 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEchoVLM: Measurement-Grounded Multimodal Learning for Echocardiography
Dec 13, 2025Echocardiography is the most widely used imaging modality in cardiology, yet its interpretation remains labor-intensive and inherently multimodal, requiring view recognition, quantitative measurements, qualitative assessments, and guideline-based reasoning. While recent vision-language models (VLMs) have achieved broad success in natural images and certain medical domains, their potential in echocardiography has been limited by the lack of large-scale, clinically grounded image-text datasets and the absence of measurement-based reasoning central to echo interpretation. We introduce EchoGround-MIMIC, the first measurement-grounded multimodal echocardiography dataset, comprising 19,065 image-text pairs from 1,572 patients with standardized views, structured measurements, measurement-grounded captions, and guideline-derived disease labels. Building on this resource, we propose EchoVLM, a vision-language model that incorporates two novel pretraining objectives: (i) a view-informed contrastive loss that encodes the view-dependent structure of echocardiographic imaging, and (ii) a negation-aware contrastive loss that distinguishes clinically critical negative from positive findings. Across five types of clinical applications with 36 tasks spanning multimodal disease classification, image-text retrieval, view classification, chamber segmentation, and landmark detection, EchoVLM achieves state-of-the-art performance (86.5% AUC in zero-shot disease classification and 95.1% accuracy in view classification). We demonstrate that clinically grounded multimodal pretraining yields transferable visual representations and establish EchoVLM as a foundation model for end-to-end echocardiography interpretation. We will release EchoGround-MIMIC and the data curation code, enabling reproducibility and further research in multimodal echocardiography interpretation.
Group Diffusion: Enhancing Image Generation by Unlocking Cross-Sample Collaboration
Dec 11, 2025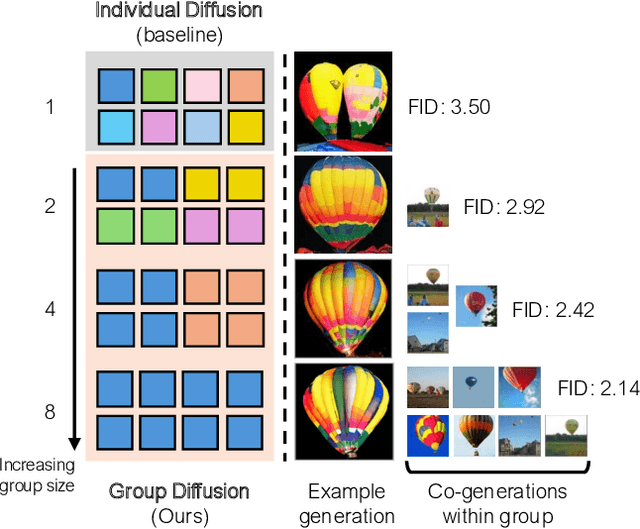
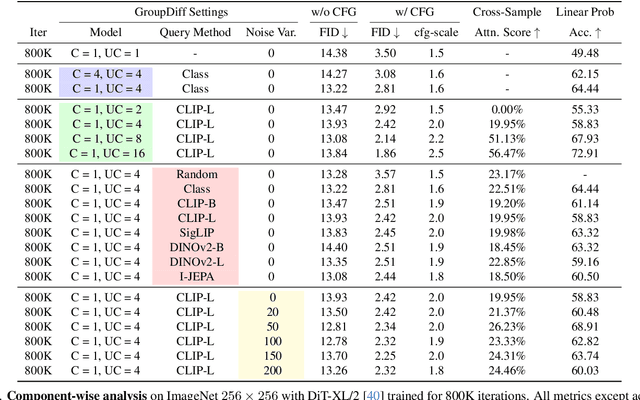

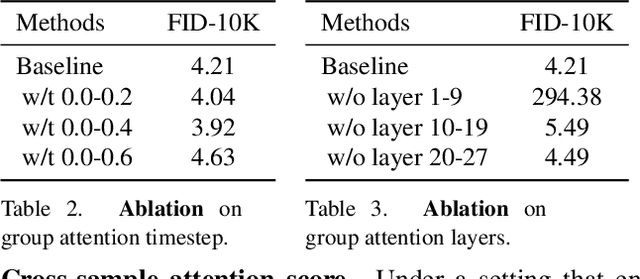
In this work, we explore an untapped signal in diffusion model inference. While all previous methods generate images independently at inference, we instead ask if samples can be generated collaboratively. We propose Group Diffusion, unlocking the attention mechanism to be shared across images, rather than limited to just the patches within an image. This enables images to be jointly denoised at inference time, learning both intra and inter-image correspondence. We observe a clear scaling effect - larger group sizes yield stronger cross-sample attention and better generation quality. Furthermore, we introduce a qualitative measure to capture this behavior and show that its strength closely correlates with FID. Built on standard diffusion transformers, our GroupDiff achieves up to 32.2% FID improvement on ImageNet-256x256. Our work reveals cross-sample inference as an effective, previously unexplored mechanism for generative modeling.
Relational Visual Similarity
Dec 08, 2025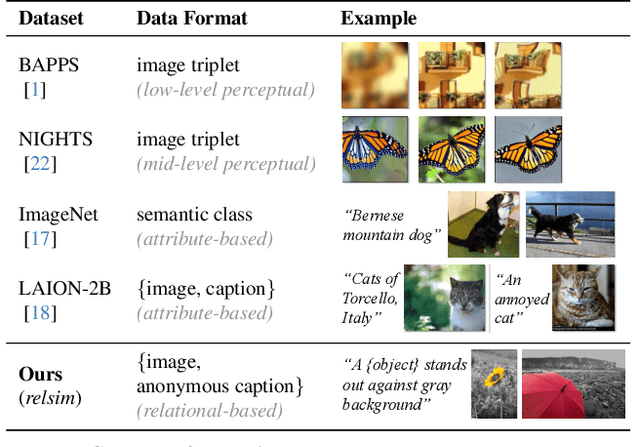
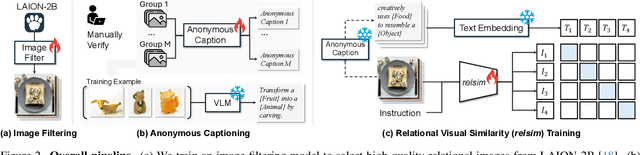
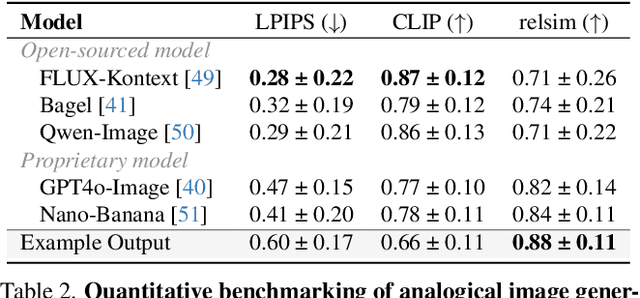

Humans do not just see attribute similarity -- we also see relational similarity. An apple is like a peach because both are reddish fruit, but the Earth is also like a peach: its crust, mantle, and core correspond to the peach's skin, flesh, and pit. This ability to perceive and recognize relational similarity, is arguable by cognitive scientist to be what distinguishes humans from other species. Yet, all widely used visual similarity metrics today (e.g., LPIPS, CLIP, DINO) focus solely on perceptual attribute similarity and fail to capture the rich, often surprising relational similarities that humans perceive. How can we go beyond the visible content of an image to capture its relational properties? How can we bring images with the same relational logic closer together in representation space? To answer these questions, we first formulate relational image similarity as a measurable problem: two images are relationally similar when their internal relations or functions among visual elements correspond, even if their visual attributes differ. We then curate 114k image-caption dataset in which the captions are anonymized -- describing the underlying relational logic of the scene rather than its surface content. Using this dataset, we finetune a Vision-Language model to measure the relational similarity between images. This model serves as the first step toward connecting images by their underlying relational structure rather than their visible appearance. Our study shows that while relational similarity has a lot of real-world applications, existing image similarity models fail to capture it -- revealing a critical gap in visual computing.
Learning an Image Editing Model without Image Editing Pairs
Oct 16, 2025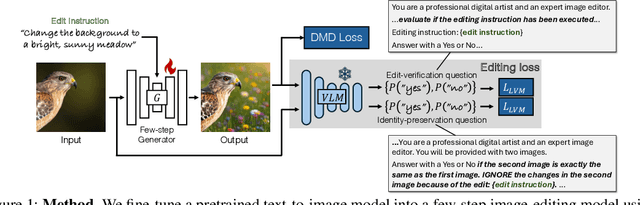
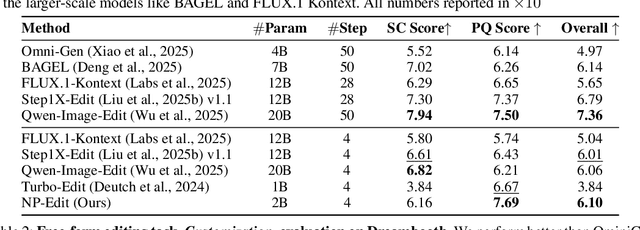

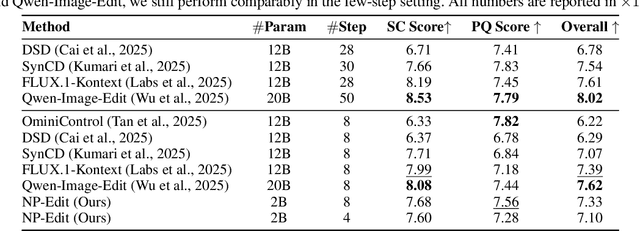
Recent image editing models have achieved impressive results while following natural language editing instructions, but they rely on supervised fine-tuning with large datasets of input-target pairs. This is a critical bottleneck, as such naturally occurring pairs are hard to curate at scale. Current workarounds use synthetic training pairs that leverage the zero-shot capabilities of existing models. However, this can propagate and magnify the artifacts of the pretrained model into the final trained model. In this work, we present a new training paradigm that eliminates the need for paired data entirely. Our approach directly optimizes a few-step diffusion model by unrolling it during training and leveraging feedback from vision-language models (VLMs). For each input and editing instruction, the VLM evaluates if an edit follows the instruction and preserves unchanged content, providing direct gradients for end-to-end optimization. To ensure visual fidelity, we incorporate distribution matching loss (DMD), which constrains generated images to remain within the image manifold learned by pretrained models. We evaluate our method on standard benchmarks and include an extensive ablation study. Without any paired data, our method performs on par with various image editing diffusion models trained on extensive supervised paired data, under the few-step setting. Given the same VLM as the reward model, we also outperform RL-based techniques like Flow-GRPO.
FT-MDT: Extracting Decision Trees from Medical Texts via a Novel Low-rank Adaptation Method
Oct 06, 2025Knowledge of the medical decision process, which can be modeled as medical decision trees (MDTs), is critical to building clinical decision support systems. However, current MDT construction methods rely heavily on time-consuming and laborious manual annotation. To address this challenge, we propose PI-LoRA (Path-Integrated LoRA), a novel low-rank adaptation method for automatically extracting MDTs from clinical guidelines and textbooks. We integrate gradient path information to capture synergistic effects between different modules, enabling more effective and reliable rank allocation. This framework ensures that the most critical modules receive appropriate rank allocations while less important ones are pruned, resulting in a more efficient and accurate model for extracting medical decision trees from clinical texts. Extensive experiments on medical guideline datasets demonstrate that our PI-LoRA method significantly outperforms existing parameter-efficient fine-tuning approaches for the Text2MDT task, achieving better accuracy with substantially reduced model complexity. The proposed method achieves state-of-the-art results while maintaining a lightweight architecture, making it particularly suitable for clinical decision support systems where computational resources may be limited.
AMAS: Adaptively Determining Communication Topology for LLM-based Multi-Agent System
Oct 02, 2025Although large language models (LLMs) have revolutionized natural language processing capabilities, their practical implementation as autonomous multi-agent systems (MAS) for industrial problem-solving encounters persistent barriers. Conventional MAS architectures are fundamentally restricted by inflexible, hand-crafted graph topologies that lack contextual responsiveness, resulting in diminished efficacy across varied academic and commercial workloads. To surmount these constraints, we introduce AMAS, a paradigm-shifting framework that redefines LLM-based MAS through a novel dynamic graph designer. This component autonomously identifies task-specific optimal graph configurations via lightweight LLM adaptation, eliminating the reliance on monolithic, universally applied structural templates. Instead, AMAS exploits the intrinsic properties of individual inputs to intelligently direct query trajectories through task-optimized agent pathways. Rigorous validation across question answering, mathematical deduction, and code generation benchmarks confirms that AMAS systematically exceeds state-of-the-art single-agent and multi-agent approaches across diverse LLM architectures. Our investigation establishes that context-sensitive structural adaptability constitutes a foundational requirement for high-performance LLM MAS deployments.
MedVista3D: Vision-Language Modeling for Reducing Diagnostic Errors in 3D CT Disease Detection, Understanding and Reporting
Sep 04, 2025Radiologic diagnostic errors-under-reading errors, inattentional blindness, and communication failures-remain prevalent in clinical practice. These issues often stem from missed localized abnormalities, limited global context, and variability in report language. These challenges are amplified in 3D imaging, where clinicians must examine hundreds of slices per scan. Addressing them requires systems with precise localized detection, global volume-level reasoning, and semantically consistent natural language reporting. However, existing 3D vision-language models are unable to meet all three needs jointly, lacking local-global understanding for spatial reasoning and struggling with the variability and noise of uncurated radiology reports. We present MedVista3D, a multi-scale semantic-enriched vision-language pretraining framework for 3D CT analysis. To enable joint disease detection and holistic interpretation, MedVista3D performs local and global image-text alignment for fine-grained representation learning within full-volume context. To address report variability, we apply language model rewrites and introduce a Radiology Semantic Matching Bank for semantics-aware alignment. MedVista3D achieves state-of-the-art performance on zero-shot disease classification, report retrieval, and medical visual question answering, while transferring well to organ segmentation and prognosis prediction. Code and datasets will be released.
Enhancing Large Multimodal Models with Adaptive Sparsity and KV Cache Compression
Jul 28, 2025Large multimodal models (LMMs) have advanced significantly by integrating visual encoders with extensive language models, enabling robust reasoning capabilities. However, compressing LMMs for deployment on edge devices remains a critical challenge. In this work, we propose an adaptive search algorithm that optimizes sparsity and KV cache compression to enhance LMM efficiency. Utilizing the Tree-structured Parzen Estimator, our method dynamically adjusts pruning ratios and KV cache quantization bandwidth across different LMM layers, using model performance as the optimization objective. This approach uniquely combines pruning with key-value cache quantization and incorporates a fast pruning technique that eliminates the need for additional fine-tuning or weight adjustments, achieving efficient compression without compromising accuracy. Comprehensive evaluations on benchmark datasets, including LLaVA-1.5 7B and 13B, demonstrate our method superiority over state-of-the-art techniques such as SparseGPT and Wanda across various compression levels. Notably, our framework automatic allocation of KV cache compression resources sets a new standard in LMM optimization, delivering memory efficiency without sacrificing much performance.
X-Fusion: Introducing New Modality to Frozen Large Language Models
Apr 29, 2025We propose X-Fusion, a framework that extends pretrained Large Language Models (LLMs) for multimodal tasks while preserving their language capabilities. X-Fusion employs a dual-tower design with modality-specific weights, keeping the LLM's parameters frozen while integrating vision-specific information for both understanding and generation. Our experiments demonstrate that X-Fusion consistently outperforms alternative architectures on both image-to-text and text-to-image tasks. We find that incorporating understanding-focused data improves generation quality, reducing image data noise enhances overall performance, and feature alignment accelerates convergence for smaller models but has minimal impact on larger ones. Our findings provide valuable insights into building efficient unified multimodal models.
YoChameleon: Personalized Vision and Language Generation
Apr 29, 2025Large Multimodal Models (e.g., GPT-4, Gemini, Chameleon) have evolved into powerful tools with millions of users. However, they remain generic models and lack personalized knowledge of specific user concepts. Previous work has explored personalization for text generation, yet it remains unclear how these methods can be adapted to new modalities, such as image generation. In this paper, we introduce Yo'Chameleon, the first attempt to study personalization for large multimodal models. Given 3-5 images of a particular concept, Yo'Chameleon leverages soft-prompt tuning to embed subject-specific information to (i) answer questions about the subject and (ii) recreate pixel-level details to produce images of the subject in new contexts. Yo'Chameleon is trained with (i) a self-prompting optimization mechanism to balance performance across multiple modalities, and (ii) a ``soft-positive" image generation approach to enhance image quality in a few-shot setting.