 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMUSCLE: A Model Update Strategy for Compatible LLM Evolution
Jul 12, 2024



Large Language Models (LLMs) are frequently updated due to data or architecture changes to improve their performance. When updating models, developers often focus on increasing overall performance metrics with less emphasis on being compatible with previous model versions. However, users often build a mental model of the functionality and capabilities of a particular machine learning model they are interacting with. They have to adapt their mental model with every update -- a draining task that can lead to user dissatisfaction. In practice, fine-tuned downstream task adapters rely on pretrained LLM base models. When these base models are updated, these user-facing downstream task models experience instance regression or negative flips -- previously correct instances are now predicted incorrectly. This happens even when the downstream task training procedures remain identical. Our work aims to provide seamless model updates to a user in two ways. First, we provide evaluation metrics for a notion of compatibility to prior model versions, specifically for generative tasks but also applicable for discriminative tasks. We observe regression and inconsistencies between different model versions on a diverse set of tasks and model updates. Second, we propose a training strategy to minimize the number of inconsistencies in model updates, involving training of a compatibility model that can enhance task fine-tuned language models. We reduce negative flips -- instances where a prior model version was correct, but a new model incorrect -- by up to 40% from Llama 1 to Llama 2.
Cognitive Bias in High-Stakes Decision-Making with LLMs
Feb 25, 2024



Large language models (LLMs) offer significant potential as tools to support an expanding range of decision-making tasks. However, given their training on human (created) data, LLMs can inherit both societal biases against protected groups, as well as be subject to cognitive bias. Such human-like bias can impede fair and explainable decisions made with LLM assistance. Our work introduces BiasBuster, a framework designed to uncover, evaluate, and mitigate cognitive bias in LLMs, particularly in high-stakes decision-making tasks. Inspired by prior research in psychology and cognitive sciences, we develop a dataset containing 16,800 prompts to evaluate different cognitive biases (e.g., prompt-induced, sequential, inherent). We test various bias mitigation strategies, amidst proposing a novel method using LLMs to debias their own prompts. Our analysis provides a comprehensive picture on the presence and effects of cognitive bias across different commercial and open-source models. We demonstrate that our self-help debiasing effectively mitigate cognitive bias without having to manually craft examples for each bias type.
Driving through the Concept Gridlock: Unraveling Explainability Bottlenecks in Automated Driving
Oct 26, 2023Concept bottleneck models have been successfully used for explainable machine learning by encoding information within the model with a set of human-defined concepts. In the context of human-assisted or autonomous driving, explainability models can help user acceptance and understanding of decisions made by the autonomous vehicle, which can be used to rationalize and explain driver or vehicle behavior. We propose a new approach using concept bottlenecks as visual features for control command predictions and explanations of user and vehicle behavior. We learn a human-understandable concept layer that we use to explain sequential driving scenes while learning vehicle control commands. This approach can then be used to determine whether a change in a preferred gap or steering commands from a human (or autonomous vehicle) is led by an external stimulus or change in preferences. We achieve competitive performance to latent visual features while gaining interpretability within our model setup.
SpecTracle: Wearable Facial Motion Tracking from Unobtrusive Peripheral Cameras
Aug 14, 2023

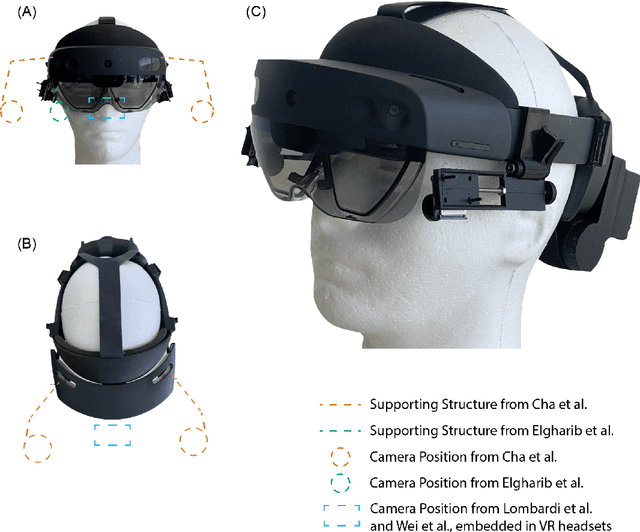
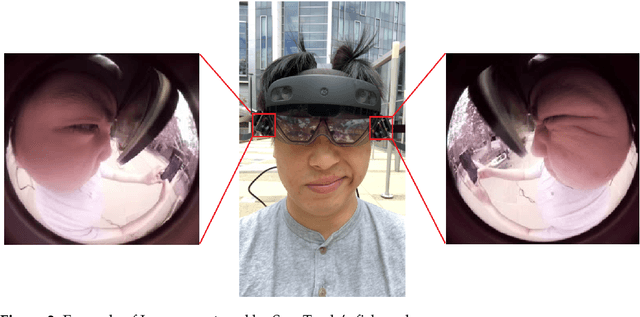
Facial motion tracking in head-mounted displays (HMD) has the potential to enable immersive "face-to-face" interaction in a virtual environment. However, current works on facial tracking are not suitable for unobtrusive augmented reality (AR) glasses or do not have the ability to track arbitrary facial movements. In this work, we demonstrate a novel system called SpecTracle that tracks a user's facial motions using two wide-angle cameras mounted right next to the visor of a Hololens. Avoiding the usage of cameras extended in front of the face, our system greatly improves the feasibility to integrate full-face tracking into a low-profile form factor. We also demonstrate that a neural network-based model processing the wide-angle cameras can run in real-time at 24 frames per second (fps) on a mobile GPU and track independent facial movement for different parts of the face with a user-independent model. Using a short personalized calibration, the system improves its tracking performance by 42.3% compared to the user-independent model.
Comparing Apples to Apples: Generating Aspect-Aware Comparative Sentences from User Reviews
Jul 23, 2023


It is time-consuming to find the best product among many similar alternatives. Comparative sentences can help to contrast one item from others in a way that highlights important features of an item that stand out. Given reviews of one or multiple items and relevant item features, we generate comparative review sentences to aid users to find the best fit. Specifically, our model consists of three successive components in a transformer: (i) an item encoding module to encode an item for comparison, (ii) a comparison generation module that generates comparative sentences in an autoregressive manner, (iii) a novel decoding method for user personalization. We show that our pipeline generates fluent and diverse comparative sentences. We run experiments on the relevance and fidelity of our generated sentences in a human evaluation study and find that our algorithm creates comparative review sentences that are relevant and truthful.