 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeViLaD: A Large Vision Language Diffusion Framework for End-to-End Autonomous Driving
Aug 18, 2025End-to-end autonomous driving systems built on Vision Language Models (VLMs) have shown significant promise, yet their reliance on autoregressive architectures introduces some limitations for real-world applications. The sequential, token-by-token generation process of these models results in high inference latency and cannot perform bidirectional reasoning, making them unsuitable for dynamic, safety-critical environments. To overcome these challenges, we introduce ViLaD, a novel Large Vision Language Diffusion (LVLD) framework for end-to-end autonomous driving that represents a paradigm shift. ViLaD leverages a masked diffusion model that enables parallel generation of entire driving decision sequences, significantly reducing computational latency. Moreover, its architecture supports bidirectional reasoning, allowing the model to consider both past and future simultaneously, and supports progressive easy-first generation to iteratively improve decision quality. We conduct comprehensive experiments on the nuScenes dataset, where ViLaD outperforms state-of-the-art autoregressive VLM baselines in both planning accuracy and inference speed, while achieving a near-zero failure rate. Furthermore, we demonstrate the framework's practical viability through a real-world deployment on an autonomous vehicle for an interactive parking task, confirming its effectiveness and soundness for practical applications.
NuPlanQA: A Large-Scale Dataset and Benchmark for Multi-View Driving Scene Understanding in Multi-Modal Large Language Models
Mar 17, 2025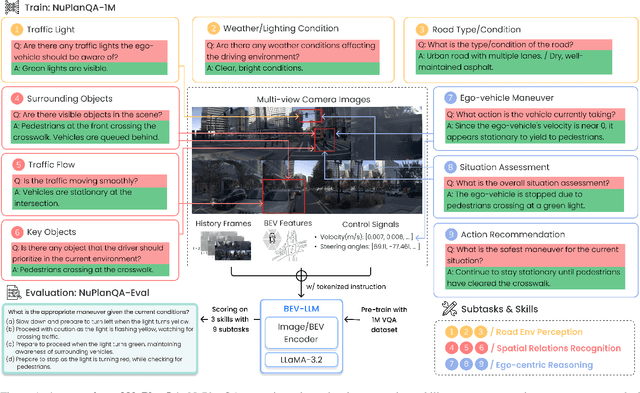
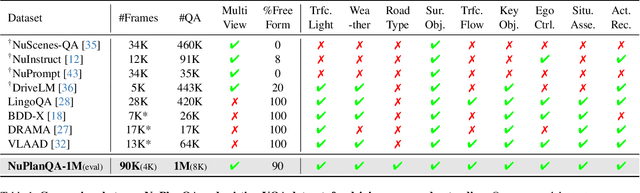
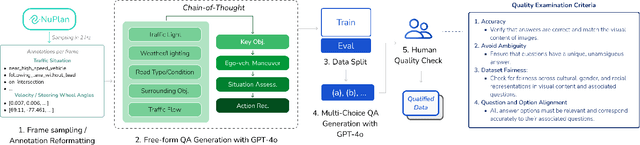
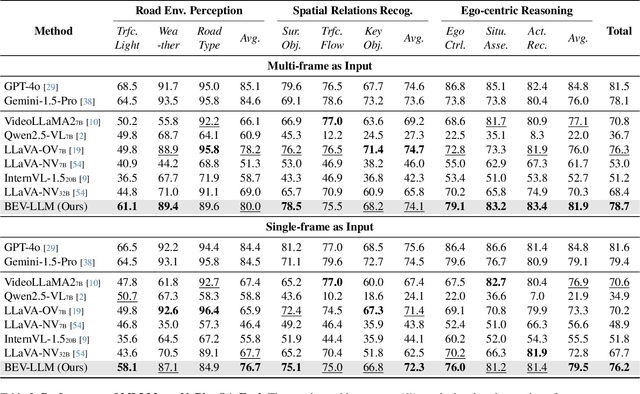
Recent advances in multi-modal large language models (MLLMs) have demonstrated strong performance across various domains; however, their ability to comprehend driving scenes remains less proven. The complexity of driving scenarios, which includes multi-view information, poses significant challenges for existing MLLMs. In this paper, we introduce NuPlanQA-Eval, a multi-view, multi-modal evaluation benchmark for driving scene understanding. To further support generalization to multi-view driving scenarios, we also propose NuPlanQA-1M, a large-scale dataset comprising 1M real-world visual question-answering (VQA) pairs. For context-aware analysis of traffic scenes, we categorize our dataset into nine subtasks across three core skills: Road Environment Perception, Spatial Relations Recognition, and Ego-Centric Reasoning. Furthermore, we present BEV-LLM, integrating Bird's-Eye-View (BEV) features from multi-view images into MLLMs. Our evaluation results reveal key challenges that existing MLLMs face in driving scene-specific perception and spatial reasoning from ego-centric perspectives. In contrast, BEV-LLM demonstrates remarkable adaptability to this domain, outperforming other models in six of the nine subtasks. These findings highlight how BEV integration enhances multi-view MLLMs while also identifying key areas that require further refinement for effective adaptation to driving scenes. To facilitate further research, we publicly release NuPlanQA at https://github.com/sungyeonparkk/NuPlanQA.
On-Board Vision-Language Models for Personalized Autonomous Vehicle Motion Control: System Design and Real-World Validation
Nov 17, 2024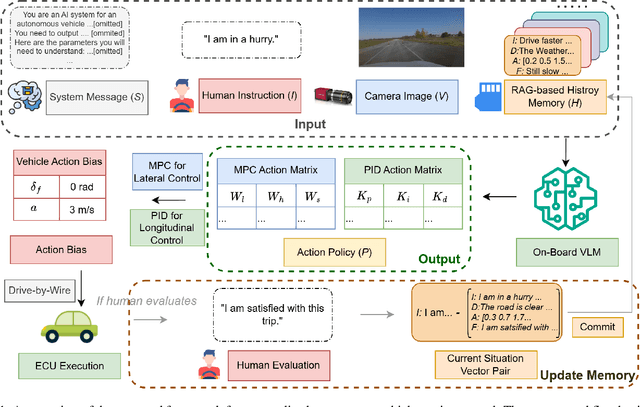
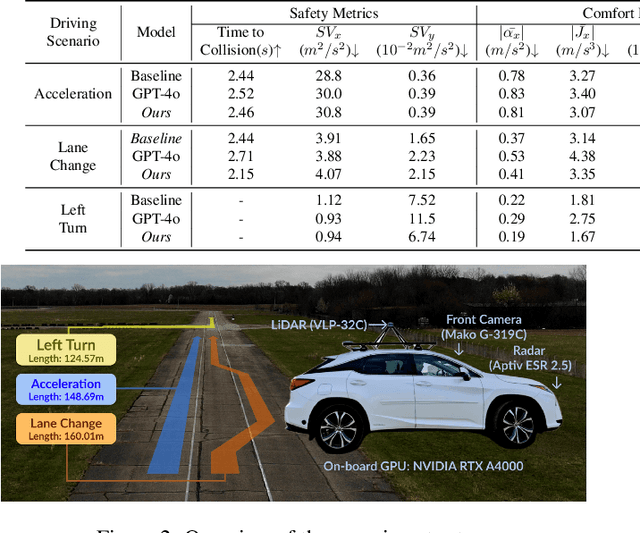

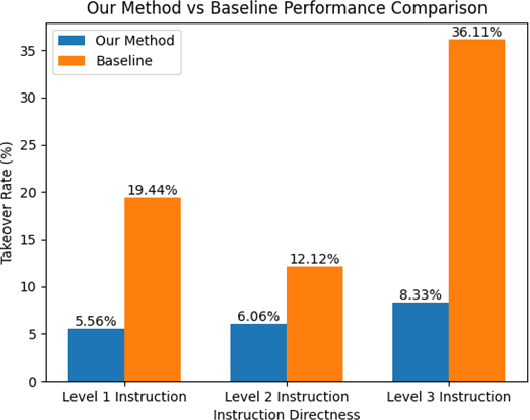
Personalized driving refers to an autonomous vehicle's ability to adapt its driving behavior or control strategies to match individual users' preferences and driving styles while maintaining safety and comfort standards. However, existing works either fail to capture every individual preference precisely or become computationally inefficient as the user base expands. Vision-Language Models (VLMs) offer promising solutions to this front through their natural language understanding and scene reasoning capabilities. In this work, we propose a lightweight yet effective on-board VLM framework that provides low-latency personalized driving performance while maintaining strong reasoning capabilities. Our solution incorporates a Retrieval-Augmented Generation (RAG)-based memory module that enables continuous learning of individual driving preferences through human feedback. Through comprehensive real-world vehicle deployment and experiments, our system has demonstrated the ability to provide safe, comfortable, and personalized driving experiences across various scenarios and significantly reduce takeover rates by up to 76.9%. To the best of our knowledge, this work represents the first end-to-end VLM-based motion control system in real-world autonomous vehicles.