 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenAgent: Scaling Text-to-Image Generation via Agentic Multimodal Reasoning
Jan 26, 2026We introduce GenAgent, unifying visual understanding and generation through an agentic multimodal model. Unlike unified models that face expensive training costs and understanding-generation trade-offs, GenAgent decouples these capabilities through an agentic framework: understanding is handled by the multimodal model itself, while generation is achieved by treating image generation models as invokable tools. Crucially, unlike existing modular systems constrained by static pipelines, this design enables autonomous multi-turn interactions where the agent generates multimodal chains-of-thought encompassing reasoning, tool invocation, judgment, and reflection to iteratively refine outputs. We employ a two-stage training strategy: first, cold-start with supervised fine-tuning on high-quality tool invocation and reflection data to bootstrap agent behaviors; second, end-to-end agentic reinforcement learning combining pointwise rewards (final image quality) and pairwise rewards (reflection accuracy), with trajectory resampling for enhanced multi-turn exploration. GenAgent significantly boosts base generator(FLUX.1-dev) performance on GenEval++ (+23.6\%) and WISE (+14\%). Beyond performance gains, our framework demonstrates three key properties: 1) cross-tool generalization to generators with varying capabilities, 2) test-time scaling with consistent improvements across interaction rounds, and 3) task-adaptive reasoning that automatically adjusts to different tasks. Our code will be available at \href{https://github.com/deep-kaixun/GenAgent}{this url}.
Forging a Dynamic Memory: Retrieval-Guided Continual Learning for Generalist Medical Foundation Models
Dec 15, 2025Multimodal biomedical Vision-Language Models (VLMs) exhibit immense potential in the field of Continual Learning (CL). However, they confront a core dilemma: how to preserve fine-grained intra-modality features while bridging the significant domain gap across different modalities. To address this challenge, we propose a comprehensive framework. Leveraging our 18-million multimodal and comprehensive medical retrieval database derived from PubMed scientific papers, we pioneer the integration of Retrieval-Augmented Generation (RAG) into CL. Specifically, we employ a multi-modal, multi-layer RAG system that provides real-time guidance for model fine-tuning through dynamic, on-demand knowledge retrieval. Building upon this, we introduce a dynamic knowledge distillation framework. This framework precisely resolves the aforementioned core dilemma by dynamically modulating the importance of the parameter space, the granularity of the distilled knowledge, and the data distribution of the reference dataset in accordance with the required level of detail. To thoroughly validate the clinical value of our strategy, we have designed a more rigorous \textbf{M}edical Generalist Task Incremental Learning (MGTIL) benchmark. This benchmark is engineered to simultaneously evaluate the model's capacity for adaptation to significant domain shifts, retention of subtle intra-domain features, and real-time learning of novel and complex medical tasks. Extensive experimental results demonstrate that our proposed method achieves state-of-the-art (SOTA) performance across all metrics. The code is provided in the supplementary materials.
Seeing is Believing: Rich-Context Hallucination Detection for MLLMs via Backward Visual Grounding
Nov 15, 2025Multimodal Large Language Models (MLLMs) have unlocked powerful cross-modal capabilities, but still significantly suffer from hallucinations. As such, accurate detection of hallucinations in MLLMs is imperative for ensuring their reliability in practical applications. To this end, guided by the principle of "Seeing is Believing", we introduce VBackChecker, a novel reference-free hallucination detection framework that verifies the consistency of MLLMgenerated responses with visual inputs, by leveraging a pixellevel Grounding LLM equipped with reasoning and referring segmentation capabilities. This reference-free framework not only effectively handles rich-context scenarios, but also offers interpretability. To facilitate this, an innovative pipeline is accordingly designed for generating instruction-tuning data (R-Instruct), featuring rich-context descriptions, grounding masks, and hard negative samples. We further establish R^2 -HalBench, a new hallucination benchmark for MLLMs, which, unlike previous benchmarks, encompasses real-world, rich-context descriptions from 18 MLLMs with high-quality annotations, spanning diverse object-, attribute, and relationship-level details. VBackChecker outperforms prior complex frameworks and achieves state-of-the-art performance on R^2 -HalBench, even rivaling GPT-4o's capabilities in hallucination detection. It also surpasses prior methods in the pixel-level grounding task, achieving over a 10% improvement. All codes, data, and models are available at https://github.com/PinxueGuo/VBackChecker.
Improving Multimodal Sentiment Analysis via Modality Optimization and Dynamic Primary Modality Selection
Nov 14, 2025Multimodal Sentiment Analysis (MSA) aims to predict sentiment from language, acoustic, and visual data in videos. However, imbalanced unimodal performance often leads to suboptimal fused representations. Existing approaches typically adopt fixed primary modality strategies to maximize dominant modality advantages, yet fail to adapt to dynamic variations in modality importance across different samples. Moreover, non-language modalities suffer from sequential redundancy and noise, degrading model performance when they serve as primary inputs. To address these issues, this paper proposes a modality optimization and dynamic primary modality selection framework (MODS). First, a Graph-based Dynamic Sequence Compressor (GDC) is constructed, which employs capsule networks and graph convolution to reduce sequential redundancy in acoustic/visual modalities. Then, we develop a sample-adaptive Primary Modality Selector (MSelector) for dynamic dominance determination. Finally, a Primary-modality-Centric Cross-Attention (PCCA) module is designed to enhance dominant modalities while facilitating cross-modal interaction. Extensive experiments on four benchmark datasets demonstrate that MODS outperforms state-of-the-art methods, achieving superior performance by effectively balancing modality contributions and eliminating redundant noise.
Invert4TVG: A Temporal Video Grounding Framework with Inversion Tasks for Enhanced Action Understanding
Aug 10, 2025Temporal Video Grounding (TVG) seeks to localize video segments matching a given textual query. Current methods, while optimizing for high temporal Intersection-over-Union (IoU), often overfit to this metric, compromising semantic action understanding in the video and query, a critical factor for robust TVG. To address this, we introduce Inversion Tasks for TVG (Invert4TVG), a novel framework that enhances both localization accuracy and action understanding without additional data. Our approach leverages three inversion tasks derived from existing TVG annotations: (1) Verb Completion, predicting masked action verbs in queries from video segments; (2) Action Recognition, identifying query-described actions; and (3) Video Description, generating descriptions of video segments that explicitly embed query-relevant actions. These tasks, integrated with TVG via a reinforcement learning framework with well-designed reward functions, ensure balanced optimization of localization and semantics. Experiments show our method outperforms state-of-the-art approaches, achieving a 7.1\% improvement in R1@0.7 on Charades-STA for a 3B model compared to Time-R1. By inverting TVG to derive query-related actions from segments, our approach strengthens semantic understanding, significantly raising the ceiling of localization accuracy.
LingoLoop Attack: Trapping MLLMs via Linguistic Context and State Entrapment into Endless Loops
Jun 17, 2025Multimodal Large Language Models (MLLMs) have shown great promise but require substantial computational resources during inference. Attackers can exploit this by inducing excessive output, leading to resource exhaustion and service degradation. Prior energy-latency attacks aim to increase generation time by broadly shifting the output token distribution away from the EOS token, but they neglect the influence of token-level Part-of-Speech (POS) characteristics on EOS and sentence-level structural patterns on output counts, limiting their efficacy. To address this, we propose LingoLoop, an attack designed to induce MLLMs to generate excessively verbose and repetitive sequences. First, we find that the POS tag of a token strongly affects the likelihood of generating an EOS token. Based on this insight, we propose a POS-Aware Delay Mechanism to postpone EOS token generation by adjusting attention weights guided by POS information. Second, we identify that constraining output diversity to induce repetitive loops is effective for sustained generation. We introduce a Generative Path Pruning Mechanism that limits the magnitude of hidden states, encouraging the model to produce persistent loops. Extensive experiments demonstrate LingoLoop can increase generated tokens by up to 30 times and energy consumption by a comparable factor on models like Qwen2.5-VL-3B, consistently driving MLLMs towards their maximum generation limits. These findings expose significant MLLMs' vulnerabilities, posing challenges for their reliable deployment. The code will be released publicly following the paper's acceptance.
dFLMoE: Decentralized Federated Learning via Mixture of Experts for Medical Data Analysis
Mar 13, 2025Federated learning has wide applications in the medical field. It enables knowledge sharing among different healthcare institutes while protecting patients' privacy. However, existing federated learning systems are typically centralized, requiring clients to upload client-specific knowledge to a central server for aggregation. This centralized approach would integrate the knowledge from each client into a centralized server, and the knowledge would be already undermined during the centralized integration before it reaches back to each client. Besides, the centralized approach also creates a dependency on the central server, which may affect training stability if the server malfunctions or connections are unstable. To address these issues, we propose a decentralized federated learning framework named dFLMoE. In our framework, clients directly exchange lightweight head models with each other. After exchanging, each client treats both local and received head models as individual experts, and utilizes a client-specific Mixture of Experts (MoE) approach to make collective decisions. This design not only reduces the knowledge damage with client-specific aggregations but also removes the dependency on the central server to enhance the robustness of the framework. We validate our framework on multiple medical tasks, demonstrating that our method evidently outperforms state-of-the-art approaches under both model homogeneity and heterogeneity settings.
MMARD: Improving the Min-Max Optimization Process in Adversarial Robustness Distillation
Mar 09, 2025Adversarial Robustness Distillation (ARD) is a promising task to boost the robustness of small-capacity models with the guidance of the pre-trained robust teacher. The ARD can be summarized as a min-max optimization process, i.e., synthesizing adversarial examples (inner) & training the student (outer). Although competitive robustness performance, existing ARD methods still have issues. In the inner process, the synthetic training examples are far from the teacher's decision boundary leading to important robust information missing. In the outer process, the student model is decoupled from learning natural and robust scenarios, leading to the robustness saturation, i.e., student performance is highly susceptible to customized teacher selection. To tackle these issues, this paper proposes a general Min-Max optimization Adversarial Robustness Distillation (MMARD) method. For the inner process, we introduce the teacher's robust predictions, which drive the training examples closer to the teacher's decision boundary to explore more robust knowledge. For the outer process, we propose a structured information modeling method based on triangular relationships to measure the mutual information of the model in natural and robust scenarios and enhance the model's ability to understand multi-scenario mapping relationships. Experiments show our MMARD achieves state-of-the-art performance on multiple benchmarks. Besides, MMARD is plug-and-play and convenient to combine with existing methods.
VideoPure: Diffusion-based Adversarial Purification for Video Recognition
Jan 25, 2025



Recent work indicates that video recognition models are vulnerable to adversarial examples, posing a serious security risk to downstream applications. However, current research has primarily focused on adversarial attacks, with limited work exploring defense mechanisms. Furthermore, due to the spatial-temporal complexity of videos, existing video defense methods face issues of high cost, overfitting, and limited defense performance. Recently, diffusion-based adversarial purification methods have achieved robust defense performance in the image domain. However, due to the additional temporal dimension in videos, directly applying these diffusion-based adversarial purification methods to the video domain suffers performance and efficiency degradation. To achieve an efficient and effective video adversarial defense method, we propose the first diffusion-based video purification framework to improve video recognition models' adversarial robustness: VideoPure. Given an adversarial example, we first employ temporal DDIM inversion to transform the input distribution into a temporally consistent and trajectory-defined distribution, covering adversarial noise while preserving more video structure. Then, during DDIM denoising, we leverage intermediate results at each denoising step and conduct guided spatial-temporal optimization, removing adversarial noise while maintaining temporal consistency. Finally, we input the list of optimized intermediate results into the video recognition model for multi-step voting to obtain the predicted class. We investigate the defense performance of our method against black-box, gray-box, and adaptive attacks on benchmark datasets and models. Compared with other adversarial purification methods, our method overall demonstrates better defense performance against different attacks. Our code is available at https://github.com/deep-kaixun/VideoPure.
Pruning for Sparse Diffusion Models based on Gradient Flow
Jan 16, 2025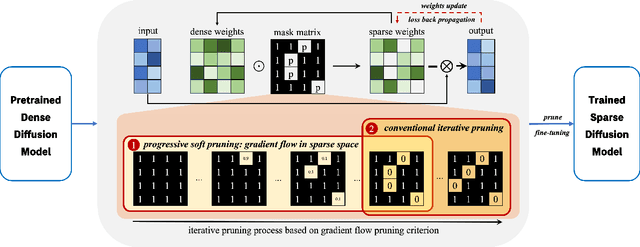
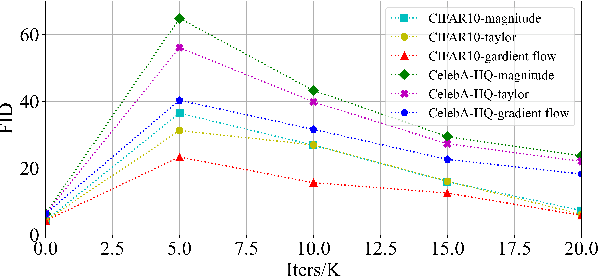
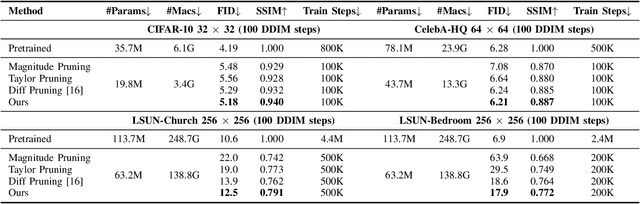
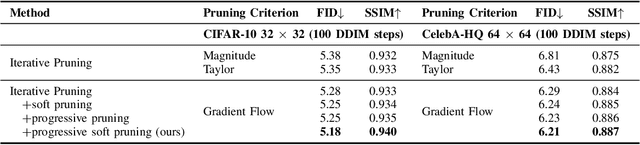
Diffusion Models (DMs) have impressive capabilities among generation models, but are limited to slower inference speeds and higher computational costs. Previous works utilize one-shot structure pruning to derive lightweight DMs from pre-trained ones, but this approach often leads to a significant drop in generation quality and may result in the removal of crucial weights. Thus we propose a iterative pruning method based on gradient flow, including the gradient flow pruning process and the gradient flow pruning criterion. We employ a progressive soft pruning strategy to maintain the continuity of the mask matrix and guide it along the gradient flow of the energy function based on the pruning criterion in sparse space, thereby avoiding the sudden information loss typically caused by one-shot pruning. Gradient-flow based criterion prune parameters whose removal increases the gradient norm of loss function and can enable fast convergence for a pruned model in iterative pruning stage. Our extensive experiments on widely used datasets demonstrate that our method achieves superior performance in efficiency and consistency with pre-trained models.