 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge-based anomaly detection for identifying network-induced shape artifacts
Nov 06, 2025Synthetic data provides a promising approach to address data scarcity for training machine learning models; however, adoption without proper quality assessments may introduce artifacts, distortions, and unrealistic features that compromise model performance and clinical utility. This work introduces a novel knowledge-based anomaly detection method for detecting network-induced shape artifacts in synthetic images. The introduced method utilizes a two-stage framework comprising (i) a novel feature extractor that constructs a specialized feature space by analyzing the per-image distribution of angle gradients along anatomical boundaries, and (ii) an isolation forest-based anomaly detector. We demonstrate the effectiveness of the method for identifying network-induced shape artifacts in two synthetic mammography datasets from models trained on CSAW-M and VinDr-Mammo patient datasets respectively. Quantitative evaluation shows that the method successfully concentrates artifacts in the most anomalous partition (1st percentile), with AUC values of 0.97 (CSAW-syn) and 0.91 (VMLO-syn). In addition, a reader study involving three imaging scientists confirmed that images identified by the method as containing network-induced shape artifacts were also flagged by human readers with mean agreement rates of 66% (CSAW-syn) and 68% (VMLO-syn) for the most anomalous partition, approximately 1.5-2 times higher than the least anomalous partition. Kendall-Tau correlations between algorithmic and human rankings were 0.45 and 0.43 for the two datasets, indicating reasonable agreement despite the challenging nature of subtle artifact detection. This method is a step forward in the responsible use of synthetic data, as it allows developers to evaluate synthetic images for known anatomic constraints and pinpoint and address specific issues to improve the overall quality of a synthetic dataset.
Scorecards for Synthetic Medical Data Evaluation and Reporting
Jun 17, 2024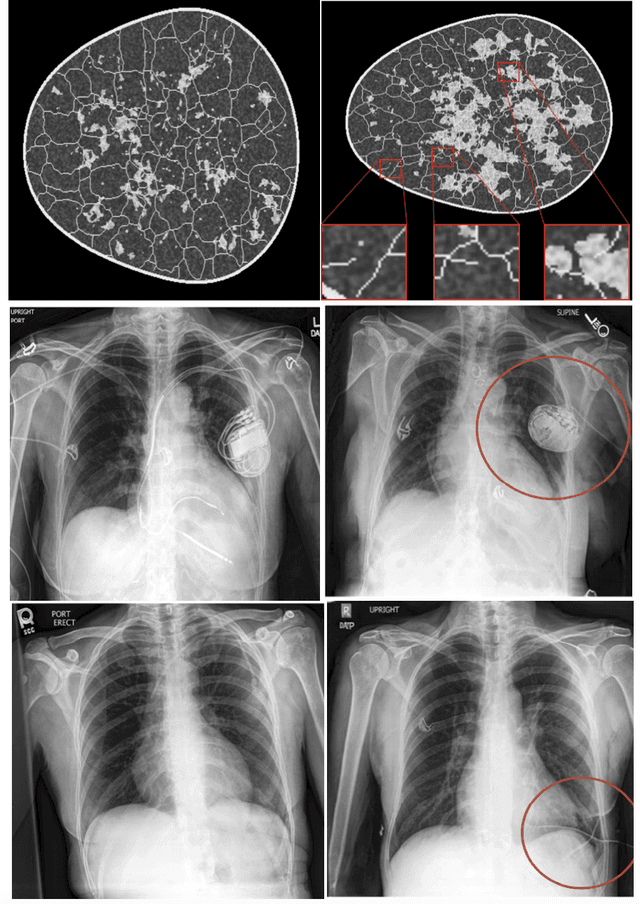
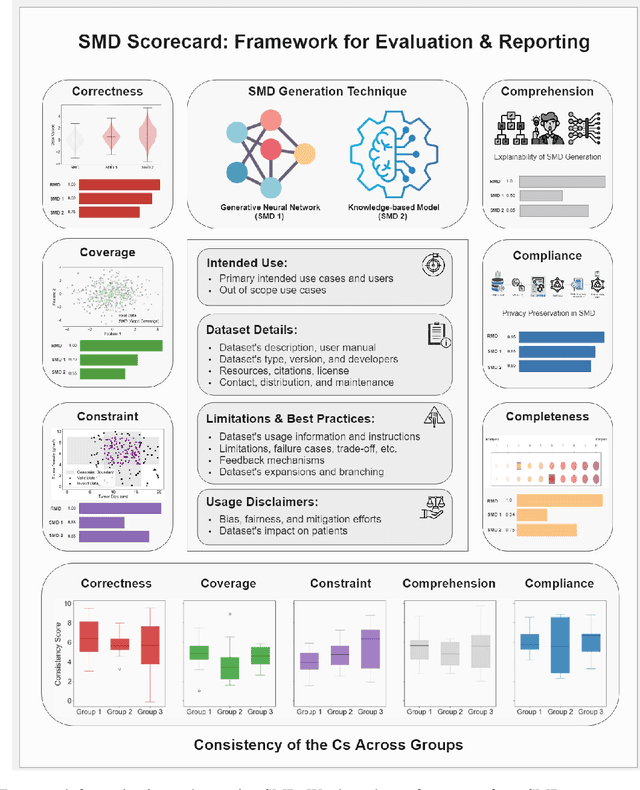
The growing utilization of synthetic medical data (SMD) in training and testing AI-driven tools in healthcare necessitates a systematic framework for assessing SMD quality. The current lack of a standardized methodology to evaluate SMD, particularly in terms of its applicability in various medical scenarios, is a significant hindrance to its broader acceptance and utilization in healthcare applications. Here, we outline an evaluation framework designed to meet the unique requirements of medical applications, and introduce the concept of SMD scorecards, which can serve as comprehensive reports that accompany artificially generated datasets. This can help standardize evaluation and enable SMD developers to assess and further enhance the quality of SMDs by identifying areas in need of attention and ensuring that the synthetic data more accurately approximate patient data.
TopoBenchmarkX: A Framework for Benchmarking Topological Deep Learning
Jun 09, 2024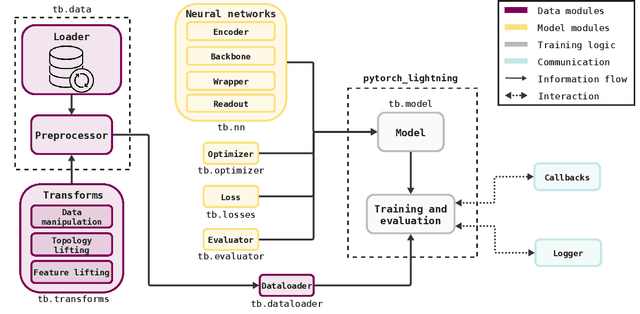
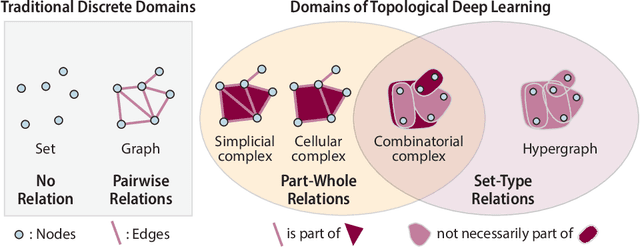
This work introduces TopoBenchmarkX, a modular open-source library designed to standardize benchmarking and accelerate research in Topological Deep Learning (TDL). TopoBenchmarkX maps the TDL pipeline into a sequence of independent and modular components for data loading and processing, as well as model training, optimization, and evaluation. This modular organization provides flexibility for modifications and facilitates the adaptation and optimization of various TDL pipelines. A key feature of TopoBenchmarkX is that it allows for the transformation and lifting between topological domains. This enables, for example, to obtain richer data representations and more fine-grained analyses by mapping the topology and features of a graph to higher-order topological domains such as simplicial and cell complexes. The range of applicability of TopoBenchmarkX is demonstrated by benchmarking several TDL architectures for various tasks and datasets.
Position Paper: Challenges and Opportunities in Topological Deep Learning
Feb 14, 2024
Topological deep learning (TDL) is a rapidly evolving field that uses topological features to understand and design deep learning models. This paper posits that TDL may complement graph representation learning and geometric deep learning by incorporating topological concepts, and can thus provide a natural choice for various machine learning settings. To this end, this paper discusses open problems in TDL, ranging from practical benefits to theoretical foundations. For each problem, it outlines potential solutions and future research opportunities. At the same time, this paper serves as an invitation to the scientific community to actively participate in TDL research to unlock the potential of this emerging field.
Out-of-Distribution Detection and Data Drift Monitoring using Statistical Process Control
Feb 12, 2024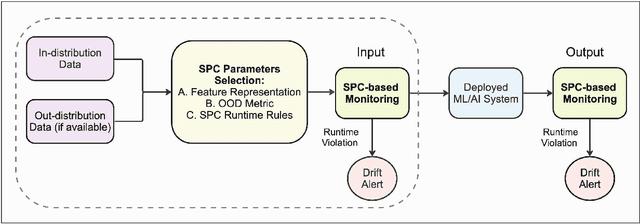

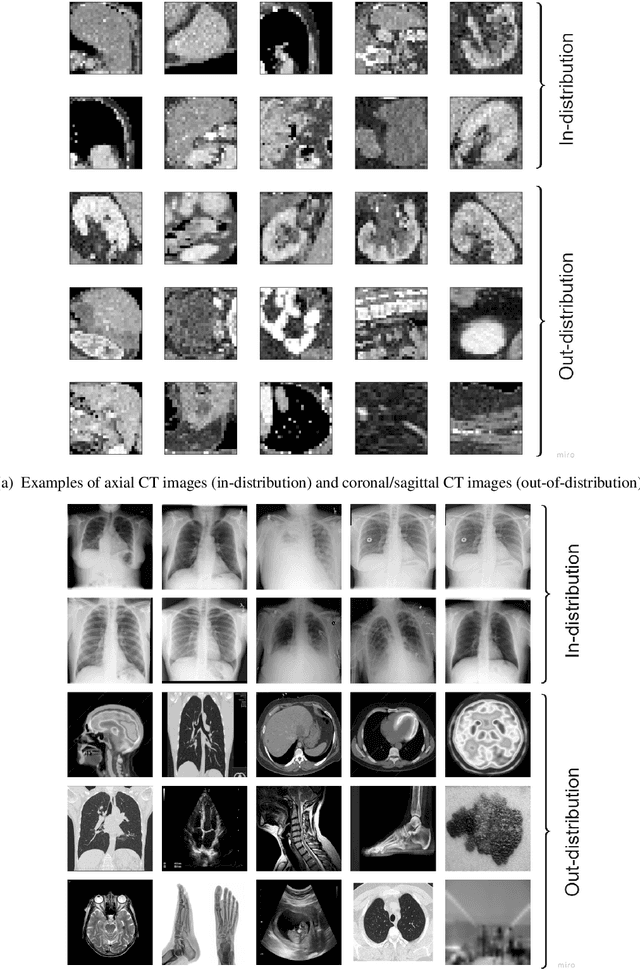

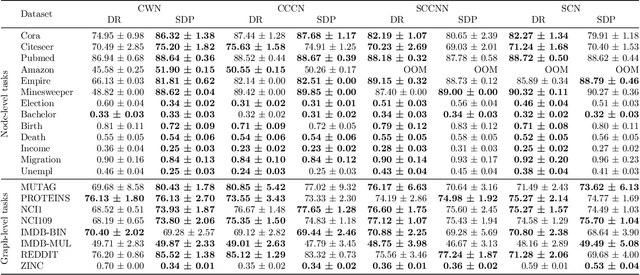
Background: Machine learning (ML) methods often fail with data that deviates from their training distribution. This is a significant concern for ML-enabled devices in clinical settings, where data drift may cause unexpected performance that jeopardizes patient safety. Method: We propose a ML-enabled Statistical Process Control (SPC) framework for out-of-distribution (OOD) detection and drift monitoring. SPC is advantageous as it visually and statistically highlights deviations from the expected distribution. To demonstrate the utility of the proposed framework for monitoring data drift in radiological images, we investigated different design choices, including methods for extracting feature representations, drift quantification, and SPC parameter selection. Results: We demonstrate the effectiveness of our framework for two tasks: 1) differentiating axial vs. non-axial computed tomography (CT) images and 2) separating chest x-ray (CXR) from other modalities. For both tasks, we achieved high accuracy in detecting OOD inputs, with 0.913 in CT and 0.995 in CXR, and sensitivity of 0.980 in CT and 0.984 in CXR. Our framework was also adept at monitoring data streams and identifying the time a drift occurred. In a simulation with 100 daily CXR cases, we detected a drift in OOD input percentage from 0-1% to 3-5% within two days, maintaining a low false-positive rate. Through additional experimental results, we demonstrate the framework's data-agnostic nature and independence from the underlying model's structure. Conclusion: We propose a framework for OOD detection and drift monitoring that is agnostic to data, modality, and model. The framework is customizable and can be adapted for specific applications.
TopoX: A Suite of Python Packages for Machine Learning on Topological Domains
Feb 07, 2024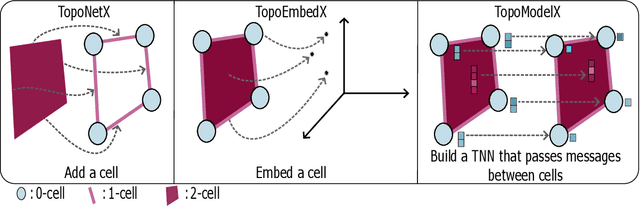
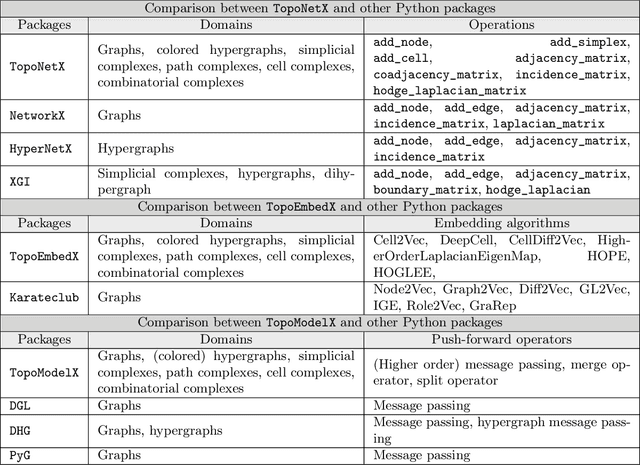
We introduce topox, a Python software suite that provides reliable and user-friendly building blocks for computing and machine learning on topological domains that extend graphs: hypergraphs, simplicial, cellular, path and combinatorial complexes. topox consists of three packages: toponetx facilitates constructing and computing on these domains, including working with nodes, edges and higher-order cells; topoembedx provides methods to embed topological domains into vector spaces, akin to popular graph-based embedding algorithms such as node2vec; topomodelx is built on top of PyTorch and offers a comprehensive toolbox of higher-order message passing functions for neural networks on topological domains. The extensively documented and unit-tested source code of topox is available under MIT license at https://github.com/pyt-team.
Combinatorial Complexes: Bridging the Gap Between Cell Complexes and Hypergraphs
Dec 15, 2023

Graph-based signal processing techniques have become essential for handling data in non-Euclidean spaces. However, there is a growing awareness that these graph models might need to be expanded into `higher-order' domains to effectively represent the complex relations found in high-dimensional data. Such higher-order domains are typically modeled either as hypergraphs, or as simplicial, cubical or other cell complexes. In this context, cell complexes are often seen as a subclass of hypergraphs with additional algebraic structure that can be exploited, e.g., to develop a spectral theory. In this article, we promote an alternative perspective. We argue that hypergraphs and cell complexes emphasize \emph{different} types of relations, which may have different utility depending on the application context. Whereas hypergraphs are effective in modeling set-type, multi-body relations between entities, cell complexes provide an effective means to model hierarchical, interior-to-boundary type relations. We discuss the relative advantages of these two choices and elaborate on the previously introduced concept of a combinatorial complex that enables co-existing set-type and hierarchical relations. Finally, we provide a brief numerical experiment to demonstrate that this modelling flexibility can be advantageous in learning tasks.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023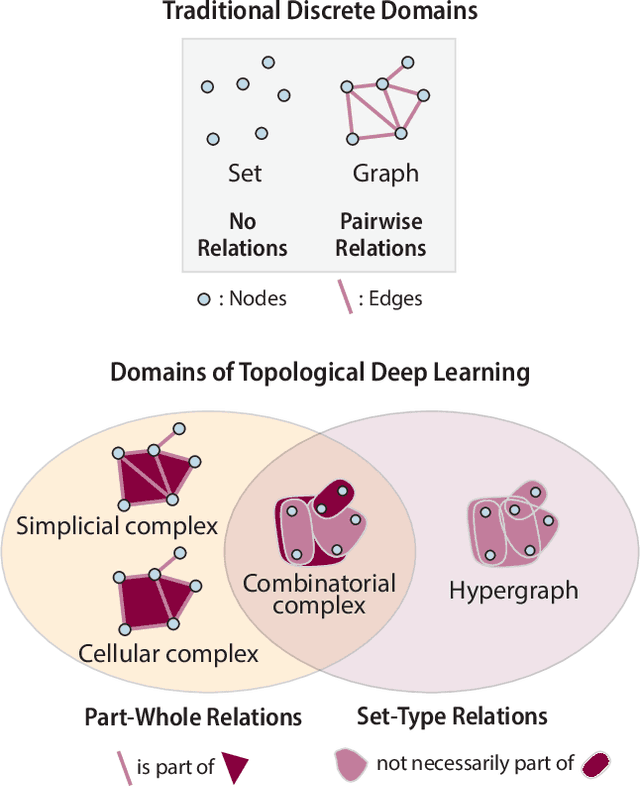
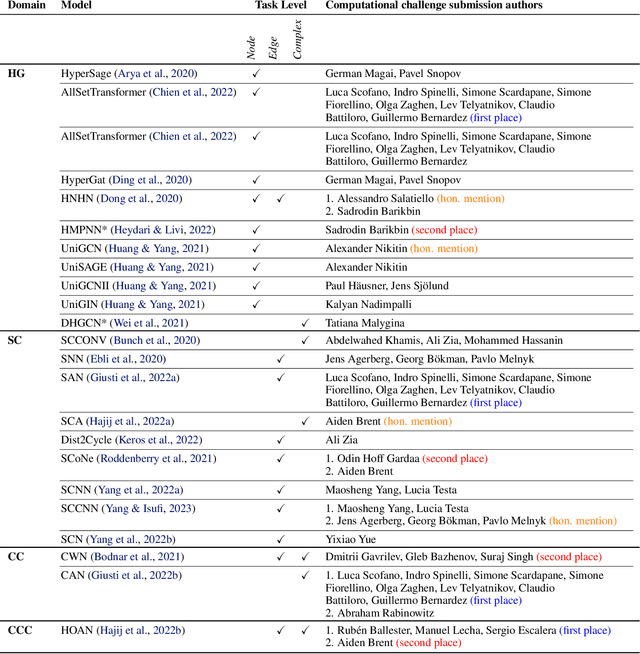
This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
Uncovering the effects of model initialization on deep model generalization: A study with adult and pediatric Chest X-ray images
Sep 20, 2023Model initialization techniques are vital for improving the performance and reliability of deep learning models in medical computer vision applications. While much literature exists on non-medical images, the impacts on medical images, particularly chest X-rays (CXRs) are less understood. Addressing this gap, our study explores three deep model initialization techniques: Cold-start, Warm-start, and Shrink and Perturb start, focusing on adult and pediatric populations. We specifically focus on scenarios with periodically arriving data for training, thereby embracing the real-world scenarios of ongoing data influx and the need for model updates. We evaluate these models for generalizability against external adult and pediatric CXR datasets. We also propose novel ensemble methods: F-score-weighted Sequential Least-Squares Quadratic Programming (F-SLSQP) and Attention-Guided Ensembles with Learnable Fuzzy Softmax to aggregate weight parameters from multiple models to capitalize on their collective knowledge and complementary representations. We perform statistical significance tests with 95% confidence intervals and p-values to analyze model performance. Our evaluations indicate models initialized with ImageNet-pre-trained weights demonstrate superior generalizability over randomly initialized counterparts, contradicting some findings for non-medical images. Notably, ImageNet-pretrained models exhibit consistent performance during internal and external testing across different training scenarios. Weight-level ensembles of these models show significantly higher recall (p<0.05) during testing compared to individual models. Thus, our study accentuates the benefits of ImageNet-pretrained weight initialization, especially when used with weight-level ensembles, for creating robust and generalizable deep learning solutions.
Semantically Redundant Training Data Removal and Deep Model Classification Performance: A Study with Chest X-rays
Sep 18, 2023Deep learning (DL) has demonstrated its innate capacity to independently learn hierarchical features from complex and multi-dimensional data. A common understanding is that its performance scales up with the amount of training data. Another data attribute is the inherent variety. It follows, therefore, that semantic redundancy, which is the presence of similar or repetitive information, would tend to lower performance and limit generalizability to unseen data. In medical imaging data, semantic redundancy can occur due to the presence of multiple images that have highly similar presentations for the disease of interest. Further, the common use of augmentation methods to generate variety in DL training may be limiting performance when applied to semantically redundant data. We propose an entropy-based sample scoring approach to identify and remove semantically redundant training data. We demonstrate using the publicly available NIH chest X-ray dataset that the model trained on the resulting informative subset of training data significantly outperforms the model trained on the full training set, during both internal (recall: 0.7164 vs 0.6597, p<0.05) and external testing (recall: 0.3185 vs 0.2589, p<0.05). Our findings emphasize the importance of information-oriented training sample selection as opposed to the conventional practice of using all available training data.