 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePP-Motion: Physical-Perceptual Fidelity Evaluation for Human Motion Generation
Aug 11, 2025Human motion generation has found widespread applications in AR/VR, film, sports, and medical rehabilitation, offering a cost-effective alternative to traditional motion capture systems. However, evaluating the fidelity of such generated motions is a crucial, multifaceted task. Although previous approaches have attempted at motion fidelity evaluation using human perception or physical constraints, there remains an inherent gap between human-perceived fidelity and physical feasibility. Moreover, the subjective and coarse binary labeling of human perception further undermines the development of a robust data-driven metric. We address these issues by introducing a physical labeling method. This method evaluates motion fidelity by calculating the minimum modifications needed for a motion to align with physical laws. With this approach, we are able to produce fine-grained, continuous physical alignment annotations that serve as objective ground truth. With these annotations, we propose PP-Motion, a novel data-driven metric to evaluate both physical and perceptual fidelity of human motion. To effectively capture underlying physical priors, we employ Pearson's correlation loss for the training of our metric. Additionally, by incorporating a human-based perceptual fidelity loss, our metric can capture fidelity that simultaneously considers both human perception and physical alignment. Experimental results demonstrate that our metric, PP-Motion, not only aligns with physical laws but also aligns better with human perception of motion fidelity than previous work.
dFLMoE: Decentralized Federated Learning via Mixture of Experts for Medical Data Analysis
Mar 13, 2025Federated learning has wide applications in the medical field. It enables knowledge sharing among different healthcare institutes while protecting patients' privacy. However, existing federated learning systems are typically centralized, requiring clients to upload client-specific knowledge to a central server for aggregation. This centralized approach would integrate the knowledge from each client into a centralized server, and the knowledge would be already undermined during the centralized integration before it reaches back to each client. Besides, the centralized approach also creates a dependency on the central server, which may affect training stability if the server malfunctions or connections are unstable. To address these issues, we propose a decentralized federated learning framework named dFLMoE. In our framework, clients directly exchange lightweight head models with each other. After exchanging, each client treats both local and received head models as individual experts, and utilizes a client-specific Mixture of Experts (MoE) approach to make collective decisions. This design not only reduces the knowledge damage with client-specific aggregations but also removes the dependency on the central server to enhance the robustness of the framework. We validate our framework on multiple medical tasks, demonstrating that our method evidently outperforms state-of-the-art approaches under both model homogeneity and heterogeneity settings.
Neural Finite-State Machines for Surgical Phase Recognition
Nov 27, 2024


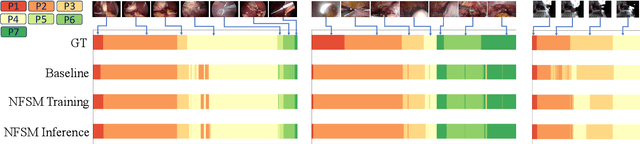
Surgical phase recognition is essential for analyzing procedure-specific surgical videos. While recent transformer-based architectures have advanced sequence processing capabilities, they struggle with maintaining consistency across lengthy surgical procedures. Drawing inspiration from classical hidden Markov models' finite-state interpretations, we introduce the neural finite-state machine (NFSM) module, which bridges procedural understanding with deep learning approaches. NFSM combines procedure-level understanding with neural networks through global state embeddings, attention-based dynamic transition tables, and transition-aware training and inference mechanisms for offline and online applications. When integrated into our future-aware architecture, NFSM improves video-level accuracy, phase-level precision, recall, and Jaccard indices on Cholec80 datasets by 2.3, 3.2, 3.0, and 4.8 percentage points respectively. As an add-on module to existing state-of-the-art models like Surgformer, NFSM further enhances performance, demonstrating its complementary value. Extended experiments on non-surgical datasets validate NFSM's generalizability beyond surgical domains. Comprehensive experiments demonstrate that incorporating NSFM into deep learning frameworks enables more robust and consistent phase recognition across long procedural videos.
DaRePlane: Direction-aware Representations for Dynamic Scene Reconstruction
Oct 18, 2024Numerous recent approaches to modeling and re-rendering dynamic scenes leverage plane-based explicit representations, addressing slow training times associated with models like neural radiance fields (NeRF) and Gaussian splatting (GS). However, merely decomposing 4D dynamic scenes into multiple 2D plane-based representations is insufficient for high-fidelity re-rendering of scenes with complex motions. In response, we present DaRePlane, a novel direction-aware representation approach that captures scene dynamics from six different directions. This learned representation undergoes an inverse dual-tree complex wavelet transformation (DTCWT) to recover plane-based information. Within NeRF pipelines, DaRePlane computes features for each space-time point by fusing vectors from these recovered planes, then passed to a tiny MLP for color regression. When applied to Gaussian splatting, DaRePlane computes the features of Gaussian points, followed by a tiny multi-head MLP for spatial-time deformation prediction. Notably, to address redundancy introduced by the six real and six imaginary direction-aware wavelet coefficients, we introduce a trainable masking approach, mitigating storage issues without significant performance decline. To demonstrate the generality and efficiency of DaRePlane, we test it on both regular and surgical dynamic scenes, for both NeRF and GS systems. Extensive experiments show that DaRePlane yields state-of-the-art performance in novel view synthesis for various complex dynamic scenes.
Divide and Fuse: Body Part Mesh Recovery from Partially Visible Human Images
Jul 12, 2024



We introduce a novel bottom-up approach for human body mesh reconstruction, specifically designed to address the challenges posed by partial visibility and occlusion in input images. Traditional top-down methods, relying on whole-body parametric models like SMPL, falter when only a small part of the human is visible, as they require visibility of most of the human body for accurate mesh reconstruction. To overcome this limitation, our method employs a "Divide and Fuse (D&F)" strategy, reconstructing human body parts independently before fusing them, thereby ensuring robustness against occlusions. We design Human Part Parametric Models (HPPM) that independently reconstruct the mesh from a few shape and global-location parameters, without inter-part dependency. A specially designed fusion module then seamlessly integrates the reconstructed parts, even when only a few are visible. We harness a large volume of ground-truth SMPL data to train our parametric mesh models. To facilitate the training and evaluation of our method, we have established benchmark datasets featuring images of partially visible humans with HPPM annotations. Our experiments, conducted on these benchmark datasets, demonstrate the effectiveness of our D&F method, particularly in scenarios with substantial invisibility, where traditional approaches struggle to maintain reconstruction quality.
AnatoMask: Enhancing Medical Image Segmentation with Reconstruction-guided Self-masking
Jul 09, 2024Due to the scarcity of labeled data, self-supervised learning (SSL) has gained much attention in 3D medical image segmentation, by extracting semantic representations from unlabeled data. Among SSL strategies, Masked image modeling (MIM) has shown effectiveness by reconstructing randomly masked images to learn detailed representations. However, conventional MIM methods require extensive training data to achieve good performance, which still poses a challenge for medical imaging. Since random masking uniformly samples all regions within medical images, it may overlook crucial anatomical regions and thus degrade the pretraining efficiency. We propose AnatoMask, a novel MIM method that leverages reconstruction loss to dynamically identify and mask out anatomically significant regions to improve pretraining efficacy. AnatoMask takes a self-distillation approach, where the model learns both how to find more significant regions to mask and how to reconstruct these masked regions. To avoid suboptimal learning, Anatomask adjusts the pretraining difficulty progressively using a masking dynamics function. We have evaluated our method on 4 public datasets with multiple imaging modalities (CT, MRI, and PET). AnatoMask demonstrates superior performance and scalability compared to existing SSL methods. The code is available at https://github.com/ricklisz/AnatoMask.
pFLFE: Cross-silo Personalized Federated Learning via Feature Enhancement on Medical Image Segmentation
Jun 29, 2024



In medical image segmentation, personalized cross-silo federated learning (FL) is becoming popular for utilizing varied data across healthcare settings to overcome data scarcity and privacy concerns. However, existing methods often suffer from client drift, leading to inconsistent performance and delayed training. We propose a new framework, Personalized Federated Learning via Feature Enhancement (pFLFE), designed to mitigate these challenges. pFLFE consists of two main stages: feature enhancement and supervised learning. The first stage improves differentiation between foreground and background features, and the second uses these enhanced features for learning from segmentation masks. We also design an alternative training approach that requires fewer communication rounds without compromising segmentation quality, even with limited communication resources. Through experiments on three medical segmentation tasks, we demonstrate that pFLFE outperforms the state-of-the-art methods.
MH-pFLGB: Model Heterogeneous personalized Federated Learning via Global Bypass for Medical Image Analysis
Jun 29, 2024In the evolving application of medical artificial intelligence, federated learning is notable for its ability to protect training data privacy. Federated learning facilitates collaborative model development without the need to share local data from healthcare institutions. Yet, the statistical and system heterogeneity among these institutions poses substantial challenges, which affects the effectiveness of federated learning and hampers the exchange of information between clients. To address these issues, we introduce a novel approach, MH-pFLGB, which employs a global bypass strategy to mitigate the reliance on public datasets and navigate the complexities of non-IID data distributions. Our method enhances traditional federated learning by integrating a global bypass model, which would share the information among the clients, but also serves as part of the network to enhance the performance on each client. Additionally, MH-pFLGB provides a feature fusion module to better combine the local and global features. We validate \model{}'s effectiveness and adaptability through extensive testing on different medical tasks, demonstrating superior performance compared to existing state-of-the-art methods.
MH-pFLID: Model Heterogeneous personalized Federated Learning via Injection and Distillation for Medical Data Analysis
May 10, 2024



Federated learning is widely used in medical applications for training global models without needing local data access. However, varying computational capabilities and network architectures (system heterogeneity), across clients pose significant challenges in effectively aggregating information from non-independently and identically distributed (non-IID) data. Current federated learning methods using knowledge distillation require public datasets, raising privacy and data collection issues. Additionally, these datasets require additional local computing and storage resources, which is a burden for medical institutions with limited hardware conditions. In this paper, we introduce a novel federated learning paradigm, named Model Heterogeneous personalized Federated Learning via Injection and Distillation (MH-pFLID). Our framework leverages a lightweight messenger model that carries concentrated information to collect the information from each client. We also develop a set of receiver and transmitter modules to receive and send information from the messenger model, so that the information could be injected and distilled with efficiency.
FSC: Few-point Shape Completion
Mar 13, 2024
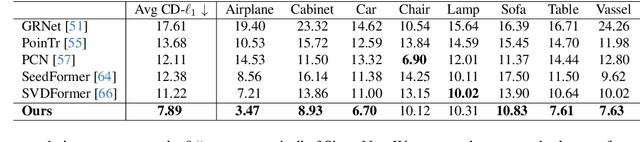

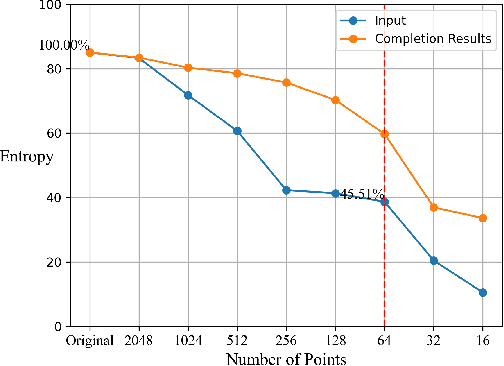
While previous studies have demonstrated successful 3D object shape completion with a sufficient number of points, they often fail in scenarios when a few points, e.g. tens of points, are observed. Surprisingly, via entropy analysis, we find that even a few points, e.g. 64 points, could retain substantial information to help recover the 3D shape of the object. To address the challenge of shape completion with very sparse point clouds, we then propose Few-point Shape Completion (FSC) model, which contains a novel dual-branch feature extractor for handling extremely sparse inputs, coupled with an extensive branch for maximal point utilization with a saliency branch for dynamic importance assignment. This model is further bolstered by a two-stage revision network that refines both the extracted features and the decoder output, enhancing the detail and authenticity of the completed point cloud. Our experiments demonstrate the feasibility of recovering 3D shapes from a few points. The proposed Few-point Shape Completion (FSC) model outperforms previous methods on both few-point inputs and many-point inputs, and shows good generalizability to different object categories.