 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRepresentation Geometry as a Diagnostic for Out-of-Distribution Robustness
Feb 05, 2026Robust generalization under distribution shift remains difficult to monitor and optimize in the absence of target-domain labels, as models with similar in-distribution accuracy can exhibit markedly different out-of-distribution (OOD) performance. While prior work has focused on training-time regularization and low-order representation statistics, little is known about whether the geometric structure of learned embeddings provides reliable post-hoc signals of robustness. We propose a geometry-based diagnostic framework that constructs class-conditional mutual k-nearest-neighbor graphs from in-distribution embeddings and extracts two complementary invariants: a global spectral complexity proxy based on the reduced log-determinant of the normalized Laplacian, and a local smoothness measure based on Ollivier--Ricci curvature. Across multiple architectures, training regimes, and corruption benchmarks, we find that lower spectral complexity and higher mean curvature consistently predict stronger OOD accuracy across checkpoints. Controlled perturbations and topological analyses further show that these signals reflect meaningful representation structure rather than superficial embedding statistics. Our results demonstrate that representation geometry enables interpretable, label-free robustness diagnosis and supports reliable unsupervised checkpoint selection under distribution shift.
Test-Time Adaptation for Anomaly Segmentation via Topology-Aware Optimal Transport Chaining
Jan 28, 2026Deep topological data analysis (TDA) offers a principled framework for capturing structural invariants such as connectivity and cycles that persist across scales, making it a natural fit for anomaly segmentation (AS). Unlike thresholdbased binarisation, which produces brittle masks under distribution shift, TDA allows anomalies to be characterised as disruptions to global structure rather than local fluctuations. We introduce TopoOT, a topology-aware optimal transport (OT) framework that integrates multi-filtration persistence diagrams (PDs) with test-time adaptation (TTA). Our key innovation is Optimal Transport Chaining, which sequentially aligns PDs across thresholds and filtrations, yielding geodesic stability scores that identify features consistently preserved across scales. These stabilityaware pseudo-labels supervise a lightweight head trained online with OT-consistency and contrastive objectives, ensuring robust adaptation under domain shift. Across standard 2D and 3D anomaly detection benchmarks, TopoOT achieves state-of-the-art performance, outperforming the most competitive methods by up to +24.1% mean F1 on 2D datasets and +10.2% on 3D AS benchmarks.
Multi-Scale Target-Aware Representation Learning for Fundus Image Enhancement
May 03, 2025High-quality fundus images provide essential anatomical information for clinical screening and ophthalmic disease diagnosis. Yet, due to hardware limitations, operational variability, and patient compliance, fundus images often suffer from low resolution and signal-to-noise ratio. Recent years have witnessed promising progress in fundus image enhancement. However, existing works usually focus on restoring structural details or global characteristics of fundus images, lacking a unified image enhancement framework to recover comprehensive multi-scale information. Moreover, few methods pinpoint the target of image enhancement, e.g., lesions, which is crucial for medical image-based diagnosis. To address these challenges, we propose a multi-scale target-aware representation learning framework (MTRL-FIE) for efficient fundus image enhancement. Specifically, we propose a multi-scale feature encoder (MFE) that employs wavelet decomposition to embed both low-frequency structural information and high-frequency details. Next, we design a structure-preserving hierarchical decoder (SHD) to fuse multi-scale feature embeddings for real fundus image restoration. SHD integrates hierarchical fusion and group attention mechanisms to achieve adaptive feature fusion while retaining local structural smoothness. Meanwhile, a target-aware feature aggregation (TFA) module is used to enhance pathological regions and reduce artifacts. Experimental results on multiple fundus image datasets demonstrate the effectiveness and generalizability of MTRL-FIE for fundus image enhancement. Compared to state-of-the-art methods, MTRL-FIE achieves superior enhancement performance with a more lightweight architecture. Furthermore, our approach generalizes to other ophthalmic image processing tasks without supervised fine-tuning, highlighting its potential for clinical applications.
Determining Mosaic Resilience in Sugarcane Plants using Hyperspectral Images
Jan 28, 2025Sugarcane mosaic disease poses a serious threat to the Australian sugarcane industry, leading to yield losses of up to 30% in susceptible varieties. Existing manual inspection methods for detecting mosaic resilience are inefficient and impractical for large-scale application. This study introduces a novel approach using hyperspectral imaging and machine learning to detect mosaic resilience by leveraging global feature representation from local spectral patches. Hyperspectral data were collected from eight sugarcane varieties under controlled and field conditions. Local spectral patches were analyzed to capture spatial and spectral variations, which were then aggregated into global feature representations using a ResNet18 deep learning architecture. While classical methods like Support Vector Machines struggled to utilize spatial-spectral relationships effectively, the deep learning model achieved high classification accuracy, demonstrating its capacity to identify mosaic resilience from fine-grained hyperspectral data. This approach enhances early detection capabilities, enabling more efficient management of susceptible strains and contributing to sustainable sugarcane production.
Locally-Focused Face Representation for Sketch-to-Image Generation Using Noise-Induced Refinement
Nov 28, 2024This paper presents a novel deep-learning framework that significantly enhances the transformation of rudimentary face sketches into high-fidelity colour images. Employing a Convolutional Block Attention-based Auto-encoder Network (CA2N), our approach effectively captures and enhances critical facial features through a block attention mechanism within an encoder-decoder architecture. Subsequently, the framework utilises a noise-induced conditional Generative Adversarial Network (cGAN) process that allows the system to maintain high performance even on domains unseen during the training. These enhancements lead to considerable improvements in image realism and fidelity, with our model achieving superior performance metrics that outperform the best method by FID margin of 17, 23, and 38 on CelebAMask-HQ, CUHK, and CUFSF datasets; respectively. The model sets a new state-of-the-art in sketch-to-image generation, can generalize across sketch types, and offers a robust solution for applications such as criminal identification in law enforcement.
NeFF-BioNet: Crop Biomass Prediction from Point Cloud to Drone Imagery
Oct 30, 2024Crop biomass offers crucial insights into plant health and yield, making it essential for crop science, farming systems, and agricultural research. However, current measurement methods, which are labor-intensive, destructive, and imprecise, hinder large-scale quantification of this trait. To address this limitation, we present a biomass prediction network (BioNet), designed for adaptation across different data modalities, including point clouds and drone imagery. Our BioNet, utilizing a sparse 3D convolutional neural network (CNN) and a transformer-based prediction module, processes point clouds and other 3D data representations to predict biomass. To further extend BioNet for drone imagery, we integrate a neural feature field (NeFF) module, enabling 3D structure reconstruction and the transformation of 2D semantic features from vision foundation models into the corresponding 3D surfaces. For the point cloud modality, BioNet demonstrates superior performance on two public datasets, with an approximate 6.1% relative improvement (RI) over the state-of-the-art. In the RGB image modality, the combination of BioNet and NeFF achieves a 7.9% RI. Additionally, the NeFF-based approach utilizes inexpensive, portable drone-mounted cameras, providing a scalable solution for large field applications.
Collaborative Static-Dynamic Teaching: A Semi-Supervised Framework for Stripe-Like Space Target Detection
Aug 09, 2024Stripe-like space target detection (SSTD) is crucial for space situational awareness. Traditional unsupervised methods often fail in low signal-to-noise ratio and variable stripe-like space targets scenarios, leading to weak generalization. Although fully supervised learning methods improve model generalization, they require extensive pixel-level labels for training. In the SSTD task, manually creating these labels is often inaccurate and labor-intensive. Semi-supervised learning (SSL) methods reduce the need for these labels and enhance model generalizability, but their performance is limited by pseudo-label quality. To address this, we introduce an innovative Collaborative Static-Dynamic Teacher (CSDT) SSL framework, which includes static and dynamic teacher models as well as a student model. This framework employs a customized adaptive pseudo-labeling (APL) strategy, transitioning from initial static teaching to adaptive collaborative teaching, guiding the student model's training. The exponential moving average (EMA) mechanism further enhances this process by feeding new stripe-like knowledge back to the dynamic teacher model through the student model, creating a positive feedback loop that continuously enhances the quality of pseudo-labels. Moreover, we present MSSA-Net, a novel SSTD network featuring a multi-scale dual-path convolution (MDPC) block and a feature map weighted attention (FMWA) block, designed to extract diverse stripe-like features within the CSDT SSL training framework. Extensive experiments verify the state-of-the-art performance of our framework on the AstroStripeSet and various ground-based and space-based real-world datasets.
SSTD: Stripe-Like Space Target Detection using Single-Point Supervision
Jul 25, 2024Stripe-like space target detection (SSTD) plays a key role in enhancing space situational awareness and assessing spacecraft behaviour. This domain faces three challenges: the lack of publicly available datasets, interference from stray light and stars, and the variability of stripe-like targets, which complicates pixel-level annotation. In response, we introduces `AstroStripeSet', a pioneering dataset designed for SSTD, aiming to bridge the gap in academic resources and advance research in SSTD. Furthermore, we propose a novel pseudo-label evolution teacher-student framework with single-point supervision. This framework starts with generating initial pseudo-labels using the zero-shot capabilities of the Segment Anything Model (SAM) in a single-point setting, and refines these labels iteratively. In our framework, the fine-tuned StripeSAM serves as the teacher and the newly developed StripeNet as the student, consistently improving segmentation performance by improving the quality of pseudo-labels. We also introduce `GeoDice', a new loss function customized for the linear characteristics of stripe-like targets. Extensive experiments show that the performance of our approach matches fully supervised methods on all evaluation metrics, establishing a new state-of-the-art (SOTA) benchmark. Our dataset and code will be made publicly available.
MMCBE: Multi-modality Dataset for Crop Biomass Estimation and Beyond
Apr 17, 2024Crop biomass, a critical indicator of plant growth, health, and productivity, is invaluable for crop breeding programs and agronomic research. However, the accurate and scalable quantification of crop biomass remains inaccessible due to limitations in existing measurement methods. One of the obstacles impeding the advancement of current crop biomass prediction methodologies is the scarcity of publicly available datasets. Addressing this gap, we introduce a new dataset in this domain, i.e. Multi-modality dataset for crop biomass estimation (MMCBE). Comprising 216 sets of multi-view drone images, coupled with LiDAR point clouds, and hand-labelled ground truth, MMCBE represents the first multi-modality one in the field. This dataset aims to establish benchmark methods for crop biomass quantification and foster the development of vision-based approaches. We have rigorously evaluated state-of-the-art crop biomass estimation methods using MMCBE and ventured into additional potential applications, such as 3D crop reconstruction from drone imagery and novel-view rendering. With this publication, we are making our comprehensive dataset available to the broader community.
TopoX: A Suite of Python Packages for Machine Learning on Topological Domains
Feb 07, 2024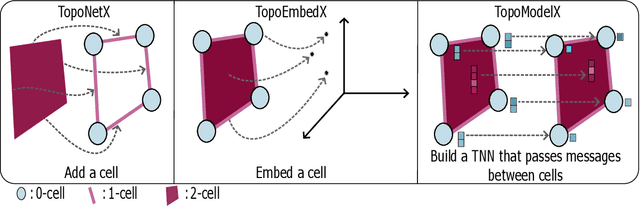
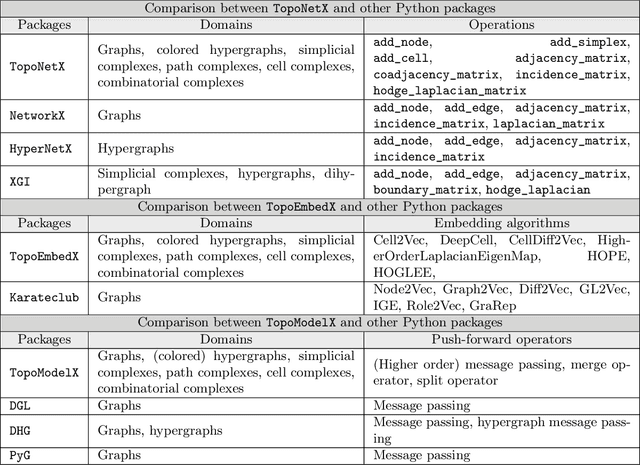
We introduce topox, a Python software suite that provides reliable and user-friendly building blocks for computing and machine learning on topological domains that extend graphs: hypergraphs, simplicial, cellular, path and combinatorial complexes. topox consists of three packages: toponetx facilitates constructing and computing on these domains, including working with nodes, edges and higher-order cells; topoembedx provides methods to embed topological domains into vector spaces, akin to popular graph-based embedding algorithms such as node2vec; topomodelx is built on top of PyTorch and offers a comprehensive toolbox of higher-order message passing functions for neural networks on topological domains. The extensively documented and unit-tested source code of topox is available under MIT license at https://github.com/pyt-team.