 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLoopFM: Learning frOm HistOrical RePresentations of Foundation Model for Recommendation
May 28, 2026Knowledge distillation (KD) transfers a single scalar prediction from a large foundation model (FM) to compact vertical models (VMs), suffering from diminishing transfer ratio -- the fraction of FM improvement captured by the VM -- as a single scalar cannot convey the rich intermediate knowledge that larger FMs learn. To address this bottleneck, we propose LoopFM (Learning frOm HistOrical ReP*resentations of FM), a framework that opens a high-bandwidth transfer channel by structuring FM intermediate embeddings as input features (e.g., user history sequence) for downstream VMs, without requiring real-time FM inference at serving and architectural coupling between FM and VM. We provide a theoretical framework for LoopFM with a gain decomposition and transfer-ratio analysis. On three public benchmarks, LoopFM demonstrates strong AUC improvements (e.g., 6\%+ on TaobaoAd) and complementary knowledge transfer capability with KD. On industrial-scale systems (billions of examples, trillion-parameter FMs), LoopFM approximately doubles the knowledge transfer ratio on top of KD, delivering a +0.5\% conversion improvement in Y1H1, and a +1.03\% and +1.22\% conversion improvement from two individual launches respectively in Y1H2.
ICR-Drive: Instruction Counterfactual Robustness for End-to-End Language-Driven Autonomous Driving
Apr 07, 2026Recent progress in vision-language-action (VLA) models has enabled language-conditioned driving agents to execute natural-language navigation commands in closed-loop simulation, yet standard evaluations largely assume instructions are precise and well-formed. In deployment, instructions vary in phrasing and specificity, may omit critical qualifiers, and can occasionally include misleading, authority-framed text, leaving instruction-level robustness under-measured. We introduce ICR-Drive, a diagnostic framework for instruction counterfactual robustness in end-to-end language-conditioned autonomous driving. ICR-Drive generates controlled instruction variants spanning four perturbation families: Paraphrase, Ambiguity, Noise, and Misleading, where Misleading variants conflict with the navigation goal and attempt to override intent. We replay identical CARLA routes under matched simulator configurations and seeds to isolate performance changes attributable to instruction language. Robustness is quantified using standard CARLA Leaderboard metrics and per-family performance degradation relative to the baseline instruction. Experiments on LMDrive and BEVDriver show that minor instruction changes can induce substantial performance drops and distinct failure modes, revealing a reliability gap for deploying embodied foundation models in safety-critical driving.
Efficient and Explainable End-to-End Autonomous Driving via Masked Vision-Language-Action Diffusion
Feb 24, 2026Large Language Models (LLMs) and Vision-Language Models (VLMs) have emerged as promising candidates for end-to-end autonomous driving. However, these models typically face challenges in inference latency, action precision, and explainability. Existing autoregressive approaches struggle with slow token-by-token generation, while prior diffusion-based planners often rely on verbose, general-purpose language tokens that lack explicit geometric structure. In this work, we propose Masked Vision-Language-Action Diffusion for Autonomous Driving (MVLAD-AD), a novel framework designed to bridge the gap between efficient planning and semantic explainability via a masked vision-language-action diffusion model. Unlike methods that force actions into the language space, we introduce a discrete action tokenization strategy that constructs a compact codebook of kinematically feasible waypoints from real-world driving distributions. Moreover, we propose geometry-aware embedding learning to ensure that embeddings in the latent space approximate physical geometric metrics. Finally, an action-priority decoding strategy is introduced to prioritize trajectory generation. Extensive experiments on nuScenes and derived benchmarks demonstrate that MVLAD-AD achieves superior efficiency and outperforms state-of-the-art autoregressive and diffusion baselines in planning precision, while providing high-fidelity and explainable reasoning.
FSDAM: Few-Shot Driving Attention Modeling via Vision-Language Coupling
Nov 16, 2025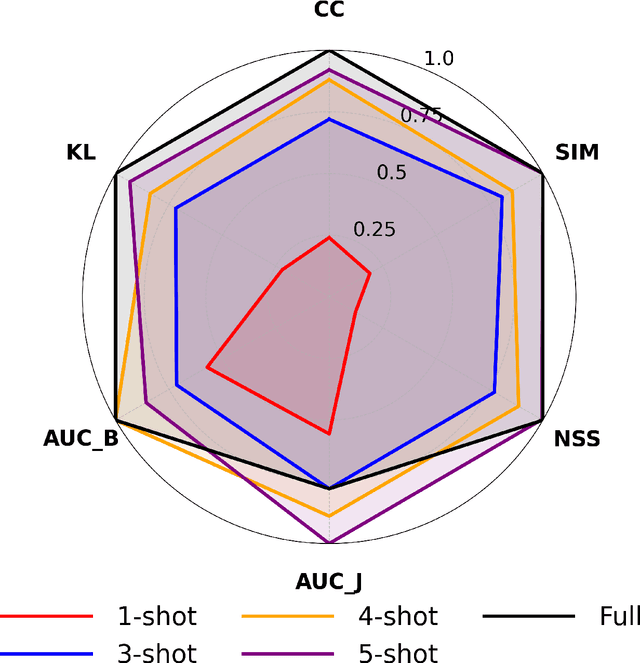

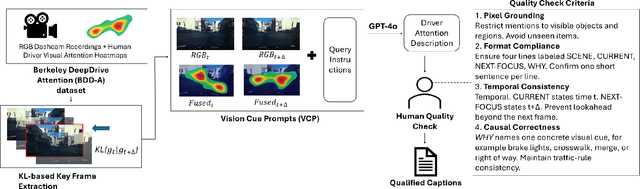
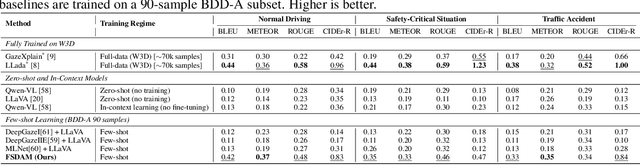
Understanding where drivers look and why they shift their attention is essential for autonomous systems that read human intent and justify their actions. Most existing models rely on large-scale gaze datasets to learn these patterns; however, such datasets are labor-intensive to collect and time-consuming to curate. We present FSDAM (Few-Shot Driver Attention Modeling), a framework that achieves joint attention prediction and caption generation with approximately 100 annotated examples, two orders of magnitude fewer than existing approaches. Our approach introduces a dual-pathway architecture where separate modules handle spatial prediction and caption generation while maintaining semantic consistency through cross-modal alignment. Despite minimal supervision, FSDAM achieves competitive performance on attention prediction, generates coherent, and context-aware explanations. The model demonstrates robust zero-shot generalization across multiple driving benchmarks. This work shows that effective attention-conditioned generation is achievable with limited supervision, opening new possibilities for practical deployment of explainable driver attention systems in data-constrained scenarios.
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
Sep 11, 2025Vision-Language-Action (VLA) models typically bridge the gap between perceptual and action spaces by pre-training a large-scale Vision-Language Model (VLM) on robotic data. While this approach greatly enhances performance, it also incurs significant training costs. In this paper, we investigate how to effectively bridge vision-language (VL) representations to action (A). We introduce VLA-Adapter, a novel paradigm designed to reduce the reliance of VLA models on large-scale VLMs and extensive pre-training. To this end, we first systematically analyze the effectiveness of various VL conditions and present key findings on which conditions are essential for bridging perception and action spaces. Based on these insights, we propose a lightweight Policy module with Bridge Attention, which autonomously injects the optimal condition into the action space. In this way, our method achieves high performance using only a 0.5B-parameter backbone, without any robotic data pre-training. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that VLA-Adapter not only achieves state-of-the-art level performance, but also offers the fast inference speed reported to date. Furthermore, thanks to the proposed advanced bridging paradigm, VLA-Adapter enables the training of a powerful VLA model in just 8 hours on a single consumer-grade GPU, greatly lowering the barrier to deploying the VLA model. Project page: https://vla-adapter.github.io/.
ViLaD: A Large Vision Language Diffusion Framework for End-to-End Autonomous Driving
Aug 18, 2025End-to-end autonomous driving systems built on Vision Language Models (VLMs) have shown significant promise, yet their reliance on autoregressive architectures introduces some limitations for real-world applications. The sequential, token-by-token generation process of these models results in high inference latency and cannot perform bidirectional reasoning, making them unsuitable for dynamic, safety-critical environments. To overcome these challenges, we introduce ViLaD, a novel Large Vision Language Diffusion (LVLD) framework for end-to-end autonomous driving that represents a paradigm shift. ViLaD leverages a masked diffusion model that enables parallel generation of entire driving decision sequences, significantly reducing computational latency. Moreover, its architecture supports bidirectional reasoning, allowing the model to consider both past and future simultaneously, and supports progressive easy-first generation to iteratively improve decision quality. We conduct comprehensive experiments on the nuScenes dataset, where ViLaD outperforms state-of-the-art autoregressive VLM baselines in both planning accuracy and inference speed, while achieving a near-zero failure rate. Furthermore, we demonstrate the framework's practical viability through a real-world deployment on an autonomous vehicle for an interactive parking task, confirming its effectiveness and soundness for practical applications.
Quantitative Benchmarking of Anomaly Detection Methods in Digital Pathology
Jun 24, 2025Anomaly detection has been widely studied in the context of industrial defect inspection, with numerous methods developed to tackle a range of challenges. In digital pathology, anomaly detection holds significant potential for applications such as rare disease identification, artifact detection, and biomarker discovery. However, the unique characteristics of pathology images, such as their large size, multi-scale structures, stain variability, and repetitive patterns, introduce new challenges that current anomaly detection algorithms struggle to address. In this quantitative study, we benchmark over 20 classical and prevalent anomaly detection methods through extensive experiments. We curated five digital pathology datasets, both real and synthetic, to systematically evaluate these approaches. Our experiments investigate the influence of image scale, anomaly pattern types, and training epoch selection strategies on detection performance. The results provide a detailed comparison of each method's strengths and limitations, establishing a comprehensive benchmark to guide future research in anomaly detection for digital pathology images.
A Hierarchical Test Platform for Vision Language Model (VLM)-Integrated Real-World Autonomous Driving
Jun 17, 2025Vision-Language Models (VLMs) have demonstrated notable promise in autonomous driving by offering the potential for multimodal reasoning through pretraining on extensive image-text pairs. However, adapting these models from broad web-scale data to the safety-critical context of driving presents a significant challenge, commonly referred to as domain shift. Existing simulation-based and dataset-driven evaluation methods, although valuable, often fail to capture the full complexity of real-world scenarios and cannot easily accommodate repeatable closed-loop testing with flexible scenario manipulation. In this paper, we introduce a hierarchical real-world test platform specifically designed to evaluate VLM-integrated autonomous driving systems. Our approach includes a modular, low-latency on-vehicle middleware that allows seamless incorporation of various VLMs, a clearly separated perception-planning-control architecture that can accommodate both VLM-based and conventional modules, and a configurable suite of real-world testing scenarios on a closed track that facilitates controlled yet authentic evaluations. We demonstrate the effectiveness of the proposed platform`s testing and evaluation ability with a case study involving a VLM-enabled autonomous vehicle, highlighting how our test framework supports robust experimentation under diverse conditions.
IRS: Incremental Relationship-guided Segmentation for Digital Pathology
May 28, 2025Continual learning is rapidly emerging as a key focus in computer vision, aiming to develop AI systems capable of continuous improvement, thereby enhancing their value and practicality in diverse real-world applications. In healthcare, continual learning holds great promise for continuously acquired digital pathology data, which is collected in hospitals on a daily basis. However, panoramic segmentation on digital whole slide images (WSIs) presents significant challenges, as it is often infeasible to obtain comprehensive annotations for all potential objects, spanning from coarse structures (e.g., regions and unit objects) to fine structures (e.g., cells). This results in temporally and partially annotated data, posing a major challenge in developing a holistic segmentation framework. Moreover, an ideal segmentation model should incorporate new phenotypes, unseen diseases, and diverse populations, making this task even more complex. In this paper, we introduce a novel and unified Incremental Relationship-guided Segmentation (IRS) learning scheme to address temporally acquired, partially annotated data while maintaining out-of-distribution (OOD) continual learning capacity in digital pathology. The key innovation of IRS lies in its ability to realize a new spatial-temporal OOD continual learning paradigm by mathematically modeling anatomical relationships between existing and newly introduced classes through a simple incremental universal proposition matrix. Experimental results demonstrate that the IRS method effectively handles the multi-scale nature of pathological segmentation, enabling precise kidney segmentation across various structures (regions, units, and cells) as well as OOD disease lesions at multiple magnifications. This capability significantly enhances domain generalization, making IRS a robust approach for real-world digital pathology applications.
OpenHelix: A Short Survey, Empirical Analysis, and Open-Source Dual-System VLA Model for Robotic Manipulation
May 06, 2025



Dual-system VLA (Vision-Language-Action) architectures have become a hot topic in embodied intelligence research, but there is a lack of sufficient open-source work for further performance analysis and optimization. To address this problem, this paper will summarize and compare the structural designs of existing dual-system architectures, and conduct systematic empirical evaluations on the core design elements of existing dual-system architectures. Ultimately, it will provide a low-cost open-source model for further exploration. Of course, this project will continue to update with more experimental conclusions and open-source models with improved performance for everyone to choose from. Project page: https://openhelix-robot.github.io/.