 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuPlanQA: A Large-Scale Dataset and Benchmark for Multi-View Driving Scene Understanding in Multi-Modal Large Language Models
Paper and Code
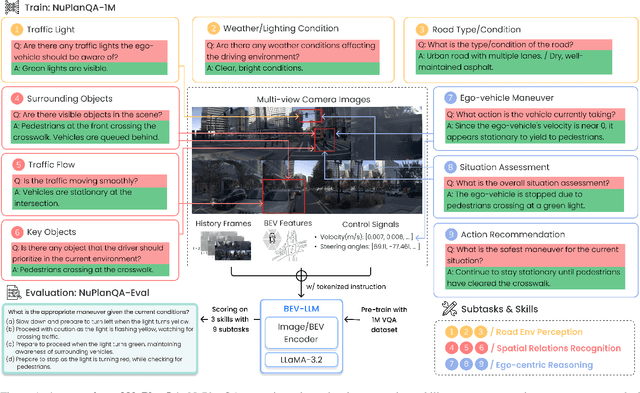
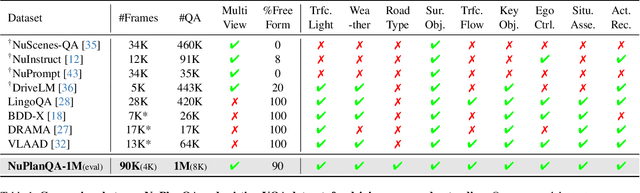
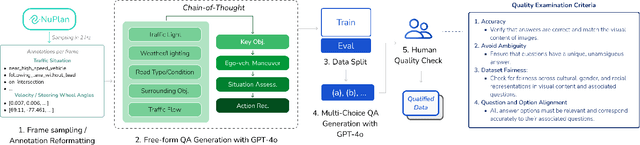
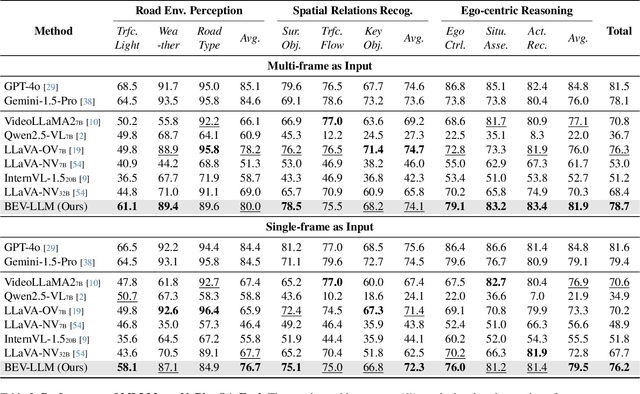
Recent advances in multi-modal large language models (MLLMs) have demonstrated strong performance across various domains; however, their ability to comprehend driving scenes remains less proven. The complexity of driving scenarios, which includes multi-view information, poses significant challenges for existing MLLMs. In this paper, we introduce NuPlanQA-Eval, a multi-view, multi-modal evaluation benchmark for driving scene understanding. To further support generalization to multi-view driving scenarios, we also propose NuPlanQA-1M, a large-scale dataset comprising 1M real-world visual question-answering (VQA) pairs. For context-aware analysis of traffic scenes, we categorize our dataset into nine subtasks across three core skills: Road Environment Perception, Spatial Relations Recognition, and Ego-Centric Reasoning. Furthermore, we present BEV-LLM, integrating Bird's-Eye-View (BEV) features from multi-view images into MLLMs. Our evaluation results reveal key challenges that existing MLLMs face in driving scene-specific perception and spatial reasoning from ego-centric perspectives. In contrast, BEV-LLM demonstrates remarkable adaptability to this domain, outperforming other models in six of the nine subtasks. These findings highlight how BEV integration enhances multi-view MLLMs while also identifying key areas that require further refinement for effective adaptation to driving scenes. To facilitate further research, we publicly release NuPlanQA at https://github.com/sungyeonparkk/NuPlanQA.