 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeS-SYNTH: Knowledge-Based, Synthetic Generation of Skin Images
Jul 31, 2024Development of artificial intelligence (AI) techniques in medical imaging requires access to large-scale and diverse datasets for training and evaluation. In dermatology, obtaining such datasets remains challenging due to significant variations in patient populations, illumination conditions, and acquisition system characteristics. In this work, we propose S-SYNTH, the first knowledge-based, adaptable open-source skin simulation framework to rapidly generate synthetic skin, 3D models and digitally rendered images, using an anatomically inspired multi-layer, multi-component skin and growing lesion model. The skin model allows for controlled variation in skin appearance, such as skin color, presence of hair, lesion shape, and blood fraction among other parameters. We use this framework to study the effect of possible variations on the development and evaluation of AI models for skin lesion segmentation, and show that results obtained using synthetic data follow similar comparative trends as real dermatologic images, while mitigating biases and limitations from existing datasets including small dataset size, lack of diversity, and underrepresentation.
Scorecards for Synthetic Medical Data Evaluation and Reporting
Jun 17, 2024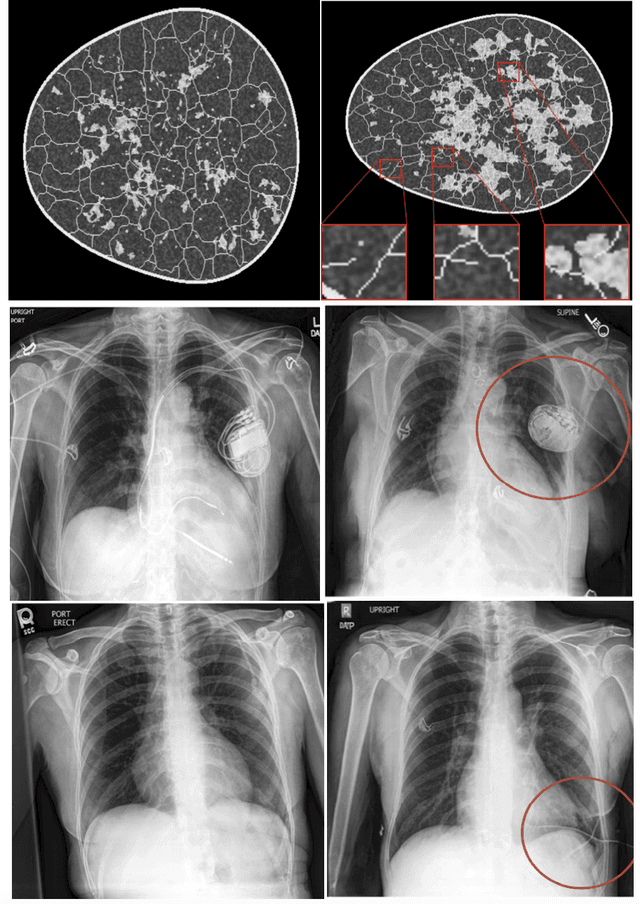
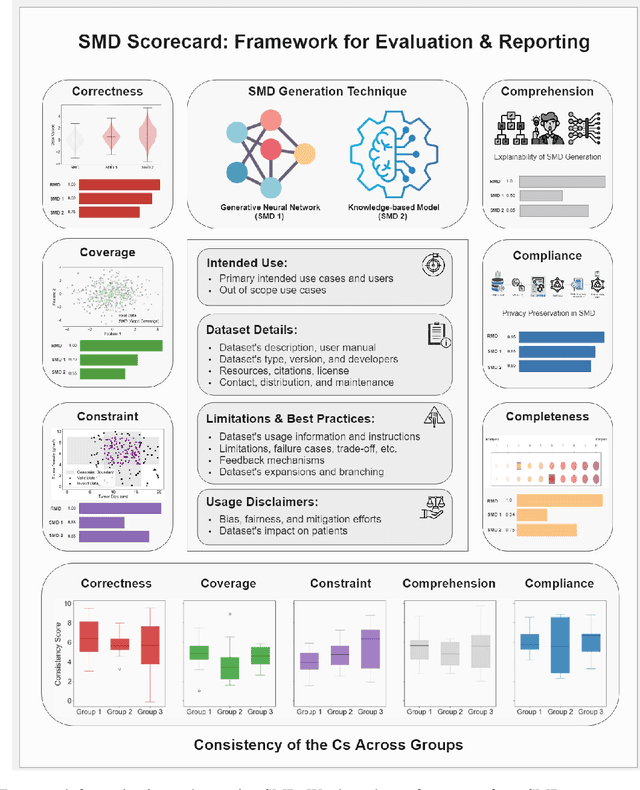
The growing utilization of synthetic medical data (SMD) in training and testing AI-driven tools in healthcare necessitates a systematic framework for assessing SMD quality. The current lack of a standardized methodology to evaluate SMD, particularly in terms of its applicability in various medical scenarios, is a significant hindrance to its broader acceptance and utilization in healthcare applications. Here, we outline an evaluation framework designed to meet the unique requirements of medical applications, and introduce the concept of SMD scorecards, which can serve as comprehensive reports that accompany artificially generated datasets. This can help standardize evaluation and enable SMD developers to assess and further enhance the quality of SMDs by identifying areas in need of attention and ensuring that the synthetic data more accurately approximate patient data.
Knowledge-based in silico models and dataset for the comparative evaluation of mammography AI for a range of breast characteristics, lesion conspicuities and doses
Oct 27, 2023



To generate evidence regarding the safety and efficacy of artificial intelligence (AI) enabled medical devices, AI models need to be evaluated on a diverse population of patient cases, some of which may not be readily available. We propose an evaluation approach for testing medical imaging AI models that relies on in silico imaging pipelines in which stochastic digital models of human anatomy (in object space) with and without pathology are imaged using a digital replica imaging acquisition system to generate realistic synthetic image datasets. Here, we release M-SYNTH, a dataset of cohorts with four breast fibroglandular density distributions imaged at different exposure levels using Monte Carlo x-ray simulations with the publicly available Virtual Imaging Clinical Trial for Regulatory Evaluation (VICTRE) toolkit. We utilize the synthetic dataset to analyze AI model performance and find that model performance decreases with increasing breast density and increases with higher mass density, as expected. As exposure levels decrease, AI model performance drops with the highest performance achieved at exposure levels lower than the nominal recommended dose for the breast type.
Spatial-frequency channels, shape bias, and adversarial robustness
Sep 22, 2023What spatial frequency information do humans and neural networks use to recognize objects? In neuroscience, critical band masking is an established tool that can reveal the frequency-selective filters used for object recognition. Critical band masking measures the sensitivity of recognition performance to noise added at each spatial frequency. Existing critical band masking studies show that humans recognize periodic patterns (gratings) and letters by means of a spatial-frequency filter (or "channel'') that has a frequency bandwidth of one octave (doubling of frequency). Here, we introduce critical band masking as a task for network-human comparison and test 14 humans and 76 neural networks on 16-way ImageNet categorization in the presence of narrowband noise. We find that humans recognize objects in natural images using the same one-octave-wide channel that they use for letters and gratings, making it a canonical feature of human object recognition. On the other hand, the neural network channel, across various architectures and training strategies, is 2-4 times as wide as the human channel. In other words, networks are vulnerable to high and low frequency noise that does not affect human performance. Adversarial and augmented-image training are commonly used to increase network robustness and shape bias. Does this training align network and human object recognition channels? Three network channel properties (bandwidth, center frequency, peak noise sensitivity) correlate strongly with shape bias (53% variance explained) and with robustness of adversarially-trained networks (74% variance explained). Adversarial training increases robustness but expands the channel bandwidth even further away from the human bandwidth. Thus, critical band masking reveals that the network channel is more than twice as wide as the human channel, and that adversarial training only increases this difference.
THMA: Tencent HD Map AI System for Creating HD Map Annotations
Dec 14, 2022Nowadays, autonomous vehicle technology is becoming more and more mature. Critical to progress and safety, high-definition (HD) maps, a type of centimeter-level map collected using a laser sensor, provide accurate descriptions of the surrounding environment. The key challenge of HD map production is efficient, high-quality collection and annotation of large-volume datasets. Due to the demand for high quality, HD map production requires significant manual human effort to create annotations, a very time-consuming and costly process for the map industry. In order to reduce manual annotation burdens, many artificial intelligence (AI) algorithms have been developed to pre-label the HD maps. However, there still exists a large gap between AI algorithms and the traditional manual HD map production pipelines in accuracy and robustness. Furthermore, it is also very resource-costly to build large-scale annotated datasets and advanced machine learning algorithms for AI-based HD map automatic labeling systems. In this paper, we introduce the Tencent HD Map AI (THMA) system, an innovative end-to-end, AI-based, active learning HD map labeling system capable of producing and labeling HD maps with a scale of hundreds of thousands of kilometers. In THMA, we train AI models directly from massive HD map datasets via supervised, self-supervised, and weakly supervised learning to achieve high accuracy and efficiency required by downstream users. THMA has been deployed by the Tencent Map team to provide services to downstream companies and users, serving over 1,000 labeling workers and producing more than 30,000 kilometers of HD map data per day at most. More than 90 percent of the HD map data in Tencent Map is labeled automatically by THMA, accelerating the traditional HD map labeling process by more than ten times.
ViTASD: Robust Vision Transformer Baselines for Autism Spectrum Disorder Facial Diagnosis
Oct 30, 2022



Autism spectrum disorder (ASD) is a lifelong neurodevelopmental disorder with very high prevalence around the world. Research progress in the field of ASD facial analysis in pediatric patients has been hindered due to a lack of well-established baselines. In this paper, we propose the use of the Vision Transformer (ViT) for the computational analysis of pediatric ASD. The presented model, known as ViTASD, distills knowledge from large facial expression datasets and offers model structure transferability. Specifically, ViTASD employs a vanilla ViT to extract features from patients' face images and adopts a lightweight decoder with a Gaussian Process layer to enhance the robustness for ASD analysis. Extensive experiments conducted on standard ASD facial analysis benchmarks show that our method outperforms all of the representative approaches in ASD facial analysis, while the ViTASD-L achieves a new state-of-the-art. Our code and pretrained models are available at https://github.com/IrohXu/ViTASD.
Improving Computed Tomography (CT) Reconstruction via 3D Shape Induction
Aug 23, 2022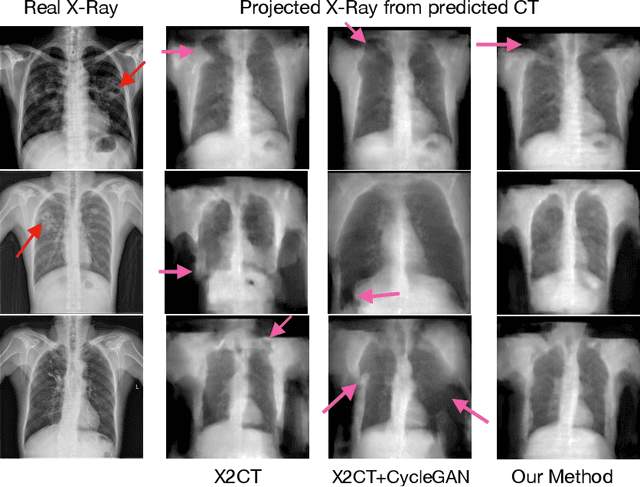

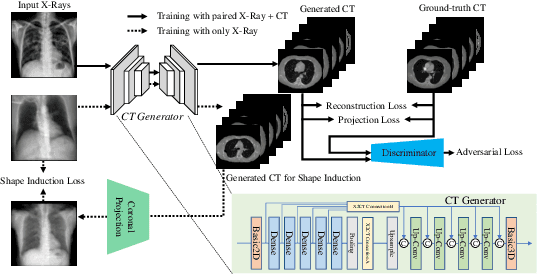

Chest computed tomography (CT) imaging adds valuable insight in the diagnosis and management of pulmonary infectious diseases, like tuberculosis (TB). However, due to the cost and resource limitations, only X-ray images may be available for initial diagnosis or follow up comparison imaging during treatment. Due to their projective nature, X-rays images may be more difficult to interpret by clinicians. The lack of publicly available paired X-ray and CT image datasets makes it challenging to train a 3D reconstruction model. In addition, Chest X-ray radiology may rely on different device modalities with varying image quality and there may be variation in underlying population disease spectrum that creates diversity in inputs. We propose shape induction, that is, learning the shape of 3D CT from X-ray without CT supervision, as a novel technique to incorporate realistic X-ray distributions during training of a reconstruction model. Our experiments demonstrate that this process improves both the perceptual quality of generated CT and the accuracy of down-stream classification of pulmonary infectious diseases.
CASS: Cross Architectural Self-Supervision for Medical Image Analysis
Jun 23, 2022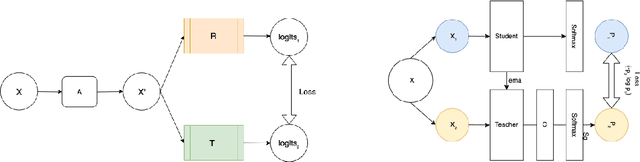
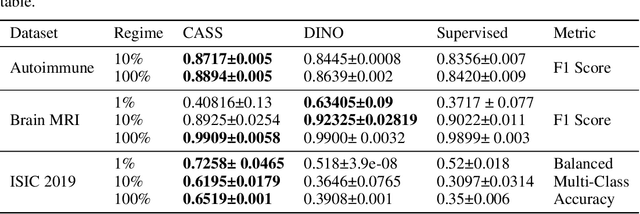


Recent advances in Deep Learning and Computer Vision have alleviated many of the bottlenecks, allowing algorithms to be label-free with better performance. Specifically, Transformers provide a global perspective of the image, which Convolutional Neural Networks (CNN) lack by design. Here we present Cross Architectural Self-Supervision, a novel self-supervised learning approach which leverages transformers and CNN simultaneously, while also being computationally accessible to general practitioners via easily available cloud services. Compared to existing state-of-the-art self-supervised learning approaches, we empirically show CASS trained CNNs, and Transformers gained an average of 8.5% with 100% labelled data, 7.3% with 10% labelled data, and 11.5% with 1% labelled data, across three diverse datasets. Notably, one of the employed datasets included histopathology slides of an autoimmune disease, a topic underrepresented in Medical Imaging and has minimal data. In addition, our findings reveal that CASS is twice as efficient as other state-of-the-art methods in terms of training time. The code is open source and is available on GitHub.
SATBench: Benchmarking the speed-accuracy tradeoff in object recognition by humans and dynamic neural networks
Jun 16, 2022
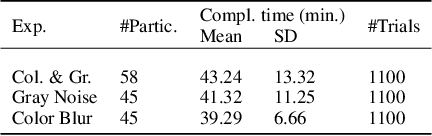
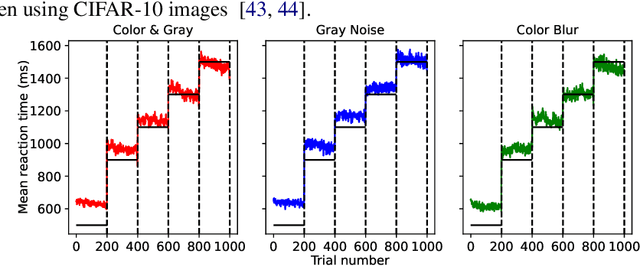
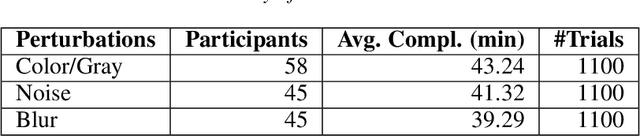
The core of everyday tasks like reading and driving is active object recognition. Attempts to model such tasks are currently stymied by the inability to incorporate time. People show a flexible tradeoff between speed and accuracy and this tradeoff is a crucial human skill. Deep neural networks have emerged as promising candidates for predicting peak human object recognition performance and neural activity. However, modeling the temporal dimension i.e., the speed-accuracy tradeoff (SAT), is essential for them to serve as useful computational models for how humans recognize objects. To this end, we here present the first large-scale (148 observers, 4 neural networks, 8 tasks) dataset of the speed-accuracy tradeoff (SAT) in recognizing ImageNet images. In each human trial, a beep, indicating the desired reaction time, sounds at a fixed delay after the image is presented, and observer's response counts only if it occurs near the time of the beep. In a series of blocks, we test many beep latencies, i.e., reaction times. We observe that human accuracy increases with reaction time and proceed to compare its characteristics with the behavior of several dynamic neural networks that are capable of inference-time adaptive computation. Using FLOPs as an analog for reaction time, we compare networks with humans on curve-fit error, category-wise correlation, and curve steepness, and conclude that cascaded dynamic neural networks are a promising model of human reaction time in object recognition tasks.
Semi-supervised Nonnegative Matrix Factorization for Document Classification
Feb 28, 2022

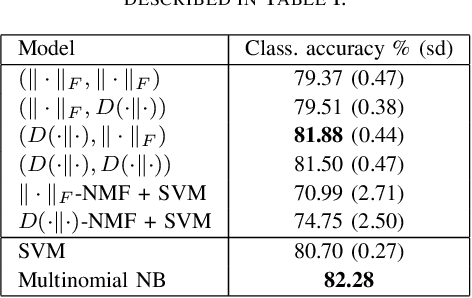

We propose new semi-supervised nonnegative matrix factorization (SSNMF) models for document classification and provide motivation for these models as maximum likelihood estimators. The proposed SSNMF models simultaneously provide both a topic model and a model for classification, thereby offering highly interpretable classification results. We derive training methods using multiplicative updates for each new model, and demonstrate the application of these models to single-label and multi-label document classification, although the models are flexible to other supervised learning tasks such as regression. We illustrate the promise of these models and training methods on document classification datasets (e.g., 20 Newsgroups, Reuters).