 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTRIZ-RAGNER: A Retrieval-Augmented Large Language Model for TRIZ-Aware Named Entity Recognition in Patent-Based Contradiction Mining
Feb 27, 2026TRIZ-based contradiction mining is a fundamental task in patent analysis and systematic innovation, as it enables the identification of improving and worsening technical parameters that drive inventive problem solving. However, existing approaches largely rely on rule-based systems or traditional machine learning models, which struggle with semantic ambiguity, domain dependency, and limited generalization when processing complex patent language. Recently, large language models (LLMs) have shown strong semantic understanding capabilities, yet their direct application to TRIZ parameter extraction remains challenging due to hallucination and insufficient grounding in structured TRIZ knowledge. To address these limitations, this paper proposes TRIZ-RAGNER, a retrieval-augmented large language model framework for TRIZ-aware named entity recognition in patent-based contradiction mining. TRIZ-RAGNER reformulates contradiction mining as a semantic-level NER task and integrates dense retrieval over a TRIZ knowledge base, cross-encoder reranking for context refinement, and structured LLM prompting to extract improving and worsening parameters from patent sentences. By injecting domain-specific TRIZ knowledge into the LLM reasoning process, the proposed framework effectively reduces semantic noise and improves extraction consistency. Experiments on the PaTRIZ dataset demonstrate that TRIZ-RAGNER consistently outperforms traditional sequence labeling models and LLM-based baselines. The proposed framework achieves a precision of 85.6%, a recall of 82.9%, and an F1-score of 84.2% in TRIZ contradiction pair identification. Compared with the strongest baseline using prompt-enhanced GPT, TRIZ-RAGNER yields an absolute F1-score improvement of 7.3 percentage points, confirming the effectiveness of retrieval-augmented TRIZ knowledge grounding for robust and accurate patent-based contradiction mining.
AMAS: Adaptively Determining Communication Topology for LLM-based Multi-Agent System
Oct 02, 2025Although large language models (LLMs) have revolutionized natural language processing capabilities, their practical implementation as autonomous multi-agent systems (MAS) for industrial problem-solving encounters persistent barriers. Conventional MAS architectures are fundamentally restricted by inflexible, hand-crafted graph topologies that lack contextual responsiveness, resulting in diminished efficacy across varied academic and commercial workloads. To surmount these constraints, we introduce AMAS, a paradigm-shifting framework that redefines LLM-based MAS through a novel dynamic graph designer. This component autonomously identifies task-specific optimal graph configurations via lightweight LLM adaptation, eliminating the reliance on monolithic, universally applied structural templates. Instead, AMAS exploits the intrinsic properties of individual inputs to intelligently direct query trajectories through task-optimized agent pathways. Rigorous validation across question answering, mathematical deduction, and code generation benchmarks confirms that AMAS systematically exceeds state-of-the-art single-agent and multi-agent approaches across diverse LLM architectures. Our investigation establishes that context-sensitive structural adaptability constitutes a foundational requirement for high-performance LLM MAS deployments.
Multi-Scale Target-Aware Representation Learning for Fundus Image Enhancement
May 03, 2025High-quality fundus images provide essential anatomical information for clinical screening and ophthalmic disease diagnosis. Yet, due to hardware limitations, operational variability, and patient compliance, fundus images often suffer from low resolution and signal-to-noise ratio. Recent years have witnessed promising progress in fundus image enhancement. However, existing works usually focus on restoring structural details or global characteristics of fundus images, lacking a unified image enhancement framework to recover comprehensive multi-scale information. Moreover, few methods pinpoint the target of image enhancement, e.g., lesions, which is crucial for medical image-based diagnosis. To address these challenges, we propose a multi-scale target-aware representation learning framework (MTRL-FIE) for efficient fundus image enhancement. Specifically, we propose a multi-scale feature encoder (MFE) that employs wavelet decomposition to embed both low-frequency structural information and high-frequency details. Next, we design a structure-preserving hierarchical decoder (SHD) to fuse multi-scale feature embeddings for real fundus image restoration. SHD integrates hierarchical fusion and group attention mechanisms to achieve adaptive feature fusion while retaining local structural smoothness. Meanwhile, a target-aware feature aggregation (TFA) module is used to enhance pathological regions and reduce artifacts. Experimental results on multiple fundus image datasets demonstrate the effectiveness and generalizability of MTRL-FIE for fundus image enhancement. Compared to state-of-the-art methods, MTRL-FIE achieves superior enhancement performance with a more lightweight architecture. Furthermore, our approach generalizes to other ophthalmic image processing tasks without supervised fine-tuning, highlighting its potential for clinical applications.
Robust Detection of LLM-Generated Text: A Comparative Analysis
Nov 09, 2024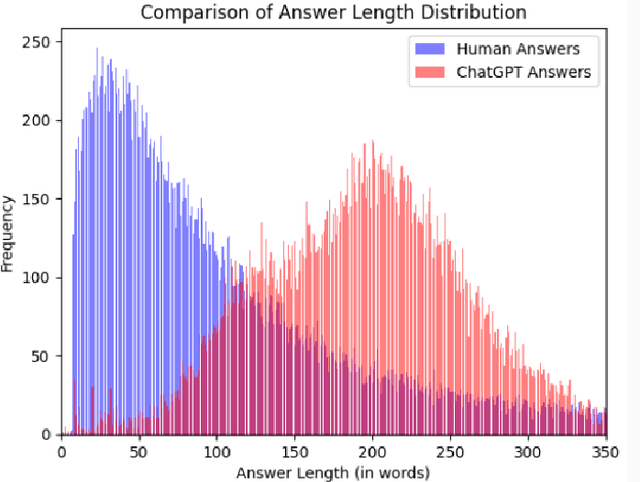
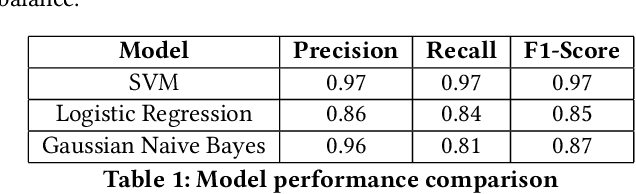
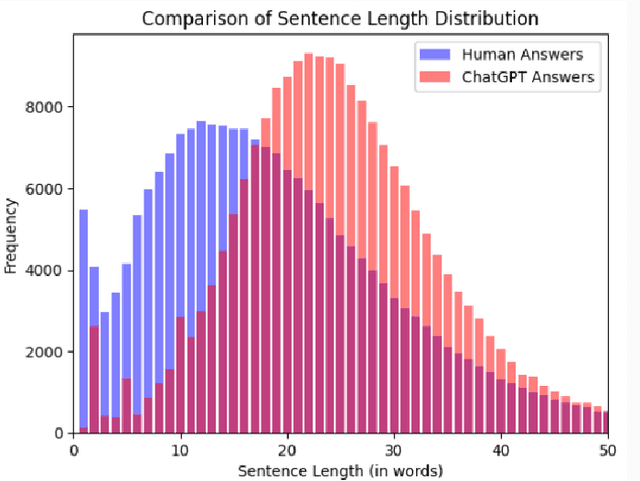
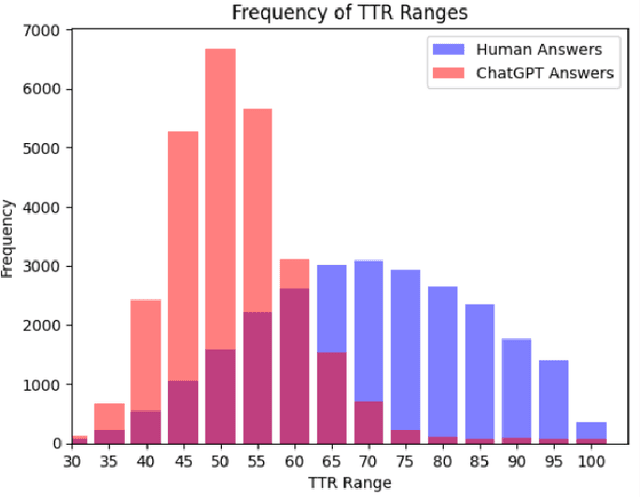
The ability of large language models to generate complex texts allows them to be widely integrated into many aspects of life, and their output can quickly fill all network resources. As the impact of LLMs grows, it becomes increasingly important to develop powerful detectors for the generated text. This detector is essential to prevent the potential misuse of these technologies and to protect areas such as social media from the negative effects of false content generated by LLMS. The main goal of LLM-generated text detection is to determine whether text is generated by an LLM, which is a basic binary classification task. In our work, we mainly use three different classification methods based on open source datasets: traditional machine learning techniques such as logistic regression, k-means clustering, Gaussian Naive Bayes, support vector machines, and methods based on converters such as BERT, and finally algorithms that use LLMs to detect LLM-generated text. We focus on model generalization, potential adversarial attacks, and accuracy of model evaluation. Finally, the possible research direction in the future is proposed, and the current experimental results are summarized.
Combining Induction and Transduction for Abstract Reasoning
Nov 04, 2024When learning an input-output mapping from very few examples, is it better to first infer a latent function that explains the examples, or is it better to directly predict new test outputs, e.g. using a neural network? We study this question on ARC, a highly diverse dataset of abstract reasoning tasks. We train neural models for induction (inferring latent functions) and transduction (directly predicting the test output for a given test input). Our models are trained on synthetic data generated by prompting LLMs to produce Python code specifying a function to be inferred, plus a stochastic subroutine for generating inputs to that function. We find inductive and transductive models solve very different problems, despite training on the same problems, and despite sharing the same neural architecture.