 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartial Decoder Attention Network with Contour-weighted Loss Function for Data-Imbalance Medical Image Segmentation
Jan 20, 2026Image segmentation is pivotal in medical image analysis, facilitating clinical diagnosis, treatment planning, and disease evaluation. Deep learning has significantly advanced automatic segmentation methodologies by providing superior modeling capability for complex structures and fine-grained anatomical regions. However, medical images often suffer from data imbalance issues, such as large volume disparities among organs or tissues, and uneven sample distributions across different anatomical structures. This imbalance tends to bias the model toward larger organs or more frequently represented structures, while overlooking smaller or less represented structures, thereby affecting the segmentation accuracy and robustness. To address these challenges, we proposed a novel contour-weighted segmentation approach, which improves the model's capability to represent small and underrepresented structures. We developed PDANet, a lightweight and efficient segmentation network based on a partial decoder mechanism. We evaluated our method using three prominent public datasets. The experimental results show that our methodology excelled in three distinct tasks: segmenting multiple abdominal organs, brain tumors, and pelvic bone fragments with injuries. It consistently outperformed nine state-of-the-art methods. Moreover, the proposed contour-weighted strategy improved segmentation for other comparison methods across the three datasets, yielding average enhancements in Dice scores of 2.32%, 1.67%, and 3.60%, respectively. These results demonstrate that our contour-weighted segmentation method surpassed current leading approaches in both accuracy and robustness. As a model-independent strategy, it can seamlessly fit various segmentation frameworks, enhancing their performance. This flexibility highlighted its practical importance and potential for broad use in medical image analysis.
Beyond Pixel Simulation: Pathology Image Generation via Diagnostic Semantic Tokens and Prototype Control
Dec 24, 2025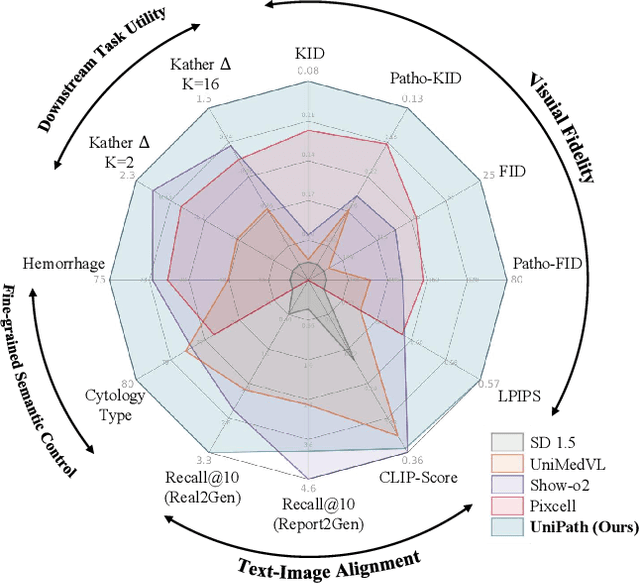
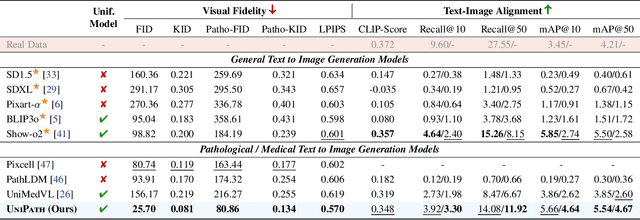
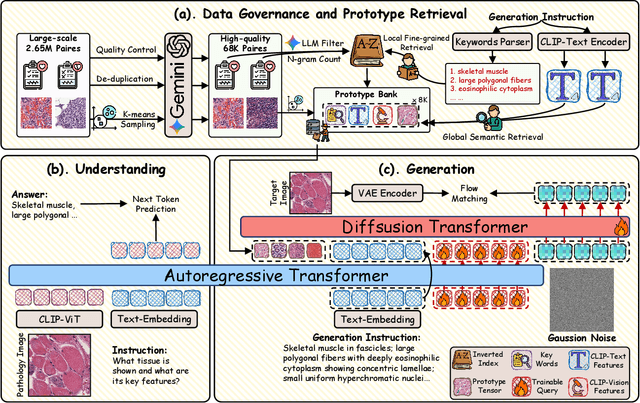
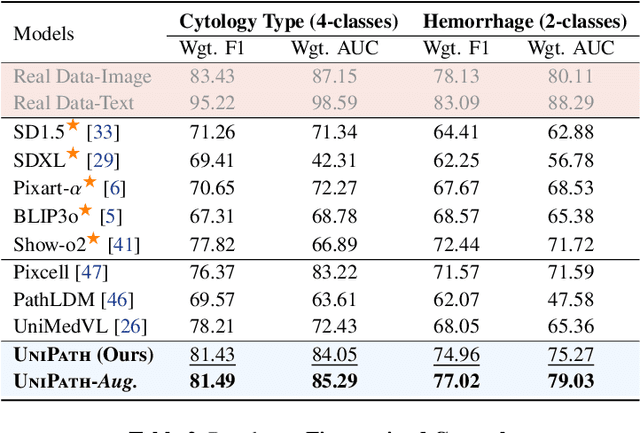
In computational pathology, understanding and generation have evolved along disparate paths: advanced understanding models already exhibit diagnostic-level competence, whereas generative models largely simulate pixels. Progress remains hindered by three coupled factors: the scarcity of large, high-quality image-text corpora; the lack of precise, fine-grained semantic control, which forces reliance on non-semantic cues; and terminological heterogeneity, where diverse phrasings for the same diagnostic concept impede reliable text conditioning. We introduce UniPath, a semantics-driven pathology image generation framework that leverages mature diagnostic understanding to enable controllable generation. UniPath implements Multi-Stream Control: a Raw-Text stream; a High-Level Semantics stream that uses learnable queries to a frozen pathology MLLM to distill paraphrase-robust Diagnostic Semantic Tokens and to expand prompts into diagnosis-aware attribute bundles; and a Prototype stream that affords component-level morphological control via a prototype bank. On the data front, we curate a 2.65M image-text corpus and a finely annotated, high-quality 68K subset to alleviate data scarcity. For a comprehensive assessment, we establish a four-tier evaluation hierarchy tailored to pathology. Extensive experiments demonstrate UniPath's SOTA performance, including a Patho-FID of 80.9 (51% better than the second-best) and fine-grained semantic control achieving 98.7% of the real-image. The meticulously curated datasets, complete source code, and pre-trained model weights developed in this study will be made openly accessible to the public.
Forging a Dynamic Memory: Retrieval-Guided Continual Learning for Generalist Medical Foundation Models
Dec 15, 2025Multimodal biomedical Vision-Language Models (VLMs) exhibit immense potential in the field of Continual Learning (CL). However, they confront a core dilemma: how to preserve fine-grained intra-modality features while bridging the significant domain gap across different modalities. To address this challenge, we propose a comprehensive framework. Leveraging our 18-million multimodal and comprehensive medical retrieval database derived from PubMed scientific papers, we pioneer the integration of Retrieval-Augmented Generation (RAG) into CL. Specifically, we employ a multi-modal, multi-layer RAG system that provides real-time guidance for model fine-tuning through dynamic, on-demand knowledge retrieval. Building upon this, we introduce a dynamic knowledge distillation framework. This framework precisely resolves the aforementioned core dilemma by dynamically modulating the importance of the parameter space, the granularity of the distilled knowledge, and the data distribution of the reference dataset in accordance with the required level of detail. To thoroughly validate the clinical value of our strategy, we have designed a more rigorous \textbf{M}edical Generalist Task Incremental Learning (MGTIL) benchmark. This benchmark is engineered to simultaneously evaluate the model's capacity for adaptation to significant domain shifts, retention of subtle intra-domain features, and real-time learning of novel and complex medical tasks. Extensive experimental results demonstrate that our proposed method achieves state-of-the-art (SOTA) performance across all metrics. The code is provided in the supplementary materials.
FysicsWorld: A Unified Full-Modality Benchmark for Any-to-Any Understanding, Generation, and Reasoning
Dec 14, 2025Despite rapid progress in multimodal large language models (MLLMs) and emerging omni-modal architectures, current benchmarks remain limited in scope and integration, suffering from incomplete modality coverage, restricted interaction to text-centric outputs, and weak interdependence and complementarity among modalities. To bridge these gaps, we introduce FysicsWorld, the first unified full-modality benchmark that supports bidirectional input-output across image, video, audio, and text, enabling comprehensive any-to-any evaluation across understanding, generation, and reasoning. FysicsWorld encompasses 16 primary tasks and 3,268 curated samples, aggregated from over 40 high-quality sources and covering a rich set of open-domain categories with diverse question types. We also propose the Cross-Modal Complementarity Screening (CMCS) strategy integrated in a systematic data construction framework that produces omni-modal data for spoken interaction and fusion-dependent cross-modal reasoning. Through a comprehensive evaluation of over 30 state-of-the-art baselines, spanning MLLMs, modality-specific models, unified understanding-generation models, and omni-modal language models, FysicsWorld exposes the performance disparities and limitations across models in understanding, generation, and reasoning. Our benchmark establishes a unified foundation and strong baselines for evaluating and advancing next-generation full-modality architectures.
Improving Multimodal Sentiment Analysis via Modality Optimization and Dynamic Primary Modality Selection
Nov 14, 2025Multimodal Sentiment Analysis (MSA) aims to predict sentiment from language, acoustic, and visual data in videos. However, imbalanced unimodal performance often leads to suboptimal fused representations. Existing approaches typically adopt fixed primary modality strategies to maximize dominant modality advantages, yet fail to adapt to dynamic variations in modality importance across different samples. Moreover, non-language modalities suffer from sequential redundancy and noise, degrading model performance when they serve as primary inputs. To address these issues, this paper proposes a modality optimization and dynamic primary modality selection framework (MODS). First, a Graph-based Dynamic Sequence Compressor (GDC) is constructed, which employs capsule networks and graph convolution to reduce sequential redundancy in acoustic/visual modalities. Then, we develop a sample-adaptive Primary Modality Selector (MSelector) for dynamic dominance determination. Finally, a Primary-modality-Centric Cross-Attention (PCCA) module is designed to enhance dominant modalities while facilitating cross-modal interaction. Extensive experiments on four benchmark datasets demonstrate that MODS outperforms state-of-the-art methods, achieving superior performance by effectively balancing modality contributions and eliminating redundant noise.
RENet: Fault-Tolerant Motion Control for Quadruped Robots via Redundant Estimator Networks under Visual Collapse
Sep 11, 2025Vision-based locomotion in outdoor environments presents significant challenges for quadruped robots. Accurate environmental prediction and effective handling of depth sensor noise during real-world deployment remain difficult, severely restricting the outdoor applications of such algorithms. To address these deployment challenges in vision-based motion control, this letter proposes the Redundant Estimator Network (RENet) framework. The framework employs a dual-estimator architecture that ensures robust motion performance while maintaining deployment stability during onboard vision failures. Through an online estimator adaptation, our method enables seamless transitions between estimation modules when handling visual perception uncertainties. Experimental validation on a real-world robot demonstrates the framework's effectiveness in complex outdoor environments, showing particular advantages in scenarios with degraded visual perception. This framework demonstrates its potential as a practical solution for reliable robotic deployment in challenging field conditions. Project website: https://RENet-Loco.github.io/
* Accepted for IEEE Robotics and Automation Letters (RA-L)
PersonaAnimator: Personalized Motion Transfer from Unconstrained Videos
Aug 27, 2025Recent advances in motion generation show remarkable progress. However, several limitations remain: (1) Existing pose-guided character motion transfer methods merely replicate motion without learning its style characteristics, resulting in inexpressive characters. (2) Motion style transfer methods rely heavily on motion capture data, which is difficult to obtain. (3) Generated motions sometimes violate physical laws. To address these challenges, this paper pioneers a new task: Video-to-Video Motion Personalization. We propose a novel framework, PersonaAnimator, which learns personalized motion patterns directly from unconstrained videos. This enables personalized motion transfer. To support this task, we introduce PersonaVid, the first video-based personalized motion dataset. It contains 20 motion content categories and 120 motion style categories. We further propose a Physics-aware Motion Style Regularization mechanism to enforce physical plausibility in the generated motions. Extensive experiments show that PersonaAnimator outperforms state-of-the-art motion transfer methods and sets a new benchmark for the Video-to-Video Motion Personalization task.
COPO: Consistency-Aware Policy Optimization
Aug 06, 2025Reinforcement learning has significantly enhanced the reasoning capabilities of Large Language Models (LLMs) in complex problem-solving tasks. Recently, the introduction of DeepSeek R1 has inspired a surge of interest in leveraging rule-based rewards as a low-cost alternative for computing advantage functions and guiding policy optimization. However, a common challenge observed across many replication and extension efforts is that when multiple sampled responses under a single prompt converge to identical outcomes, whether correct or incorrect, the group-based advantage degenerates to zero. This leads to vanishing gradients and renders the corresponding samples ineffective for learning, ultimately limiting training efficiency and downstream performance. To address this issue, we propose a consistency-aware policy optimization framework that introduces a structured global reward based on outcome consistency, the global loss based on it ensures that, even when model outputs show high intra-group consistency, the training process still receives meaningful learning signals, which encourages the generation of correct and self-consistent reasoning paths from a global perspective. Furthermore, we incorporate an entropy-based soft blending mechanism that adaptively balances local advantage estimation with global optimization, enabling dynamic transitions between exploration and convergence throughout training. Our method introduces several key innovations in both reward design and optimization strategy. We validate its effectiveness through substantial performance gains on multiple mathematical reasoning benchmarks, highlighting the proposed framework's robustness and general applicability. Code of this work has been released at https://github.com/hijih/copo-code.git.
PIG: Physically-based Multi-Material Interaction with 3D Gaussians
Jun 09, 20253D Gaussian Splatting has achieved remarkable success in reconstructing both static and dynamic 3D scenes. However, in a scene represented by 3D Gaussian primitives, interactions between objects suffer from inaccurate 3D segmentation, imprecise deformation among different materials, and severe rendering artifacts. To address these challenges, we introduce PIG: Physically-Based Multi-Material Interaction with 3D Gaussians, a novel approach that combines 3D object segmentation with the simulation of interacting objects in high precision. Firstly, our method facilitates fast and accurate mapping from 2D pixels to 3D Gaussians, enabling precise 3D object-level segmentation. Secondly, we assign unique physical properties to correspondingly segmented objects within the scene for multi-material coupled interactions. Finally, we have successfully embedded constraint scales into deformation gradients, specifically clamping the scaling and rotation properties of the Gaussian primitives to eliminate artifacts and achieve geometric fidelity and visual consistency. Experimental results demonstrate that our method not only outperforms the state-of-the-art (SOTA) in terms of visual quality, but also opens up new directions and pipelines for the field of physically realistic scene generation.
MCCD: Multi-Agent Collaboration-based Compositional Diffusion for Complex Text-to-Image Generation
May 05, 2025Diffusion models have shown excellent performance in text-to-image generation. Nevertheless, existing methods often suffer from performance bottlenecks when handling complex prompts that involve multiple objects, characteristics, and relations. Therefore, we propose a Multi-agent Collaboration-based Compositional Diffusion (MCCD) for text-to-image generation for complex scenes. Specifically, we design a multi-agent collaboration-based scene parsing module that generates an agent system comprising multiple agents with distinct tasks, utilizing MLLMs to extract various scene elements effectively. In addition, Hierarchical Compositional diffusion utilizes a Gaussian mask and filtering to refine bounding box regions and enhance objects through region enhancement, resulting in the accurate and high-fidelity generation of complex scenes. Comprehensive experiments demonstrate that our MCCD significantly improves the performance of the baseline models in a training-free manner, providing a substantial advantage in complex scene generation.