 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable Vector Quantization for Rate-Distortion Optimization of Generative Image Compression
Apr 12, 2026The rapid growth of visual data under stringent storage and bandwidth constraints makes extremely low-bitrate image compression increasingly important. While Vector Quantization (VQ) offers strong structural fidelity, existing methods lack a principled mechanism for joint rate-distortion (RD) optimization due to the disconnect between representation learning and entropy modeling. We propose RDVQ, a unified framework that enables end-to-end RD optimization for VQ-based compression via a differentiable relaxation of the codebook distribution, allowing the entropy loss to directly shape the latent prior. We further develop an autoregressive entropy model that supports accurate entropy modeling and test-time rate control. Extensive experiments demonstrate that RDVQ achieves strong performance at extremely low bitrates with a lightweight architecture, attaining competitive or superior perceptual quality with significantly fewer parameters. Compared with RDEIC, RDVQ reduces bitrate by up to 75.71% on DISTS and 37.63% on LPIPS on DIV2K-val. Beyond empirical gains, RDVQ introduces an entropy-constrained formulation of VQ, highlighting the potential for a more unified view of image tokenization and compression. The code will be available at https://github.com/CVL-UESTC/RDVQ.
Fusing Pixels and Genes: Spatially-Aware Learning in Computational Pathology
Feb 15, 2026Recent years have witnessed remarkable progress in multimodal learning within computational pathology. Existing models primarily rely on vision and language modalities; however, language alone lacks molecular specificity and offers limited pathological supervision, leading to representational bottlenecks. In this paper, we propose STAMP, a Spatial Transcriptomics-Augmented Multimodal Pathology representation learning framework that integrates spatially-resolved gene expression profiles to enable molecule-guided joint embedding of pathology images and transcriptomic data. Our study shows that self-supervised, gene-guided training provides a robust and task-agnostic signal for learning pathology image representations. Incorporating spatial context and multi-scale information further enhances model performance and generalizability. To support this, we constructed SpaVis-6M, the largest Visium-based spatial transcriptomics dataset to date, and trained a spatially-aware gene encoder on this resource. Leveraging hierarchical multi-scale contrastive alignment and cross-scale patch localization mechanisms, STAMP effectively aligns spatial transcriptomics with pathology images, capturing spatial structure and molecular variation. We validate STAMP across six datasets and four downstream tasks, where it consistently achieves strong performance. These results highlight the value and necessity of integrating spatially resolved molecular supervision for advancing multimodal learning in computational pathology. The code is included in the supplementary materials. The pretrained weights and SpaVis-6M are available at: https://github.com/Hanminghao/STAMP.
FeatureBench: Benchmarking Agentic Coding for Complex Feature Development
Feb 11, 2026Agents powered by large language models (LLMs) are increasingly adopted in the software industry, contributing code as collaborators or even autonomous developers. As their presence grows, it becomes important to assess the current boundaries of their coding abilities. Existing agentic coding benchmarks, however, cover a limited task scope, e.g., bug fixing within a single pull request (PR), and often rely on non-executable evaluations or lack an automated approach for continually updating the evaluation coverage. To address such issues, we propose FeatureBench, a benchmark designed to evaluate agentic coding performance in end-to-end, feature-oriented software development. FeatureBench incorporates an execution-based evaluation protocol and a scalable test-driven method that automatically derives tasks from code repositories with minimal human effort. By tracing from unit tests along a dependency graph, our approach can identify feature-level coding tasks spanning multiple commits and PRs scattered across the development timeline, while ensuring the proper functioning of other features after the separation. Using this framework, we curated 200 challenging evaluation tasks and 3825 executable environments from 24 open-source repositories in the first version of our benchmark. Empirical evaluation reveals that the state-of-the-art agentic model, such as Claude 4.5 Opus, which achieves a 74.4% resolved rate on SWE-bench, succeeds on only 11.0% of tasks, opening new opportunities for advancing agentic coding. Moreover, benefiting from our automated task collection toolkit, FeatureBench can be easily scaled and updated over time to mitigate data leakage. The inherent verifiability of constructed environments also makes our method potentially valuable for agent training.
Exploring Physical Intelligence Emergence via Omni-Modal Architecture and Physical Data Engine
Feb 05, 2026Physical understanding remains brittle in omni-modal models because key physical attributes are visually ambiguous and sparsely represented in web-scale data. We present OmniFysics, a compact omni-modal model that unifies understanding across images, audio, video, and text, with integrated speech and image generation. To inject explicit physical knowledge, we build a physical data engine with two components. FysicsAny produces physics-grounded instruction--image supervision by mapping salient objects to verified physical attributes through hierarchical retrieval over a curated prototype database, followed by physics-law--constrained verification and caption rewriting. FysicsOmniCap distills web videos via audio--visual consistency filtering to generate high-fidelity video--instruction pairs emphasizing cross-modal physical cues. We train OmniFysics with staged multimodal alignment and instruction tuning, adopt latent-space flow matching for text-to-image generation, and use an intent router to activate generation only when needed. Experiments show competitive performance on standard multimodal benchmarks and improved results on physics-oriented evaluations.
FasterPy: An LLM-based Code Execution Efficiency Optimization Framework
Dec 28, 2025Code often suffers from performance bugs. These bugs necessitate the research and practice of code optimization. Traditional rule-based methods rely on manually designing and maintaining rules for specific performance bugs (e.g., redundant loops, repeated computations), making them labor-intensive and limited in applicability. In recent years, machine learning and deep learning-based methods have emerged as promising alternatives by learning optimization heuristics from annotated code corpora and performance measurements. However, these approaches usually depend on specific program representations and meticulously crafted training datasets, making them costly to develop and difficult to scale. With the booming of Large Language Models (LLMs), their remarkable capabilities in code generation have opened new avenues for automated code optimization. In this work, we proposed FasterPy, a low-cost and efficient framework that adapts LLMs to optimize the execution efficiency of Python code. FasterPy combines Retrieval-Augmented Generation (RAG), supported by a knowledge base constructed from existing performance-improving code pairs and corresponding performance measurements, with Low-Rank Adaptation (LoRA) to enhance code optimization performance. Our experimental results on the Performance Improving Code Edits (PIE) benchmark demonstrate that our method outperforms existing models on multiple metrics. The FasterPy tool and the experimental results are available at https://github.com/WuYue22/fasterpy.
Beyond Pixel Simulation: Pathology Image Generation via Diagnostic Semantic Tokens and Prototype Control
Dec 24, 2025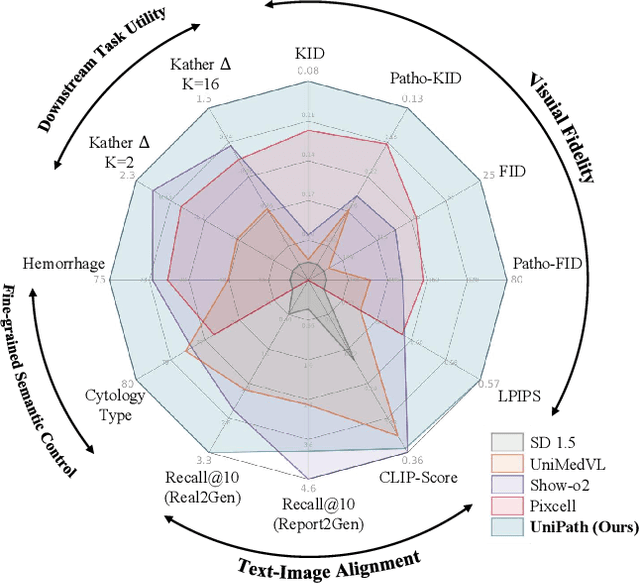
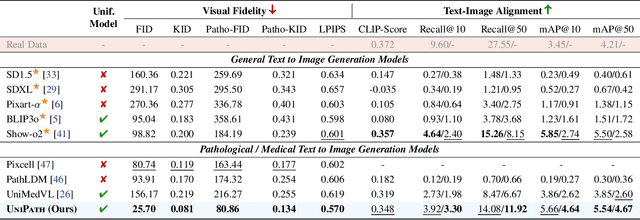
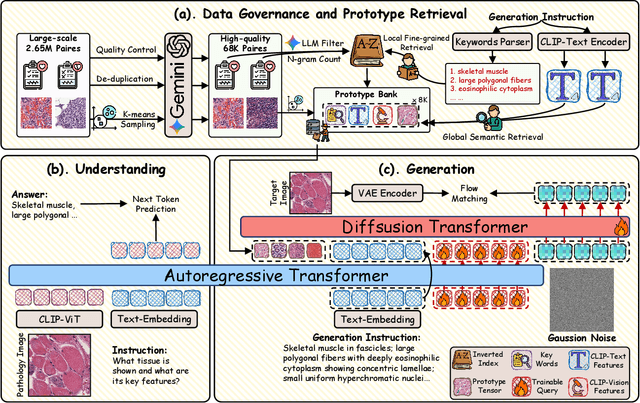
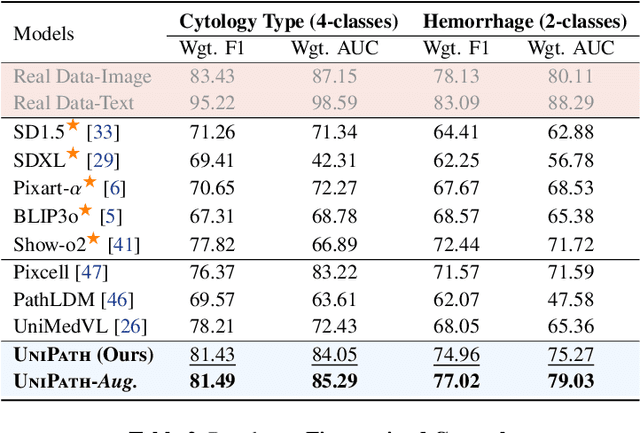
In computational pathology, understanding and generation have evolved along disparate paths: advanced understanding models already exhibit diagnostic-level competence, whereas generative models largely simulate pixels. Progress remains hindered by three coupled factors: the scarcity of large, high-quality image-text corpora; the lack of precise, fine-grained semantic control, which forces reliance on non-semantic cues; and terminological heterogeneity, where diverse phrasings for the same diagnostic concept impede reliable text conditioning. We introduce UniPath, a semantics-driven pathology image generation framework that leverages mature diagnostic understanding to enable controllable generation. UniPath implements Multi-Stream Control: a Raw-Text stream; a High-Level Semantics stream that uses learnable queries to a frozen pathology MLLM to distill paraphrase-robust Diagnostic Semantic Tokens and to expand prompts into diagnosis-aware attribute bundles; and a Prototype stream that affords component-level morphological control via a prototype bank. On the data front, we curate a 2.65M image-text corpus and a finely annotated, high-quality 68K subset to alleviate data scarcity. For a comprehensive assessment, we establish a four-tier evaluation hierarchy tailored to pathology. Extensive experiments demonstrate UniPath's SOTA performance, including a Patho-FID of 80.9 (51% better than the second-best) and fine-grained semantic control achieving 98.7% of the real-image. The meticulously curated datasets, complete source code, and pre-trained model weights developed in this study will be made openly accessible to the public.
Forging a Dynamic Memory: Retrieval-Guided Continual Learning for Generalist Medical Foundation Models
Dec 15, 2025Multimodal biomedical Vision-Language Models (VLMs) exhibit immense potential in the field of Continual Learning (CL). However, they confront a core dilemma: how to preserve fine-grained intra-modality features while bridging the significant domain gap across different modalities. To address this challenge, we propose a comprehensive framework. Leveraging our 18-million multimodal and comprehensive medical retrieval database derived from PubMed scientific papers, we pioneer the integration of Retrieval-Augmented Generation (RAG) into CL. Specifically, we employ a multi-modal, multi-layer RAG system that provides real-time guidance for model fine-tuning through dynamic, on-demand knowledge retrieval. Building upon this, we introduce a dynamic knowledge distillation framework. This framework precisely resolves the aforementioned core dilemma by dynamically modulating the importance of the parameter space, the granularity of the distilled knowledge, and the data distribution of the reference dataset in accordance with the required level of detail. To thoroughly validate the clinical value of our strategy, we have designed a more rigorous \textbf{M}edical Generalist Task Incremental Learning (MGTIL) benchmark. This benchmark is engineered to simultaneously evaluate the model's capacity for adaptation to significant domain shifts, retention of subtle intra-domain features, and real-time learning of novel and complex medical tasks. Extensive experimental results demonstrate that our proposed method achieves state-of-the-art (SOTA) performance across all metrics. The code is provided in the supplementary materials.
FysicsWorld: A Unified Full-Modality Benchmark for Any-to-Any Understanding, Generation, and Reasoning
Dec 14, 2025Despite rapid progress in multimodal large language models (MLLMs) and emerging omni-modal architectures, current benchmarks remain limited in scope and integration, suffering from incomplete modality coverage, restricted interaction to text-centric outputs, and weak interdependence and complementarity among modalities. To bridge these gaps, we introduce FysicsWorld, the first unified full-modality benchmark that supports bidirectional input-output across image, video, audio, and text, enabling comprehensive any-to-any evaluation across understanding, generation, and reasoning. FysicsWorld encompasses 16 primary tasks and 3,268 curated samples, aggregated from over 40 high-quality sources and covering a rich set of open-domain categories with diverse question types. We also propose the Cross-Modal Complementarity Screening (CMCS) strategy integrated in a systematic data construction framework that produces omni-modal data for spoken interaction and fusion-dependent cross-modal reasoning. Through a comprehensive evaluation of over 30 state-of-the-art baselines, spanning MLLMs, modality-specific models, unified understanding-generation models, and omni-modal language models, FysicsWorld exposes the performance disparities and limitations across models in understanding, generation, and reasoning. Our benchmark establishes a unified foundation and strong baselines for evaluating and advancing next-generation full-modality architectures.
PersonaAnimator: Personalized Motion Transfer from Unconstrained Videos
Aug 27, 2025Recent advances in motion generation show remarkable progress. However, several limitations remain: (1) Existing pose-guided character motion transfer methods merely replicate motion without learning its style characteristics, resulting in inexpressive characters. (2) Motion style transfer methods rely heavily on motion capture data, which is difficult to obtain. (3) Generated motions sometimes violate physical laws. To address these challenges, this paper pioneers a new task: Video-to-Video Motion Personalization. We propose a novel framework, PersonaAnimator, which learns personalized motion patterns directly from unconstrained videos. This enables personalized motion transfer. To support this task, we introduce PersonaVid, the first video-based personalized motion dataset. It contains 20 motion content categories and 120 motion style categories. We further propose a Physics-aware Motion Style Regularization mechanism to enforce physical plausibility in the generated motions. Extensive experiments show that PersonaAnimator outperforms state-of-the-art motion transfer methods and sets a new benchmark for the Video-to-Video Motion Personalization task.
Generative Image Compression by Estimating Gradients of the Rate-variable Feature Distribution
May 27, 2025While learned image compression (LIC) focuses on efficient data transmission, generative image compression (GIC) extends this framework by integrating generative modeling to produce photo-realistic reconstructed images. In this paper, we propose a novel diffusion-based generative modeling framework tailored for generative image compression. Unlike prior diffusion-based approaches that indirectly exploit diffusion modeling, we reinterpret the compression process itself as a forward diffusion path governed by stochastic differential equations (SDEs). A reverse neural network is trained to reconstruct images by reversing the compression process directly, without requiring Gaussian noise initialization. This approach achieves smooth rate adjustment and photo-realistic reconstructions with only a minimal number of sampling steps. Extensive experiments on benchmark datasets demonstrate that our method outperforms existing generative image compression approaches across a range of metrics, including perceptual distortion, statistical fidelity, and no-reference quality assessments.