 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-of-Distribution Detection and Data Drift Monitoring using Statistical Process Control
Feb 12, 2024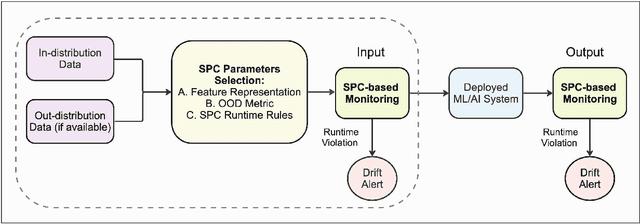

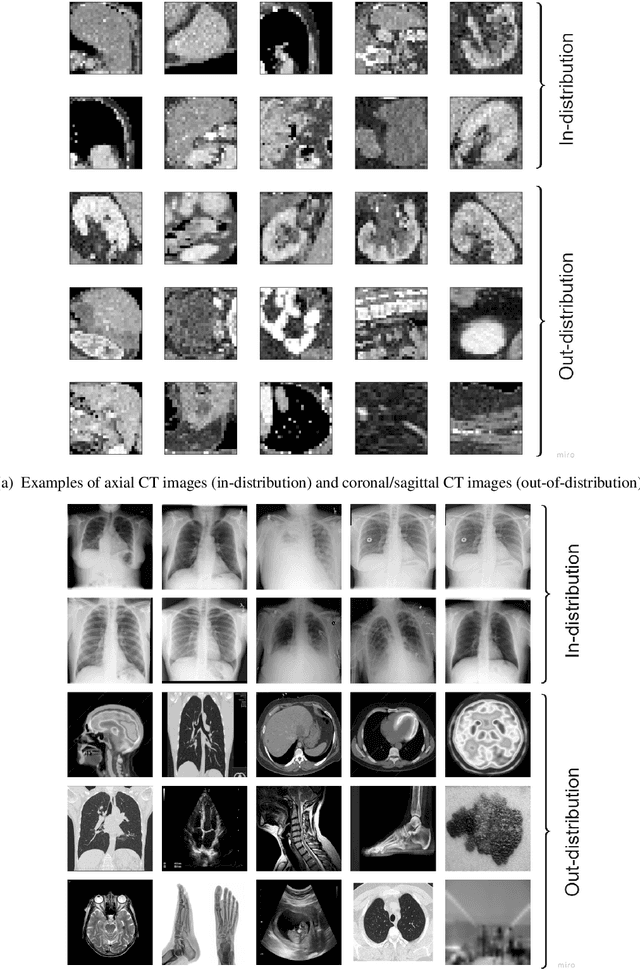

Background: Machine learning (ML) methods often fail with data that deviates from their training distribution. This is a significant concern for ML-enabled devices in clinical settings, where data drift may cause unexpected performance that jeopardizes patient safety. Method: We propose a ML-enabled Statistical Process Control (SPC) framework for out-of-distribution (OOD) detection and drift monitoring. SPC is advantageous as it visually and statistically highlights deviations from the expected distribution. To demonstrate the utility of the proposed framework for monitoring data drift in radiological images, we investigated different design choices, including methods for extracting feature representations, drift quantification, and SPC parameter selection. Results: We demonstrate the effectiveness of our framework for two tasks: 1) differentiating axial vs. non-axial computed tomography (CT) images and 2) separating chest x-ray (CXR) from other modalities. For both tasks, we achieved high accuracy in detecting OOD inputs, with 0.913 in CT and 0.995 in CXR, and sensitivity of 0.980 in CT and 0.984 in CXR. Our framework was also adept at monitoring data streams and identifying the time a drift occurred. In a simulation with 100 daily CXR cases, we detected a drift in OOD input percentage from 0-1% to 3-5% within two days, maintaining a low false-positive rate. Through additional experimental results, we demonstrate the framework's data-agnostic nature and independence from the underlying model's structure. Conclusion: We propose a framework for OOD detection and drift monitoring that is agnostic to data, modality, and model. The framework is customizable and can be adapted for specific applications.
Deep Distilling: automated code generation using explainable deep learning
Nov 16, 2021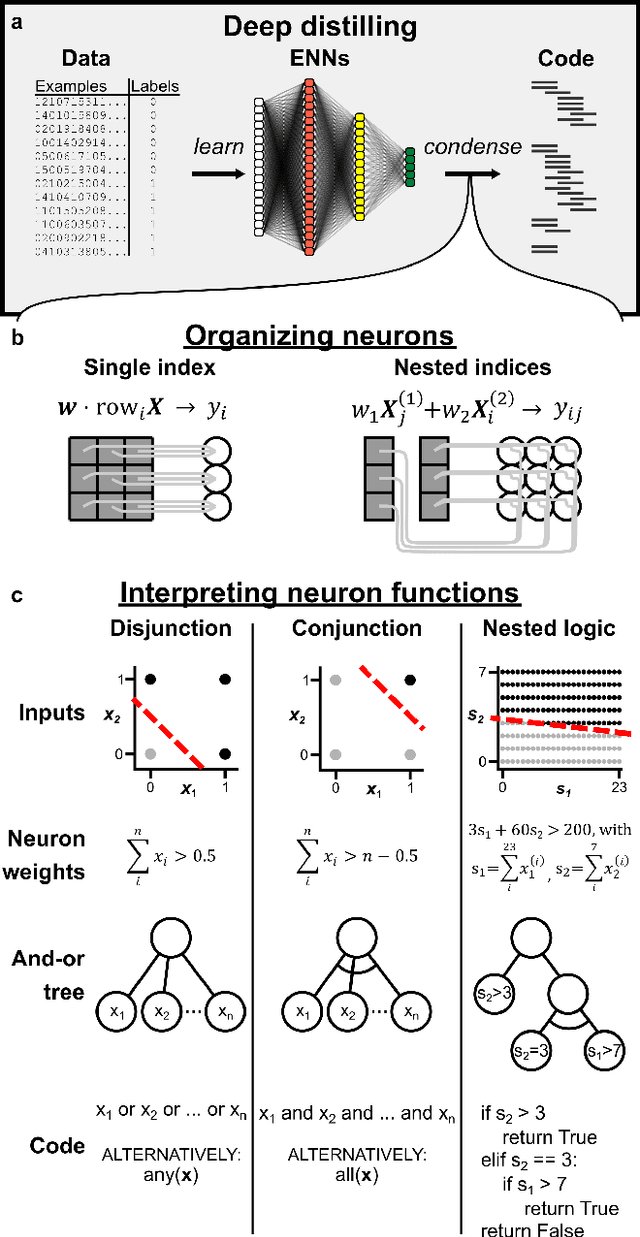
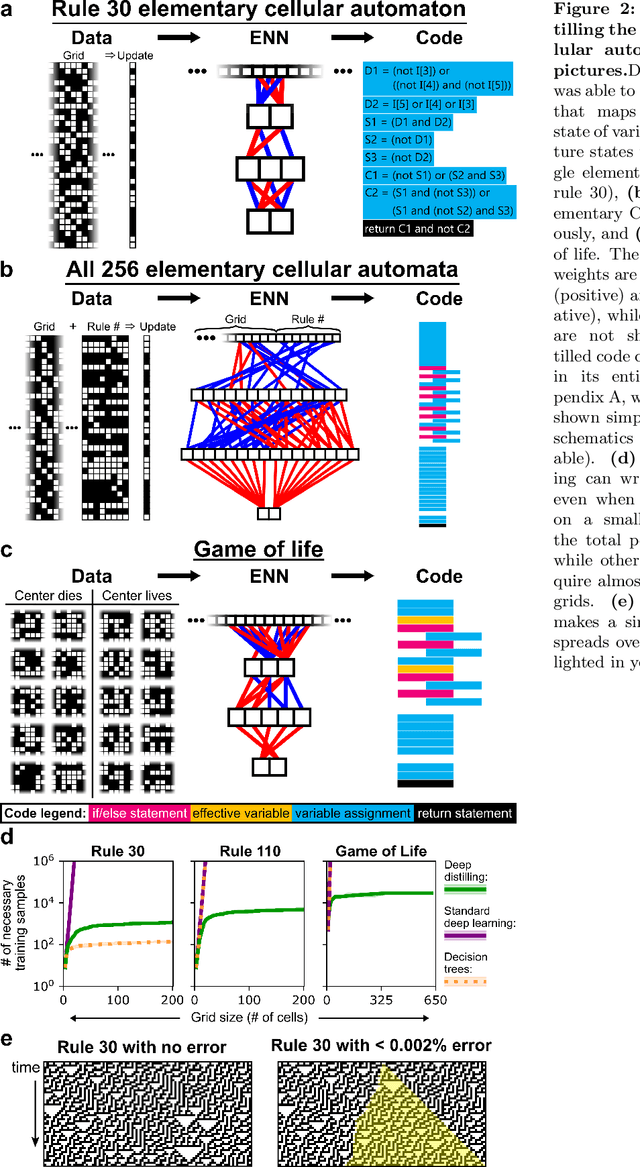
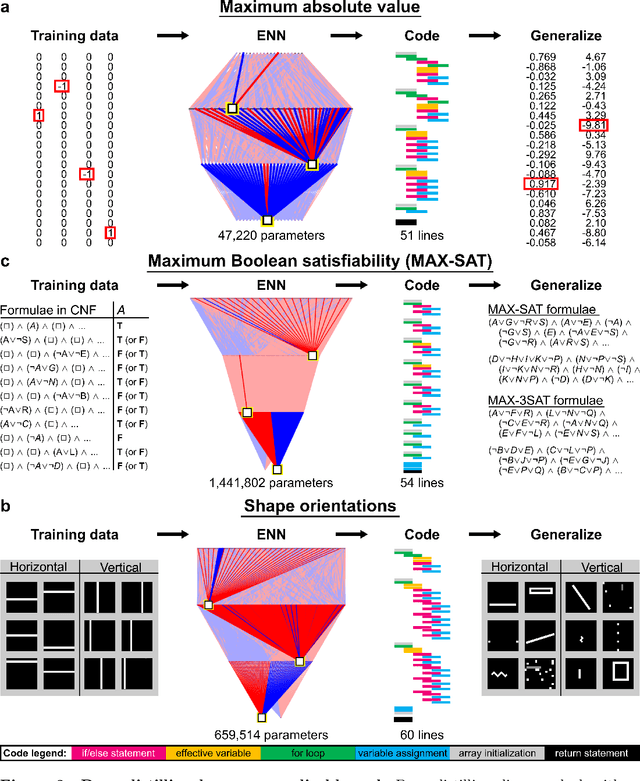
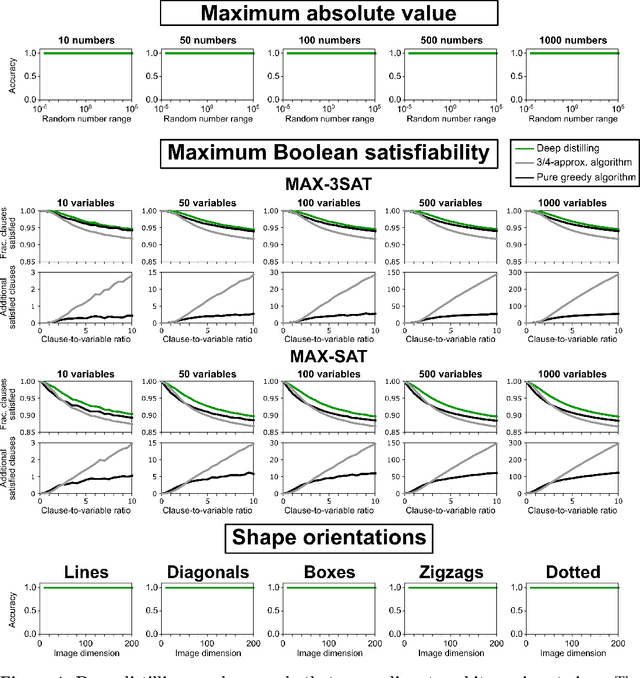
Human reasoning can distill principles from observed patterns and generalize them to explain and solve novel problems. The most powerful artificial intelligence systems lack explainability and symbolic reasoning ability, and have therefore not achieved supremacy in domains requiring human understanding, such as science or common sense reasoning. Here we introduce deep distilling, a machine learning method that learns patterns from data using explainable deep learning and then condenses it into concise, executable computer code. The code, which can contain loops, nested logical statements, and useful intermediate variables, is equivalent to the neural network but is generally orders of magnitude more compact and human-comprehensible. On a diverse set of problems involving arithmetic, computer vision, and optimization, we show that deep distilling generates concise code that generalizes out-of-distribution to solve problems orders-of-magnitude larger and more complex than the training data. For problems with a known ground-truth rule set, deep distilling discovers the rule set exactly with scalable guarantees. For problems that are ambiguous or computationally intractable, the distilled rules are similar to existing human-derived algorithms and perform at par or better. Our approach demonstrates that unassisted machine intelligence can build generalizable and intuitive rules explaining patterns in large datasets that would otherwise overwhelm human reasoning.