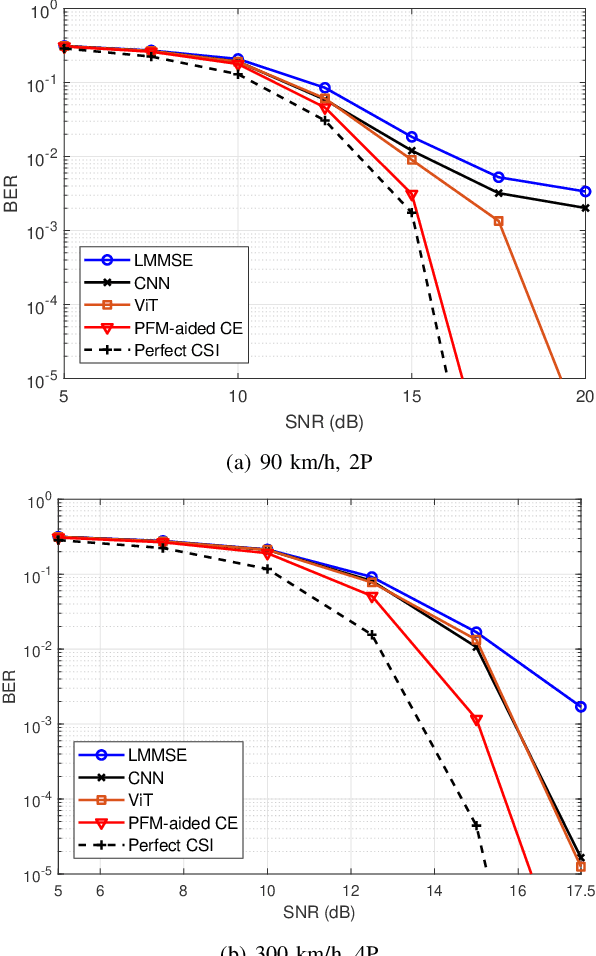
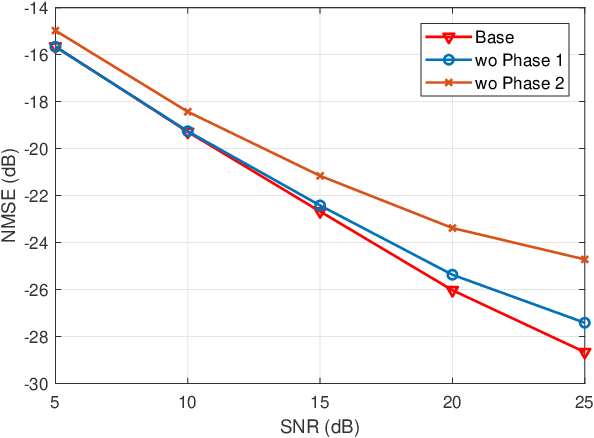
Accurate channel state information (CSI) acquisition is essential for modern wireless systems, which becomes increasingly difficult under large antenna arrays, strict pilot overhead constraints, and diverse deployment environments. Existing artificial intelligence-based solutions often lack robustness and fail to generalize across scenarios. To address this limitation, this paper introduces a predictive-foundation-model-based channel estimation framework that enables accurate, low-overhead, and generalizable CSI acquisition. The proposed framework employs a predictive foundation model trained on large-scale cross-domain CSI data to extract universal channel representations and provide predictive priors with strong cross-scenario transferability. A pilot processing network based on a vision transformer architecture is further designed to capture spatial, temporal, and frequency correlations from pilot observations. An efficient fusion mechanism integrates predictive priors with real-time measurements, enabling reliable CSI reconstruction even under sparse or noisy conditions. Extensive evaluations across diverse configurations demonstrate that the proposed estimator significantly outperforms both classical and data-driven baselines in accuracy, robustness, and generalization capability.
Next-Generation AI-Native Wireless Communications: MCMC-Based Receiver Architectures for Unified Processing
Oct 02, 2025The multiple-input multiple-output (MIMO) receiver processing is a key technology for current and next-generation wireless communications. However, it faces significant challenges related to complexity and scalability as the number of antennas increases. Artificial intelligence (AI), a cornerstone of next-generation wireless networks, offers considerable potential for addressing these challenges. This paper proposes an AI-driven, universal MIMO receiver architecture based on Markov chain Monte Carlo (MCMC) techniques. Unlike existing AI-based methods that treat receiver processing as a black box, our MCMC-based approach functions as a generic Bayesian computing engine applicable to various processing tasks, including channel estimation, symbol detection, and channel decoding. This method enhances the interpretability, scalability, and flexibility of receivers in diverse scenarios. Furthermore, the proposed approach integrates these tasks into a unified probabilistic framework, thereby enabling overall performance optimization. This unified framework can also be seamlessly combined with data-driven learning methods to facilitate the development of fully intelligent communication receivers.
Square$χ$PO: Differentially Private and Robust $χ^2$-Preference Optimization in Offline Direct Alignment
May 27, 2025In this paper, we theoretically study the offline alignment of language models with human preference feedback, under both preference label corruption and privacy protections. To this end, we propose Square$\chi$PO, a simple one-line change to $\chi$PO where the standard log-loss is replaced by a new square loss over probability. Thanks to the inherent properties of this new loss, we have advanced the state-of-the-art of differentially private and robust offline direct alignment. Specifically, for the local model of label privacy, Square$\chi$PO is the first algorithm that attains an optimal rate based on single-policy concentrability even with general function approximations. It also gives the first result under the central model of privacy protection over both prompts (responses) and labels. On the robustness side against Huber label corruption, Square$\chi$PO is the first alignment method that has a meaningful theoretical guarantee under general function approximations. More importantly, Square$\chi$PO can address privacy protection and corruption simultaneously, where an interesting separation is observed, implying that the order of privacy and corruption matters. Furthermore, we show that Square$\chi$PO can also be easily extended to handle the scenario of the general preference model with state-of-the-art guarantees under corruption and privacy. Last but not least, all of our theoretical guarantees enjoy a unified analysis, building upon a new result on the generalization error bounds of least-square regression under corruption and privacy constraints, which we believe is of independent interest to the community.