 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopo2Seq: Enhanced Topology Reasoning via Topology Sequence Learning
Feb 13, 2025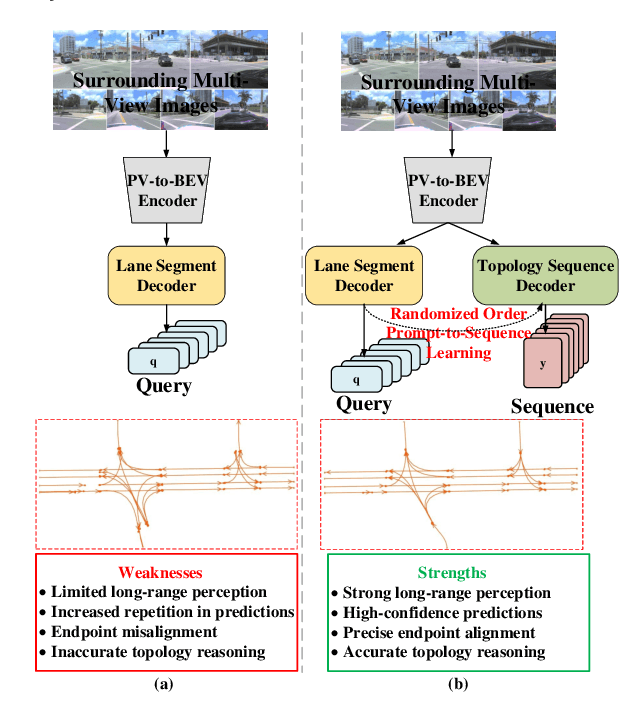
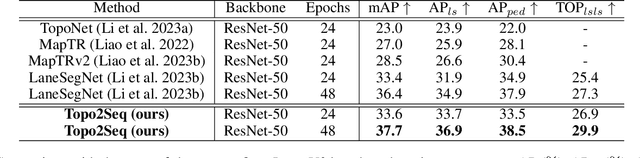
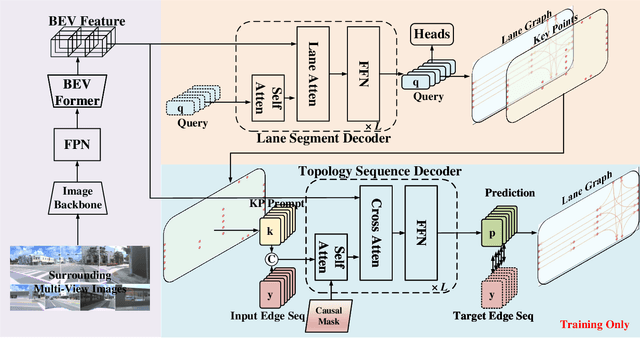
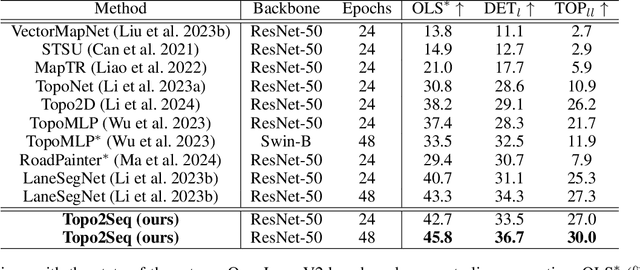
Extracting lane topology from perspective views (PV) is crucial for planning and control in autonomous driving. This approach extracts potential drivable trajectories for self-driving vehicles without relying on high-definition (HD) maps. However, the unordered nature and weak long-range perception of the DETR-like framework can result in misaligned segment endpoints and limited topological prediction capabilities. Inspired by the learning of contextual relationships in language models, the connectivity relations in roads can be characterized as explicit topology sequences. In this paper, we introduce Topo2Seq, a novel approach for enhancing topology reasoning via topology sequences learning. The core concept of Topo2Seq is a randomized order prompt-to-sequence learning between lane segment decoder and topology sequence decoder. The dual-decoder branches simultaneously learn the lane topology sequences extracted from the Directed Acyclic Graph (DAG) and the lane graph containing geometric information. Randomized order prompt-to-sequence learning extracts unordered key points from the lane graph predicted by the lane segment decoder, which are then fed into the prompt design of the topology sequence decoder to reconstruct an ordered and complete lane graph. In this way, the lane segment decoder learns powerful long-range perception and accurate topological reasoning from the topology sequence decoder. Notably, topology sequence decoder is only introduced during training and does not affect the inference efficiency. Experimental evaluations on the OpenLane-V2 dataset demonstrate the state-of-the-art performance of Topo2Seq in topology reasoning.
A Survey on Multimodal Large Language Models for Autonomous Driving
Nov 21, 2023


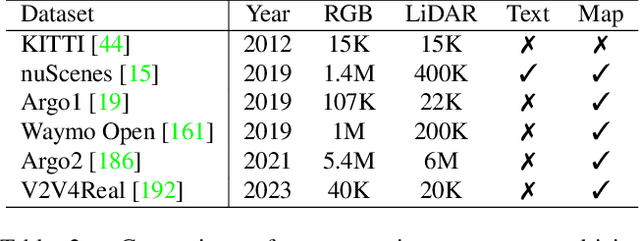
With the emergence of Large Language Models (LLMs) and Vision Foundation Models (VFMs), multimodal AI systems benefiting from large models have the potential to equally perceive the real world, make decisions, and control tools as humans. In recent months, LLMs have shown widespread attention in autonomous driving and map systems. Despite its immense potential, there is still a lack of a comprehensive understanding of key challenges, opportunities, and future endeavors to apply in LLM driving systems. In this paper, we present a systematic investigation in this field. We first introduce the background of Multimodal Large Language Models (MLLMs), the multimodal models development using LLMs, and the history of autonomous driving. Then, we overview existing MLLM tools for driving, transportation, and map systems together with existing datasets and benchmarks. Moreover, we summarized the works in The 1st WACV Workshop on Large Language and Vision Models for Autonomous Driving (LLVM-AD), which is the first workshop of its kind regarding LLMs in autonomous driving. To further promote the development of this field, we also discuss several important problems regarding using MLLMs in autonomous driving systems that need to be solved by both academia and industry.
Adaptive Landmark Color for AUV Docking in Visually Dynamic Environments
Oct 04, 2023



Autonomous Underwater Vehicles (AUVs) conduct missions underwater without the need for human intervention. A docking station (DS) can extend mission times of an AUV by providing a location for the AUV to recharge its batteries and receive updated mission information. Various methods for locating and tracking a DS exist, but most rely on expensive acoustic sensors, or are vision-based, which is significantly affected by water quality. In this \doctype, we present a vision-based method that utilizes adaptive color LED markers and dynamic color filtering to maximize landmark visibility in varying water conditions. Both AUV and DS utilize cameras to determine the water background color in order to calculate the desired marker color. No communication between AUV and DS is needed to determine marker color. Experiments conducted in a pool and lake show our method performs 10 times better than static color thresholding methods as background color varies. DS detection is possible at a range of 5 meters in clear water with minimal false positives.
THMA: Tencent HD Map AI System for Creating HD Map Annotations
Dec 14, 2022Nowadays, autonomous vehicle technology is becoming more and more mature. Critical to progress and safety, high-definition (HD) maps, a type of centimeter-level map collected using a laser sensor, provide accurate descriptions of the surrounding environment. The key challenge of HD map production is efficient, high-quality collection and annotation of large-volume datasets. Due to the demand for high quality, HD map production requires significant manual human effort to create annotations, a very time-consuming and costly process for the map industry. In order to reduce manual annotation burdens, many artificial intelligence (AI) algorithms have been developed to pre-label the HD maps. However, there still exists a large gap between AI algorithms and the traditional manual HD map production pipelines in accuracy and robustness. Furthermore, it is also very resource-costly to build large-scale annotated datasets and advanced machine learning algorithms for AI-based HD map automatic labeling systems. In this paper, we introduce the Tencent HD Map AI (THMA) system, an innovative end-to-end, AI-based, active learning HD map labeling system capable of producing and labeling HD maps with a scale of hundreds of thousands of kilometers. In THMA, we train AI models directly from massive HD map datasets via supervised, self-supervised, and weakly supervised learning to achieve high accuracy and efficiency required by downstream users. THMA has been deployed by the Tencent Map team to provide services to downstream companies and users, serving over 1,000 labeling workers and producing more than 30,000 kilometers of HD map data per day at most. More than 90 percent of the HD map data in Tencent Map is labeled automatically by THMA, accelerating the traditional HD map labeling process by more than ten times.