 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNuPlanQA: A Large-Scale Dataset and Benchmark for Multi-View Driving Scene Understanding in Multi-Modal Large Language Models
Mar 17, 2025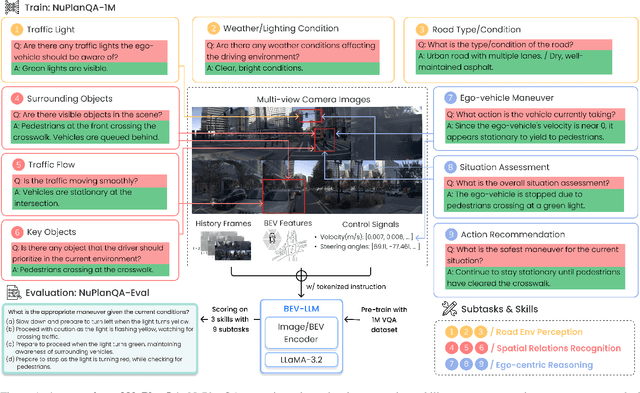
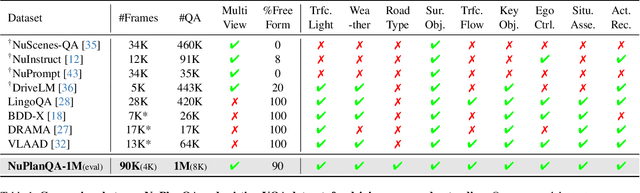
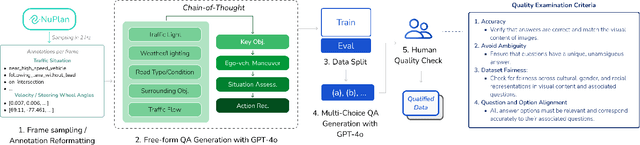
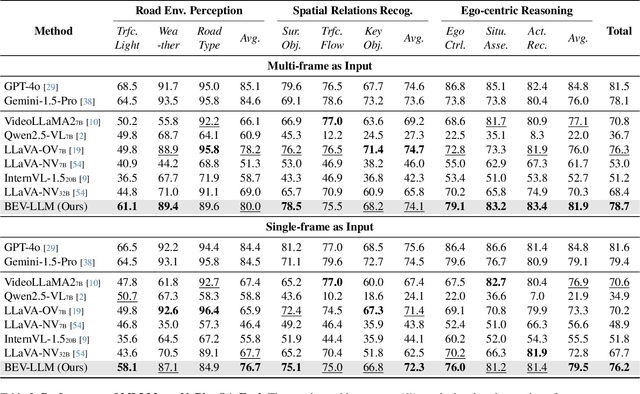
Recent advances in multi-modal large language models (MLLMs) have demonstrated strong performance across various domains; however, their ability to comprehend driving scenes remains less proven. The complexity of driving scenarios, which includes multi-view information, poses significant challenges for existing MLLMs. In this paper, we introduce NuPlanQA-Eval, a multi-view, multi-modal evaluation benchmark for driving scene understanding. To further support generalization to multi-view driving scenarios, we also propose NuPlanQA-1M, a large-scale dataset comprising 1M real-world visual question-answering (VQA) pairs. For context-aware analysis of traffic scenes, we categorize our dataset into nine subtasks across three core skills: Road Environment Perception, Spatial Relations Recognition, and Ego-Centric Reasoning. Furthermore, we present BEV-LLM, integrating Bird's-Eye-View (BEV) features from multi-view images into MLLMs. Our evaluation results reveal key challenges that existing MLLMs face in driving scene-specific perception and spatial reasoning from ego-centric perspectives. In contrast, BEV-LLM demonstrates remarkable adaptability to this domain, outperforming other models in six of the nine subtasks. These findings highlight how BEV integration enhances multi-view MLLMs while also identifying key areas that require further refinement for effective adaptation to driving scenes. To facilitate further research, we publicly release NuPlanQA at https://github.com/sungyeonparkk/NuPlanQA.
PDB: Not All Drivers Are the Same -- A Personalized Dataset for Understanding Driving Behavior
Mar 09, 2025
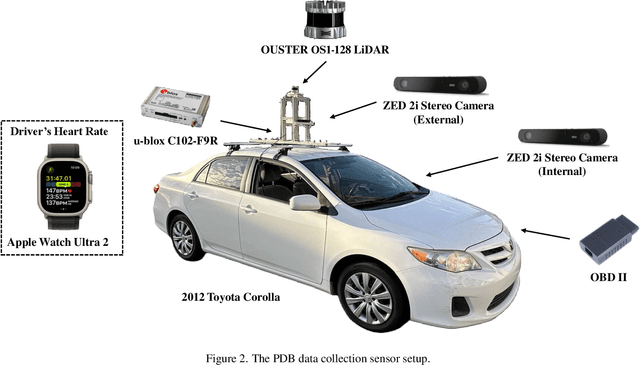
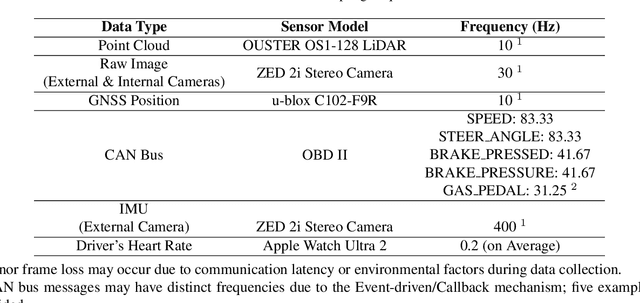
Driving behavior is inherently personal, influenced by individual habits, decision-making styles, and physiological states. However, most existing datasets treat all drivers as homogeneous, overlooking driver-specific variability. To address this gap, we introduce the Personalized Driving Behavior (PDB) dataset, a multi-modal dataset designed to capture personalization in driving behavior under naturalistic driving conditions. Unlike conventional datasets, PDB minimizes external influences by maintaining consistent routes, vehicles, and lighting conditions across sessions. It includes sources from 128-line LiDAR, front-facing camera video, GNSS, 9-axis IMU, CAN bus data (throttle, brake, steering angle), and driver-specific signals such as facial video and heart rate. The dataset features 12 participants, approximately 270,000 LiDAR frames, 1.6 million images, and 6.6 TB of raw sensor data. The processed trajectory dataset consists of 1,669 segments, each spanning 10 seconds with a 0.2-second interval. By explicitly capturing drivers' behavior, PDB serves as a unique resource for human factor analysis, driver identification, and personalized mobility applications, contributing to the development of human-centric intelligent transportation systems.
GreenAuto: An Automated Platform for Sustainable AI Model Design on Edge Devices
Jan 25, 2025
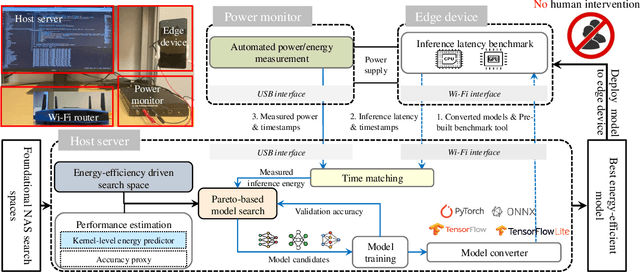
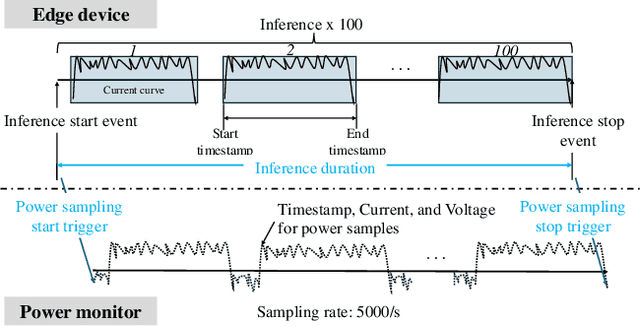
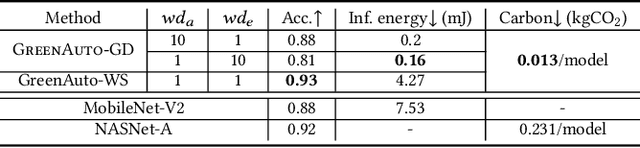
We present GreenAuto, an end-to-end automated platform designed for sustainable AI model exploration, generation, deployment, and evaluation. GreenAuto employs a Pareto front-based search method within an expanded neural architecture search (NAS) space, guided by gradient descent to optimize model exploration. Pre-trained kernel-level energy predictors estimate energy consumption across all models, providing a global view that directs the search toward more sustainable solutions. By automating performance measurements and iteratively refining the search process, GreenAuto demonstrates the efficient identification of sustainable AI models without the need for human intervention.
Video Token Sparsification for Efficient Multimodal LLMs in Autonomous Driving
Sep 16, 2024



Multimodal large language models (MLLMs) have demonstrated remarkable potential for enhancing scene understanding in autonomous driving systems through powerful logical reasoning capabilities. However, the deployment of these models faces significant challenges due to their substantial parameter sizes and computational demands, which often exceed the constraints of onboard computation. One major limitation arises from the large number of visual tokens required to capture fine-grained and long-context visual information, leading to increased latency and memory consumption. To address this issue, we propose Video Token Sparsification (VTS), a novel approach that leverages the inherent redundancy in consecutive video frames to significantly reduce the total number of visual tokens while preserving the most salient information. VTS employs a lightweight CNN-based proposal model to adaptively identify key frames and prune less informative tokens, effectively mitigating hallucinations and increasing inference throughput without compromising performance. We conduct comprehensive experiments on the DRAMA and LingoQA benchmarks, demonstrating the effectiveness of VTS in achieving up to a 33\% improvement in inference throughput and a 28\% reduction in memory usage compared to the baseline without compromising performance.
Investigating Personalized Driving Behaviors in Dilemma Zones: Analysis and Prediction of Stop-or-Go Decisions
May 06, 2024Dilemma zones at signalized intersections present a commonly occurring but unsolved challenge for both drivers and traffic operators. Onsets of the yellow lights prompt varied responses from different drivers: some may brake abruptly, compromising the ride comfort, while others may accelerate, increasing the risk of red-light violations and potential safety hazards. Such diversity in drivers' stop-or-go decisions may result from not only surrounding traffic conditions, but also personalized driving behaviors. To this end, identifying personalized driving behaviors and integrating them into advanced driver assistance systems (ADAS) to mitigate the dilemma zone problem presents an intriguing scientific question. In this study, we employ a game engine-based (i.e., CARLA-enabled) driving simulator to collect high-resolution vehicle trajectories, incoming traffic signal phase and timing information, and stop-or-go decisions from four subject drivers in various scenarios. This approach allows us to analyze personalized driving behaviors in dilemma zones and develop a Personalized Transformer Encoder to predict individual drivers' stop-or-go decisions. The results show that the Personalized Transformer Encoder improves the accuracy of predicting driver decision-making in the dilemma zone by 3.7% to 12.6% compared to the Generic Transformer Encoder, and by 16.8% to 21.6% over the binary logistic regression model.
KI-GAN: Knowledge-Informed Generative Adversarial Networks for Enhanced Multi-Vehicle Trajectory Forecasting at Signalized Intersections
Apr 19, 2024
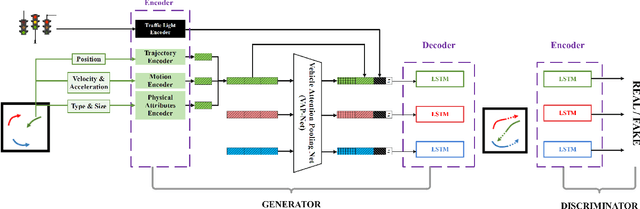


Reliable prediction of vehicle trajectories at signalized intersections is crucial to urban traffic management and autonomous driving systems. However, it presents unique challenges, due to the complex roadway layout at intersections, involvement of traffic signal controls, and interactions among different types of road users. To address these issues, we present in this paper a novel model called Knowledge-Informed Generative Adversarial Network (KI-GAN), which integrates both traffic signal information and multi-vehicle interactions to predict vehicle trajectories accurately. Additionally, we propose a specialized attention pooling method that accounts for vehicle orientation and proximity at intersections. Based on the SinD dataset, our KI-GAN model is able to achieve an Average Displacement Error (ADE) of 0.05 and a Final Displacement Error (FDE) of 0.12 for a 6-second observation and 6-second prediction cycle. When the prediction window is extended to 9 seconds, the ADE and FDE values are further reduced to 0.11 and 0.26, respectively. These results demonstrate the effectiveness of the proposed KI-GAN model in vehicle trajectory prediction under complex scenarios at signalized intersections, which represents a significant advancement in the target field.
LaMPilot: An Open Benchmark Dataset for Autonomous Driving with Language Model Programs
Dec 07, 2023We present LaMPilot, a novel framework for planning in the field of autonomous driving, rethinking the task as a code-generation process that leverages established behavioral primitives. This approach aims to address the challenge of interpreting and executing spontaneous user instructions such as "overtake the car ahead," which have typically posed difficulties for existing frameworks. We introduce the LaMPilot benchmark specifically designed to quantitatively evaluate the efficacy of Large Language Models (LLMs) in translating human directives into actionable driving policies. We then evaluate a wide range of state-of-the-art code generation language models on tasks from the LaMPilot Benchmark. The results of the experiments showed that GPT-4, with human feedback, achieved an impressive task completion rate of 92.7% and a minimal collision rate of 0.9%. To encourage further investigation in this area, our code and dataset will be made available.
Driving through the Concept Gridlock: Unraveling Explainability Bottlenecks in Automated Driving
Oct 26, 2023Concept bottleneck models have been successfully used for explainable machine learning by encoding information within the model with a set of human-defined concepts. In the context of human-assisted or autonomous driving, explainability models can help user acceptance and understanding of decisions made by the autonomous vehicle, which can be used to rationalize and explain driver or vehicle behavior. We propose a new approach using concept bottlenecks as visual features for control command predictions and explanations of user and vehicle behavior. We learn a human-understandable concept layer that we use to explain sequential driving scenes while learning vehicle control commands. This approach can then be used to determine whether a change in a preferred gap or steering commands from a human (or autonomous vehicle) is led by an external stimulus or change in preferences. We achieve competitive performance to latent visual features while gaining interpretability within our model setup.
Unveiling Energy Efficiency in Deep Learning: Measurement, Prediction, and Scoring across Edge Devices
Oct 19, 2023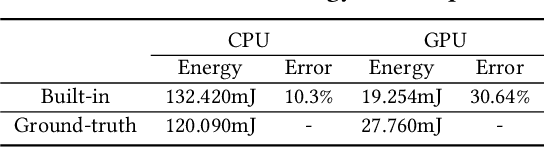

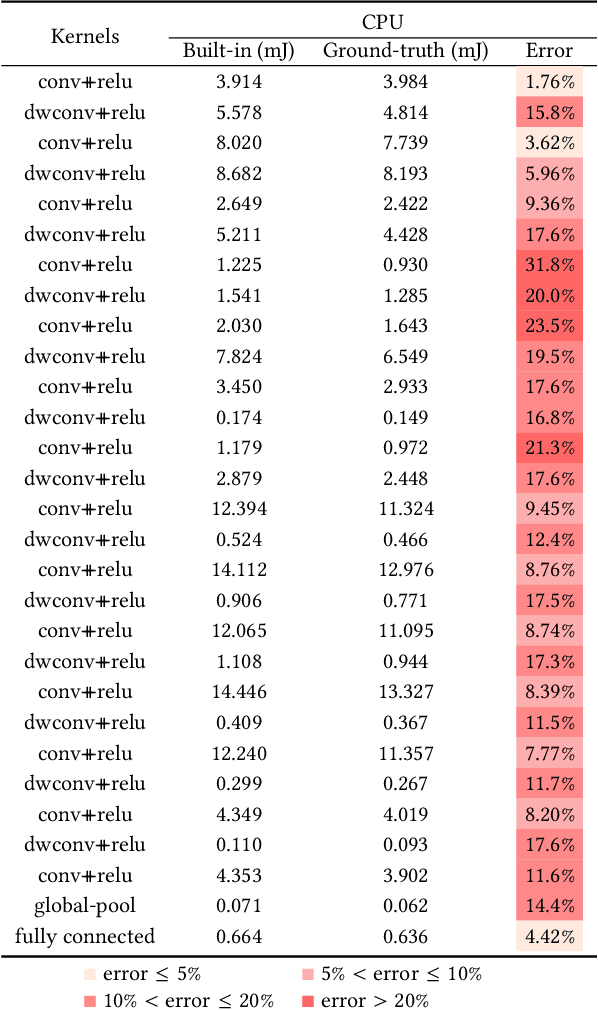
Today, deep learning optimization is primarily driven by research focused on achieving high inference accuracy and reducing latency. However, the energy efficiency aspect is often overlooked, possibly due to a lack of sustainability mindset in the field and the absence of a holistic energy dataset. In this paper, we conduct a threefold study, including energy measurement, prediction, and efficiency scoring, with an objective to foster transparency in power and energy consumption within deep learning across various edge devices. Firstly, we present a detailed, first-of-its-kind measurement study that uncovers the energy consumption characteristics of on-device deep learning. This study results in the creation of three extensive energy datasets for edge devices, covering a wide range of kernels, state-of-the-art DNN models, and popular AI applications. Secondly, we design and implement the first kernel-level energy predictors for edge devices based on our kernel-level energy dataset. Evaluation results demonstrate the ability of our predictors to provide consistent and accurate energy estimations on unseen DNN models. Lastly, we introduce two scoring metrics, PCS and IECS, developed to convert complex power and energy consumption data of an edge device into an easily understandable manner for edge device end-users. We hope our work can help shift the mindset of both end-users and the research community towards sustainability in edge computing, a principle that drives our research. Find data, code, and more up-to-date information at https://amai-gsu.github.io/DeepEn2023.
AdaMap: High-Scalable Real-Time Cooperative Perception at the Edge
Oct 03, 2023



Cooperative perception is the key approach to augment the perception of connected and automated vehicles (CAVs) toward safe autonomous driving. However, it is challenging to achieve real-time perception sharing for hundreds of CAVs in large-scale deployment scenarios. In this paper, we propose AdaMap, a new high-scalable real-time cooperative perception system, which achieves assured percentile end-to-end latency under time-varying network dynamics. To achieve AdaMap, we design a tightly coupled data plane and control plane. In the data plane, we design a new hybrid localization module to dynamically switch between object detection and tracking, and a novel point cloud representation module to adaptively compress and reconstruct the point cloud of detected objects. In the control plane, we design a new graph-based object selection method to un-select excessive multi-viewed point clouds of objects, and a novel approximated gradient descent algorithm to optimize the representation of point clouds. We implement AdaMap on an emulation platform, including realistic vehicle and server computation and a simulated 5G network, under a 150-CAV trace collected from the CARLA simulator. The evaluation results show that, AdaMap reduces up to 49x average transmission data size at the cost of 0.37 reconstruction loss, as compared to state-of-the-art solutions, which verifies its high scalability, adaptability, and computation efficiency.